Crea segmentazioni di clienti e prodotti
Machine Learning per il marketing con Python

Karolis Urbonas
Head of Analytics & Science, Amazon
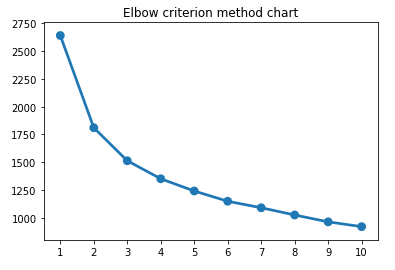
Identificare il numero ottimale di segmenti
Machine Learning per il marketing con Python
Karolis Urbonas
Head of Analytics & Science, Amazon

