Preparazione dati per prevedere gli acquisti
Machine Learning per il marketing con Python

Karolis Urbonas
Head of Analytics & Science, Amazon
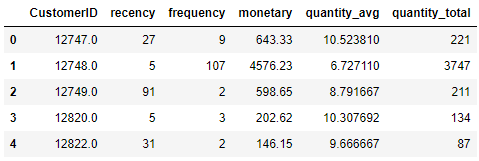
Rivedi le feature
print(features.head())
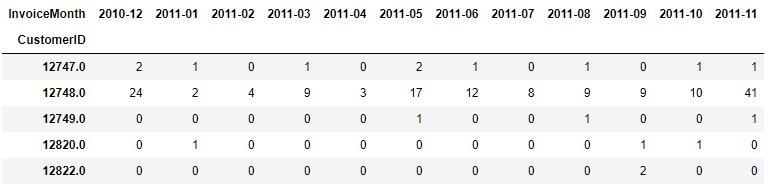
Calcola la variabile target
# Crea tabella pivot con transazioni mensili per cliente
cust_month_tx = pd.pivot_table(data=online, index=['CustomerID'],
values='InvoiceNo',
columns=['InvoiceMonth'],
aggfunc=pd.Series.nunique, fill_value=0)
print(cust_month_tx.head())