Pulizia e preelaborazione del testo
Text mining con Bag-of-Words in R

Ted Kwartler
Instructor
Funzioni di preelaborazione comuni
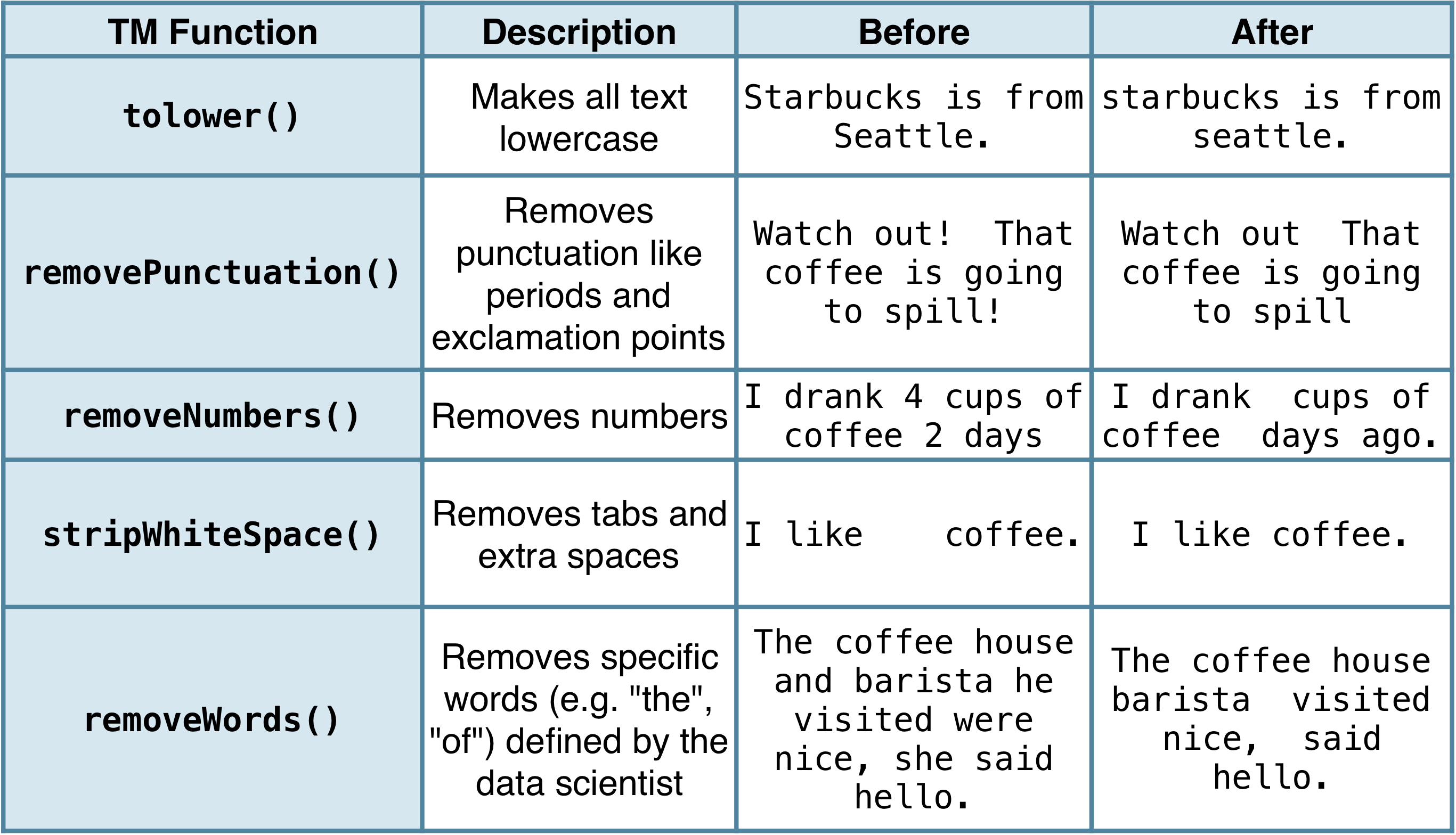
Preelaborazione in pratica
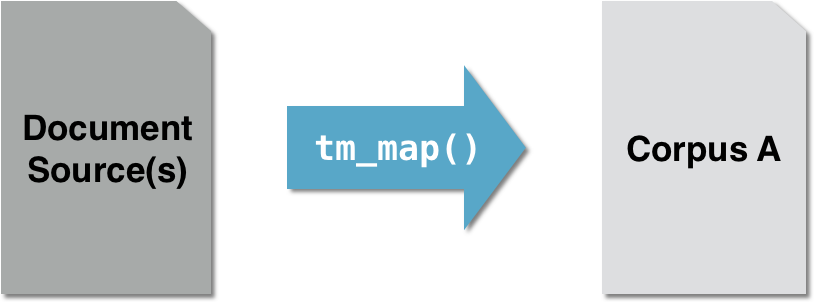
# Crea un vettore sorgente: coffee_source coffee_source <- VectorSource(coffee_tweets)# Crea un corpus volatile: coffee_corpus coffee_corpus <- VCorpus(coffee_source)# Applica varie funzioni di preelaborazione tm_map(coffee_corpus, removeNumbers) tm_map(coffee_corpus, removePunctuation)tm_map(coffee_corpus, content_transformer(replace_abbreviation))

