Modelli di classificazione
Modellazione con tidymodels in R

David Svancer
Data Scientist
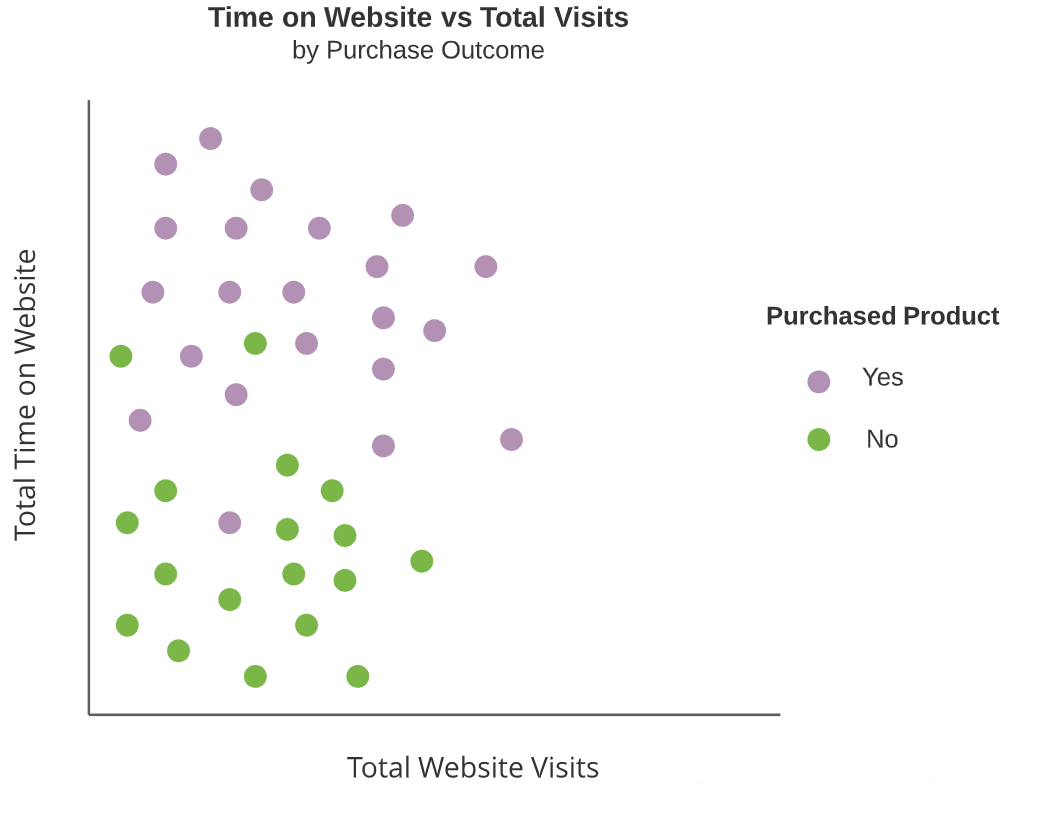
Prevedere gli acquisti di prodotto
I modelli di classificazione prevedono variabili di output categoriche
- Prevedere gli acquisti di prodotto
| purchased | total_time | total_visits |
|---|---|---|
| yes | 800 | 3 |
| yes | 978 | 7 |
| no | 220 | 4 |
| no | 124 | 5 |
| yes | 641 | 4 |
Algoritmi di classificazione
Obiettivo: creare regioni distinte e non sovrapposte sui valori dei predittori
- Predire la stessa categoria di outcome in ogni regione
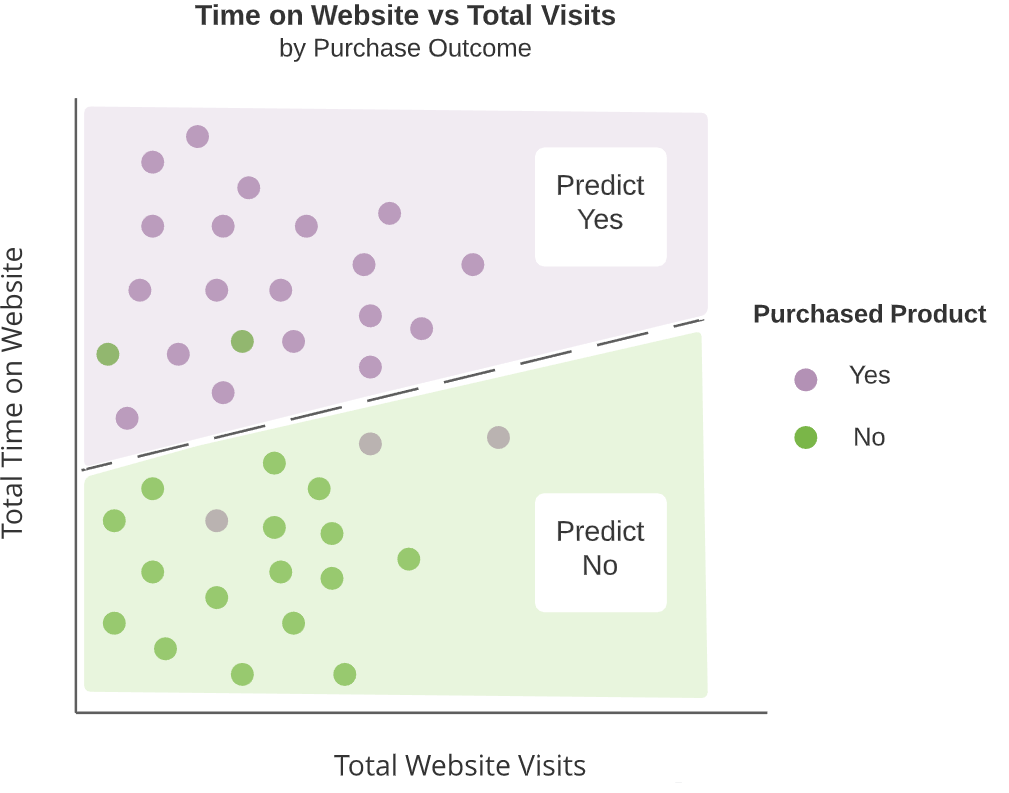
Algoritmi di classificazione
Obiettivo: creare regioni distinte e non sovrapposte sui valori dei predittori
- Predire la stessa categoria di outcome in ogni regione
Regressione logistica
- Algoritmo di classificazione diffuso che crea una separazione lineare tra le categorie
Dati per il lead scoring
leads_df
# A tibble: 1,328 x 7
purchased total_visits total_time pages_per_visit total_clicks lead_source us_location
<fct> <dbl> <dbl> <dbl> <dbl> <fct> <fct>
1 yes 7 1148 7 59 direct_traffic west
2 no 8 100 2.67 24 direct_traffic west
3 no 5 228 2.5 25 email southeast
4 no 7 481 2.33 21 organic_search west
5 no 4 177 4 37 direct_traffic west
6 no 2 1273 2 26 email midwest
7 no 3 711 3 28 organic_search west
8 no 3 166 3 32 direct_traffic southeast
9 no 3 7 3 23 organic_search west
10 no 6 562 6 48 organic_search southeast
# ... with 1,318 more rows
Campionamento dei dati
Primo passo per addestrare un modello
- Crea lo split dei dati con
initial_split() - Crea training e test set con
training()etesting()
leads_split <- initial_split(leads_df, prop = 0.75, strata = purchased)leads_training <- leads_split %>% training()leads_test <- leads_split %>% testing()
Specifiche della regressione logistica
Specificare il modello in parsnip
logistic_reg()- Interfaccia generale per la regressione logistica in
parsnip - Motore comune: 'glm'
- Modalità: 'classification'
- Interfaccia generale per la regressione logistica in
logistic_model <- logistic_reg() %>%set_engine('glm') %>%set_mode('classification')
Addestramento del modello
Dopo aver specificato il modello, usa fit() per l’addestramento
- Passa l’oggetto modello a
fit() - Specifica la formula
- Fornisci i dati di training,
data
logistic_fit <- logistic_model %>%fit(purchased ~ total_visits + total_time,data = leads_training)
