Perché trasformare le feature esistenti?
Feature Engineering in R

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
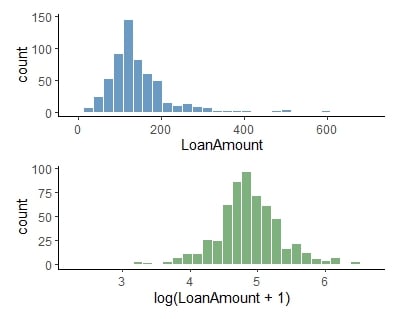
Trasformazione log
Dati dell’importo del prestito trasformati con log
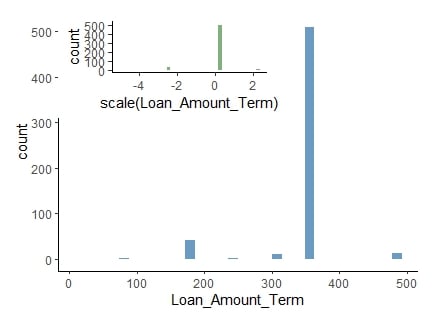
Normalizzazione
ad es., i valori della durata dell’importo del prestito variano molto
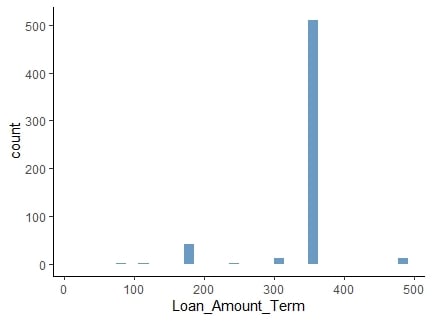
Normalizzazione
I valori normalizzati preservano la distribuzione, ma mantengono la variazione.