Workflow di machine learning
Modellazione con tidymodels in R

David Svancer
Data Scientist
Classificazione con alberi decisionali
Classificazione con alberi decisionali
Classificazione con alberi decisionali
Classificazione con alberi decisionali
Classificazione con alberi decisionali
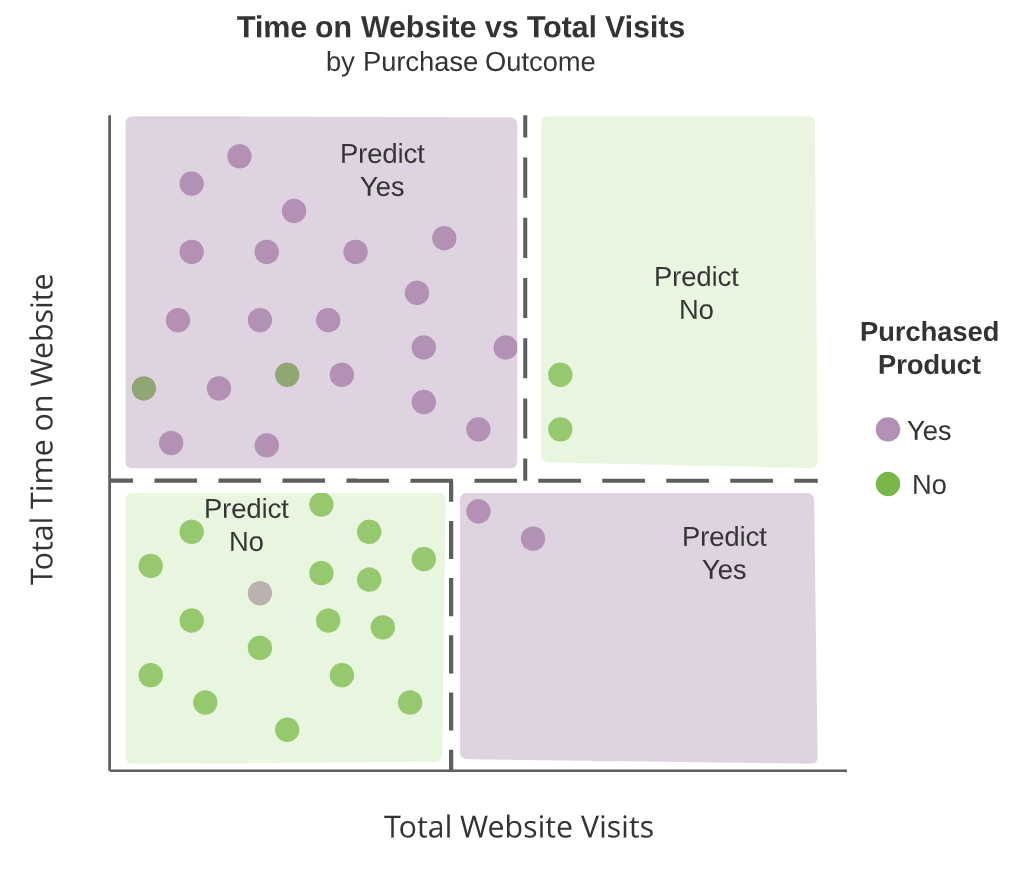
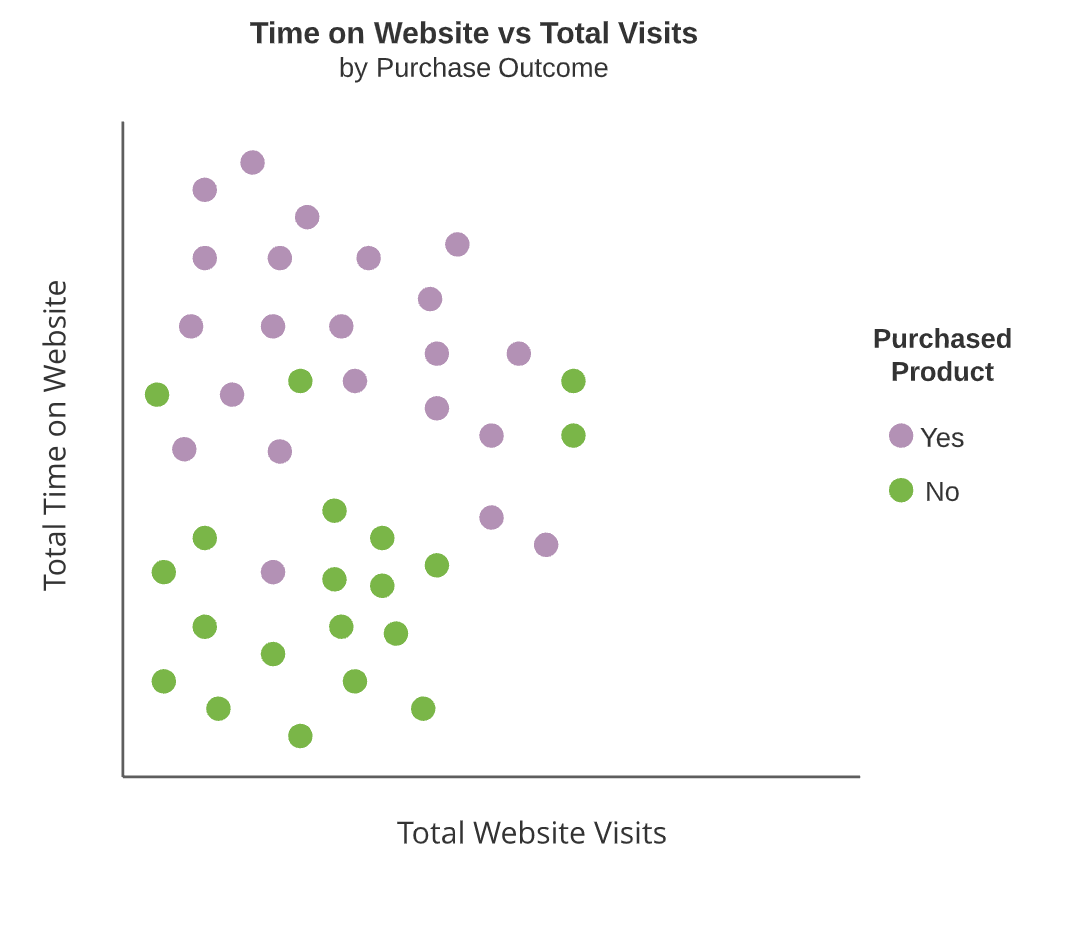
