Altre word cloud e reti di parole
Text mining con Bag-of-Words in R

Ted Kwartler
Instructor
Commonality cloud
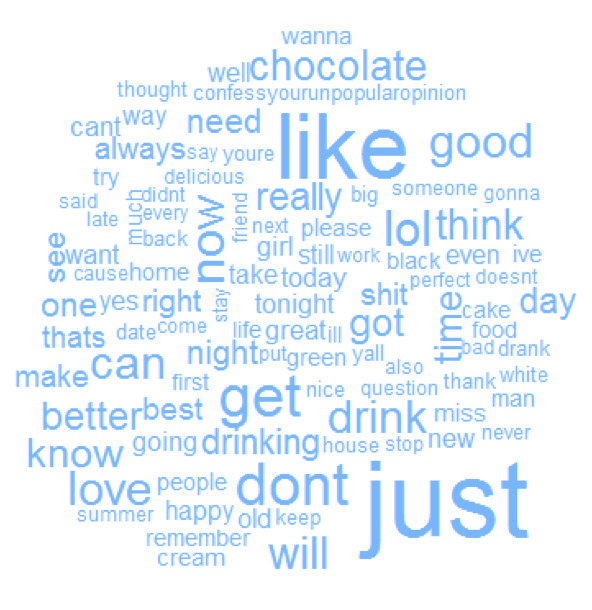
Commonality cloud
Comparison cloud
Comparison cloud
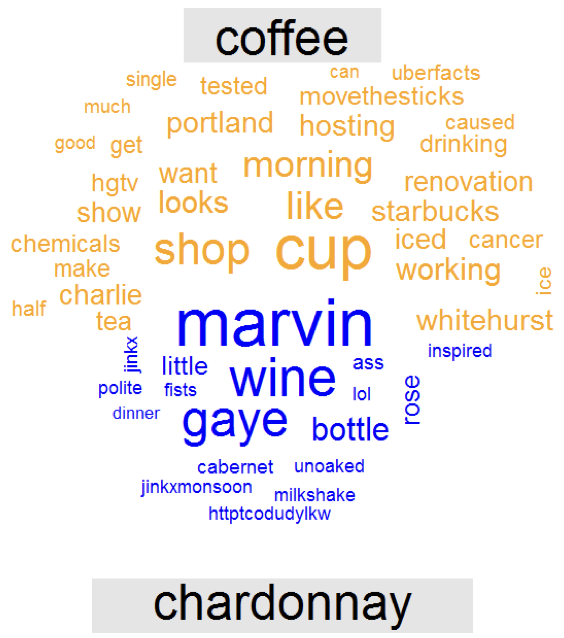
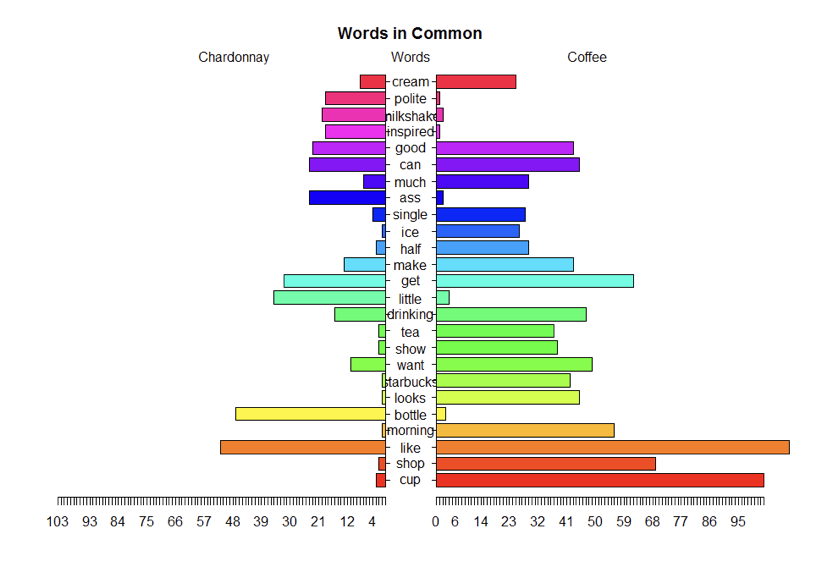
Grafici a piramide
Reti di parole

Text mining con Bag-of-Words in R
Ted Kwartler
Instructor

