Identificare le regole di associazione
Analisi del carrello in Python

Isaiah Hull
Visiting Associate Professor of Finance, BI Norwegian Business School
Caricare e preparare i dati
import pandas as pd
# Load transactions from pandas.
books = pd.read_csv("datasets/bookstore.csv")
# Split transaction strings into lists.
transactions = books['Transaction'].apply(lambda t: t.split(','))
# Convert DataFrame into list of strings.
transactions = list(transactions)
Esplorare i dati
print(transactions[:5])
[['language', 'travel', 'humor', 'fiction'],
['humor', 'language'],
['humor', 'biography', 'cooking'],
['cooking', 'language'],
['travel']]
Regole di associazione
Regola di associazione
- Contiene antecedente e conseguente
- {health} $\rightarrow$ {cooking}
- Contiene antecedente e conseguente
Regola con più antecedenti
- {humor, travel} $\rightarrow$ {language}
Regola con più conseguenti
- {biography} $\rightarrow$ {history, language}
Difficoltà nella selezione delle regole
Trovare buone regole è difficile.
- Lo spazio di tutte le regole è grande.
- La maggior parte non è utile.
- Bisogna scartarne molte.
E se ci limitassimo a regole semplici?
- Un antecedente e un conseguente.
- È ancora impegnativo, anche con dataset piccoli.
Generare le regole
- narrativa
- poesia
- storia
- biografia
- cucina
- salute
- viaggi
- lingue
- umorismo
Generare le regole
| Regole narrativa | Regole poesia | ... | Regole umorismo |
|---|---|---|---|
| narrativa->poesia | poesia->narrativa | ... | umorismo->narrativa |
| narrativa->storia | poesia->storia | ... | umorismo->storia |
| narrativa->biografia | poesia->biografia | ... | umorismo->biografia |
| narrativa->cucina | poesia->cucina | ... | umorismo->cucina |
| ... | ... | ... | ... |
| narrativa->umorismo | poesia->umorismo | ... |
Generare regole con itertools
from itertools import permutations
# Extract unique items.
flattened = [item for transaction in transactions for item in transaction]
items = list(set(flattened))
# Compute and print rules.
rules = list(permutations(items, 2))
print(rules)
[('fiction', 'poetry'),
('fiction', 'history'),
...
('humor', 'travel'),
('humor', 'language')]
Contare le regole
# Print the number of rules
print(len(rules))
72
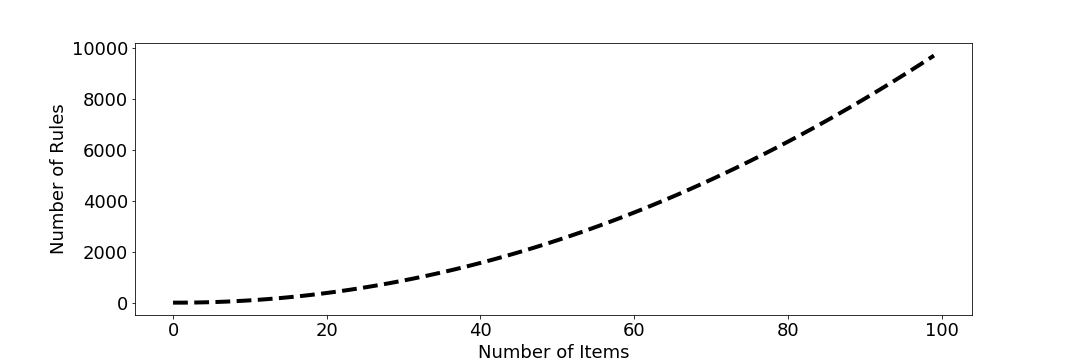
Uno sguardo avanti
# Import the association rules function
from mlxtend.frequent_patterns import association_rules
from mlxtend.frequent_patterns import apriori
# Compute frequent itemsets using the Apriori algorithm
frequent_itemsets = apriori(onehot, min_support = 0.001,
max_len = 2, use_colnames = True)
# Compute all association rules for frequent_itemsets
rules = association_rules(frequent_itemsets,
metric = "lift",
min_threshold = 1.0)
Ayo berlatih!
Analisi del carrello in Python