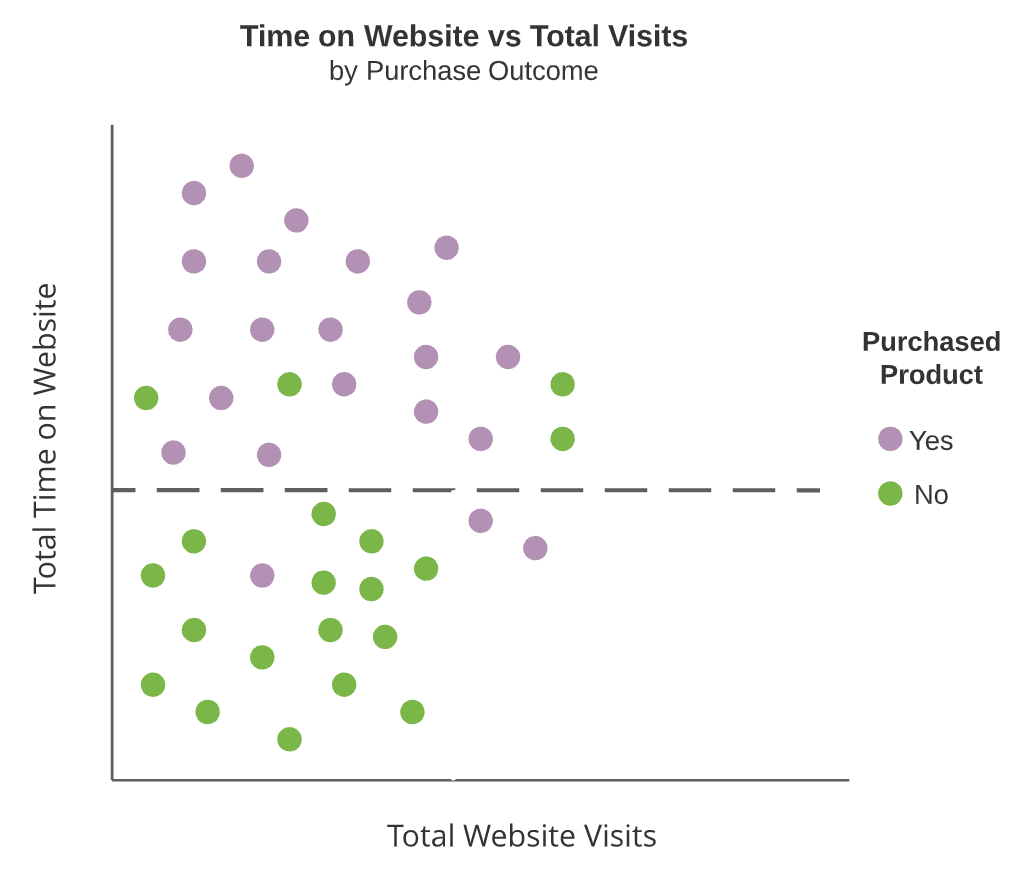
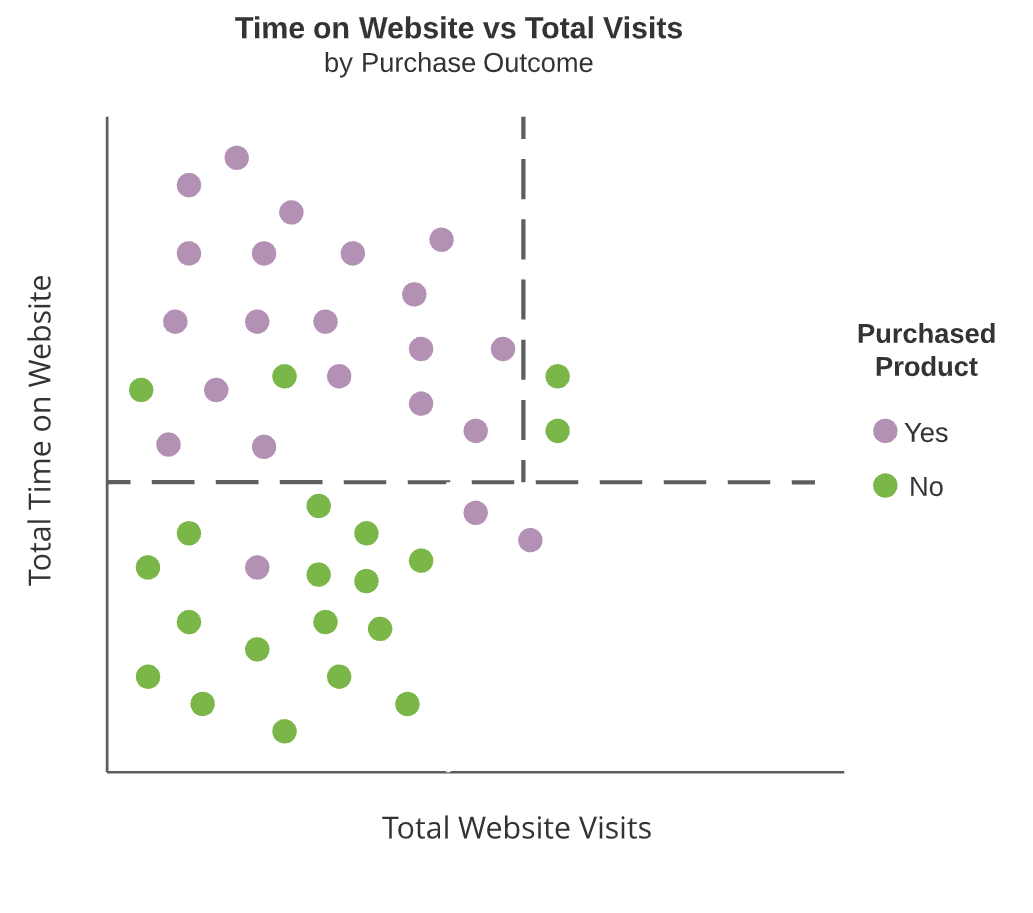
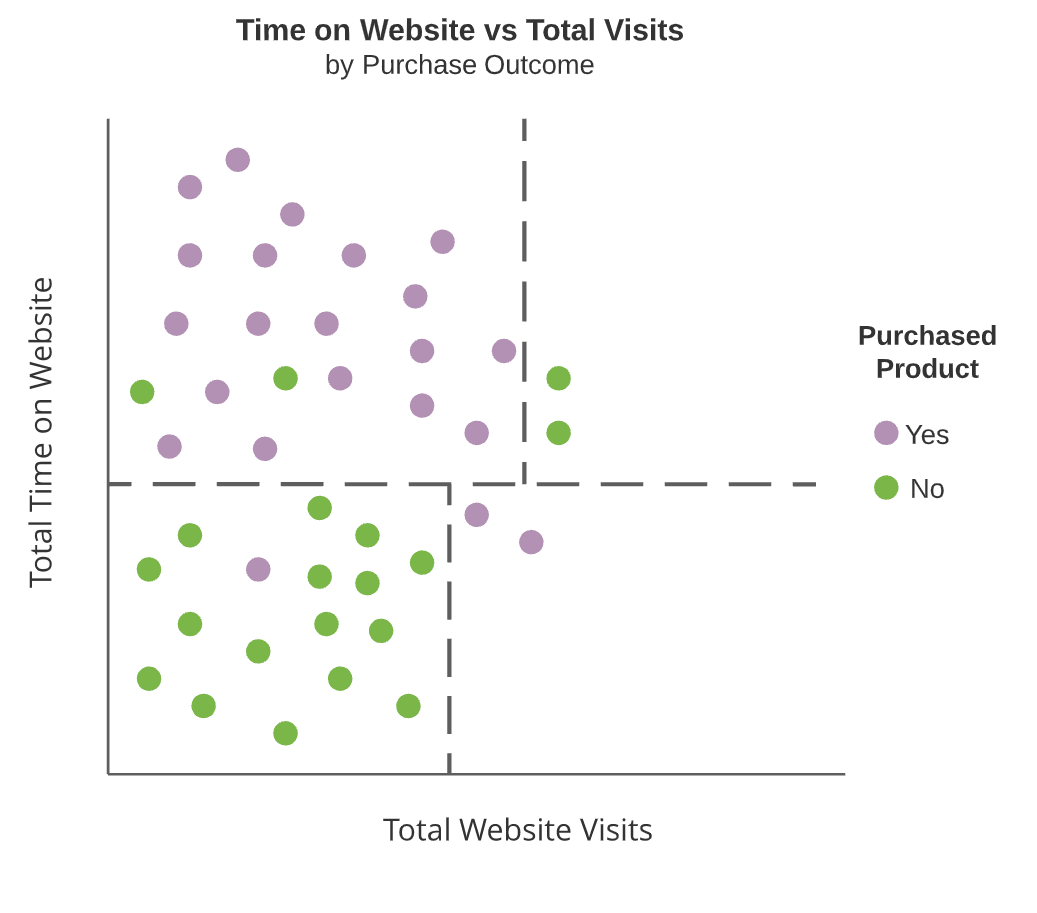
Diagrammi ad albero
- Nodi interni
- Split dell’albero (riquadri scuri)
- Nodi terminali
