Scelta delle distribuzioni di probabilità
Simulazioni Monte Carlo in Python

Izzy Weber
Curriculum Manager, DataCamp
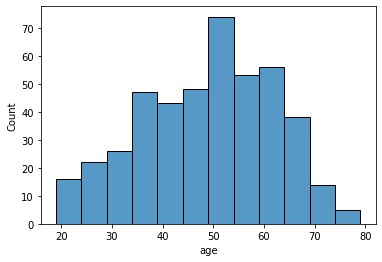
Scelta di una distribuzione per la variabile age
sns.histplot(dia["age"])
Distribuzioni candidate
distributions = [st.laplace, st.norm, st.expon]