Prevedere le transazioni dei clienti
Machine Learning per il marketing con Python

Karolis Urbonas
Head of Analytics & Science, Amazon
Tabella riepilogo regressione
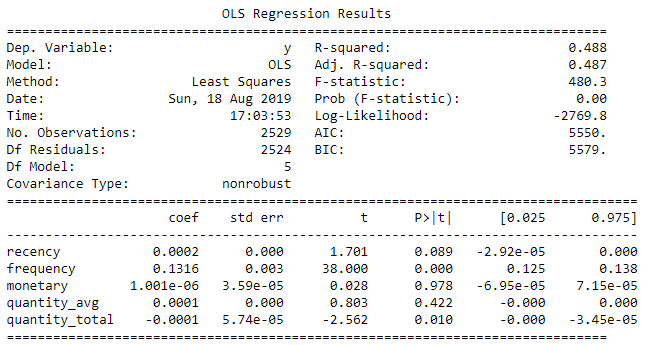
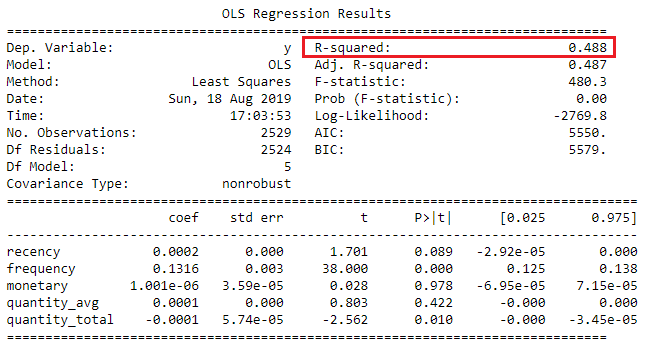
Interpretare R-quadro
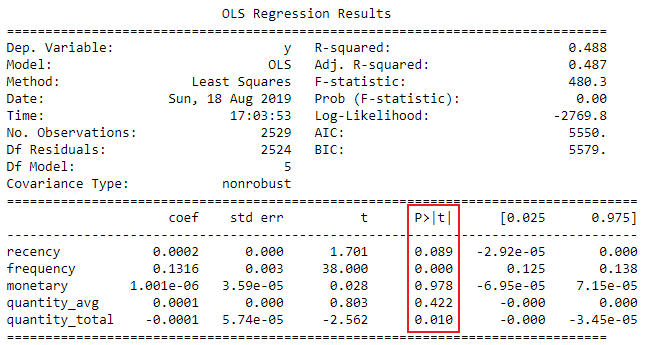
Interpretare i p-value dei coefficienti
Machine Learning per il marketing con Python
Karolis Urbonas
Head of Analytics & Science, Amazon