- Aree non ulteriormente suddivise
- Riquadri verdi e viola
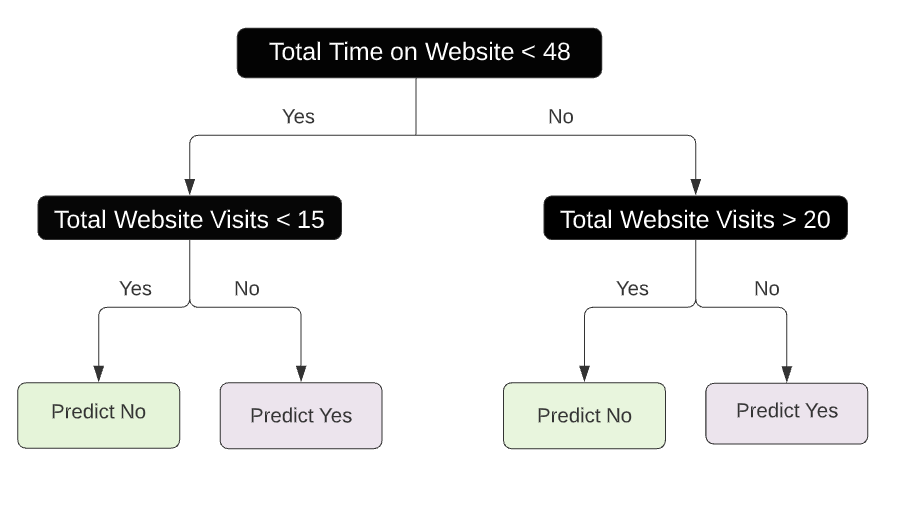
I nodi interni sono linee tratteggiate e i nodi terminali sono aree rettangolari evidenziate

