Organizzazione del codice e refactoring
Introduzione al versionamento dei dati con DVC

Ravi Bhadauria
Machine Learning Engineer
Caratteristiche di buon codice di produzione
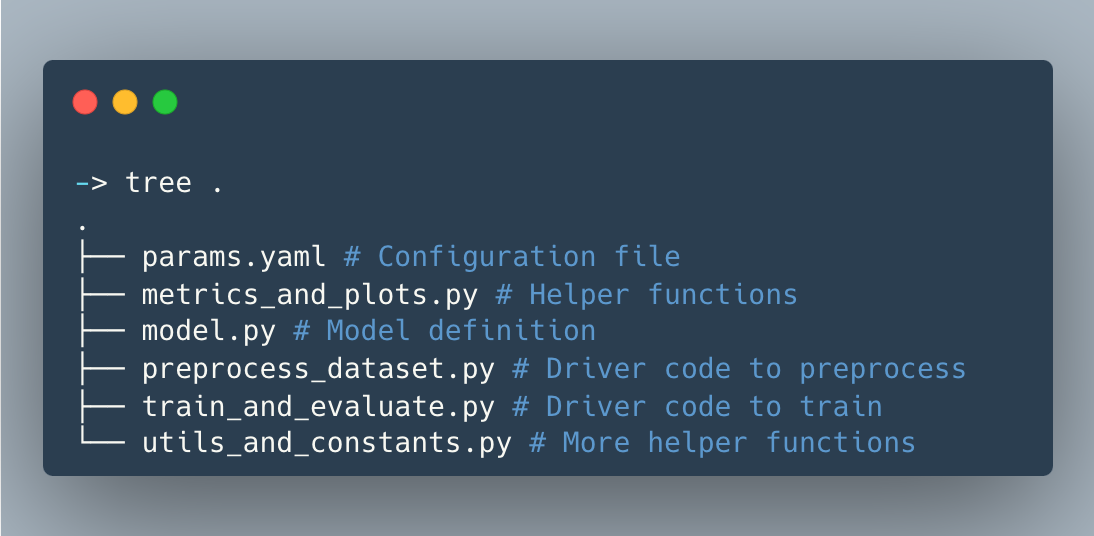
Esempio di layout del progetto
Introduzione al versionamento dei dati con DVC
Ravi Bhadauria
Machine Learning Engineer

