Training and updating models
NLP avanzato con spaCy

Ines Montani
spaCy core developer
How training works (2)
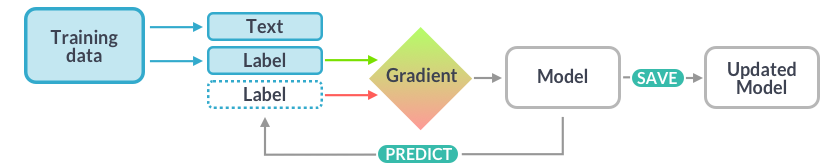
- Training data: Examples and their annotations.
- Text: The input text the model should predict a label for.
- Label: The label the model should predict.
- Gradient: How to change the weights.