Prevedere le categorie di outcome
La funzione predict()
new_dataindica i dati su cui prevederetype'class'restituisce previsioni categoriche
Output standard di predict()
- Restituisce una tibble
- Con
type = 'class', restituisce una colonna factor chiamata.pred_class
class_preds <- logistic_fit %>%predict(new_data = leads_test,type = 'class')class_preds
# A tibble: 332 x 1
.pred_class
<fct>
1 no
2 yes
3 no
4 no
5 yes
# ... with 327 more rows
Probabilità stimate
Impostando type a 'prob' ottieni le probabilità stimate per ogni categoria
predict() restituirà una tibble con più colonne
- Una per ogni categoria dell’outcome
- Convenzione:
.pred_{outcome_category}
prob_preds <- logistic_fit %>%
predict(new_data = leads_test,
type = 'prob')
prob_preds
# A tibble: 332 x 2
.pred_yes .pred_no
<dbl> <dbl>
1 0.134 0.866
2 0.729 0.271
3 0.133 0.867
4 0.0916 0.908
5 0.598 0.402
# ... with 327 more rows
Combinare i risultati
Per valutare il modello con yardstick serve una tibble di risultati
Puoi combinare la variabile di outcome del test set e le previsioni con bind_cols()
leads_results <- leads_test %>%
select(purchased) %>%
bind_cols(class_preds, prob_preds)
leads_results
# A tibble: 332 x 4
purchased .pred_class .pred_yes .pred_no
<fct> <fct> <dbl> <dbl>
1 no no 0.134 0.866
2 yes yes 0.729 0.271
3 no no 0.133 0.867
4 no no 0.0916 0.908
5 yes yes 0.598 0.402
# ... with 327 more rows
Dati di telecomunicazioni
telecom_df
# A tibble: 975 x 9
canceled_service cellular_service avg_data_gb avg_call_mins avg_intl_mins internet_service contract months_with_company monthly_charges
<fct> <fct> <dbl> <dbl> <dbl> <fct> <fct> <dbl> <dbl>
1 yes single_line 7.78 497 127 fiber_optic month_to_month 7 76.4
2 yes single_line 9.04 336 88 fiber_optic month_to_month 10 94.9
3 no single_line 10.3 262 55 fiber_optic one_year 50 103.
4 yes multiple_lines 5.08 250 107 digital one_year 53 60.0
5 no multiple_lines 8.05 328 122 digital two_year 50 75.2
6 no single_line 9.3 326 114 fiber_optic month_to_month 25 95.7
7 yes multiple_lines 8.01 525 97 fiber_optic month_to_month 19 83.6
8 no multiple_lines 9.4 312 147 fiber_optic one_year 50 99.4
9 yes single_line 5.29 417 96 digital month_to_month 8 49.8
10 no multiple_lines 9.96 340 136 fiber_optic month_to_month 61 106.
# ... with 965 more rows
Passons à la pratique !
Modellazione con tidymodels in R

