Mettere tutto insieme
Feature Engineering in R

Jorge Zazueta
Research Professor. Head of the Modeling Group at the School of Economics, UASLP
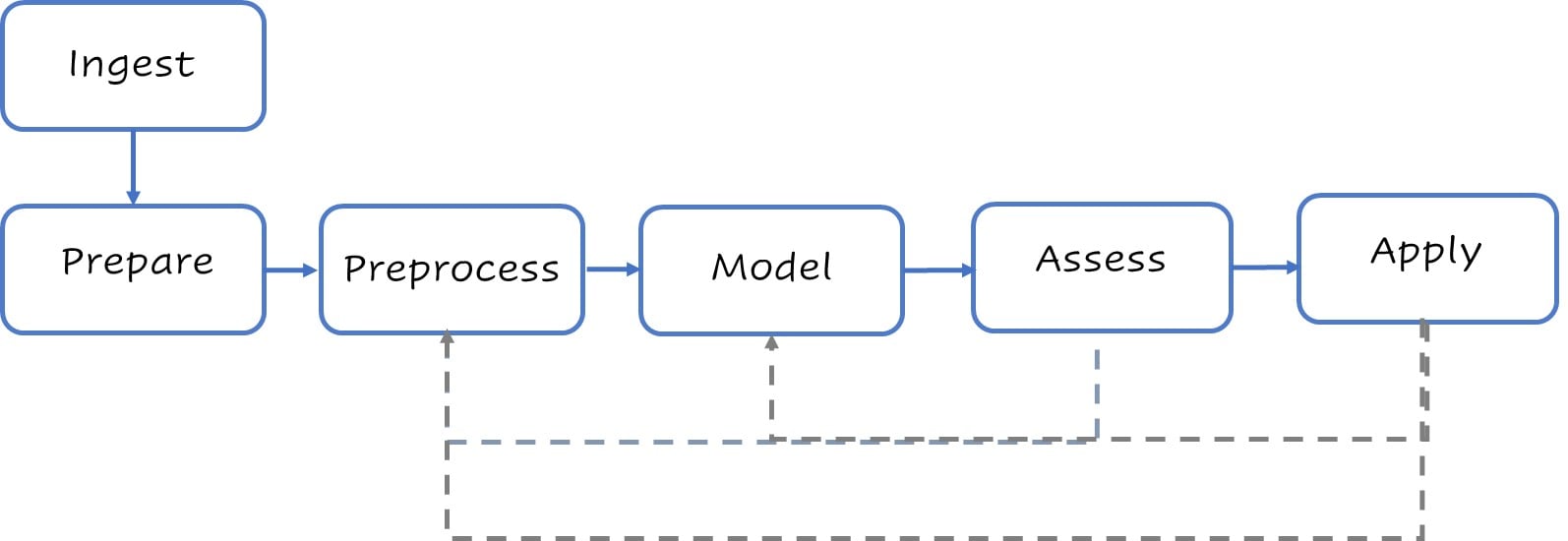
Un flusso di modellazione stilizzato
Tipici passaggi di modellazione ad alto livello.
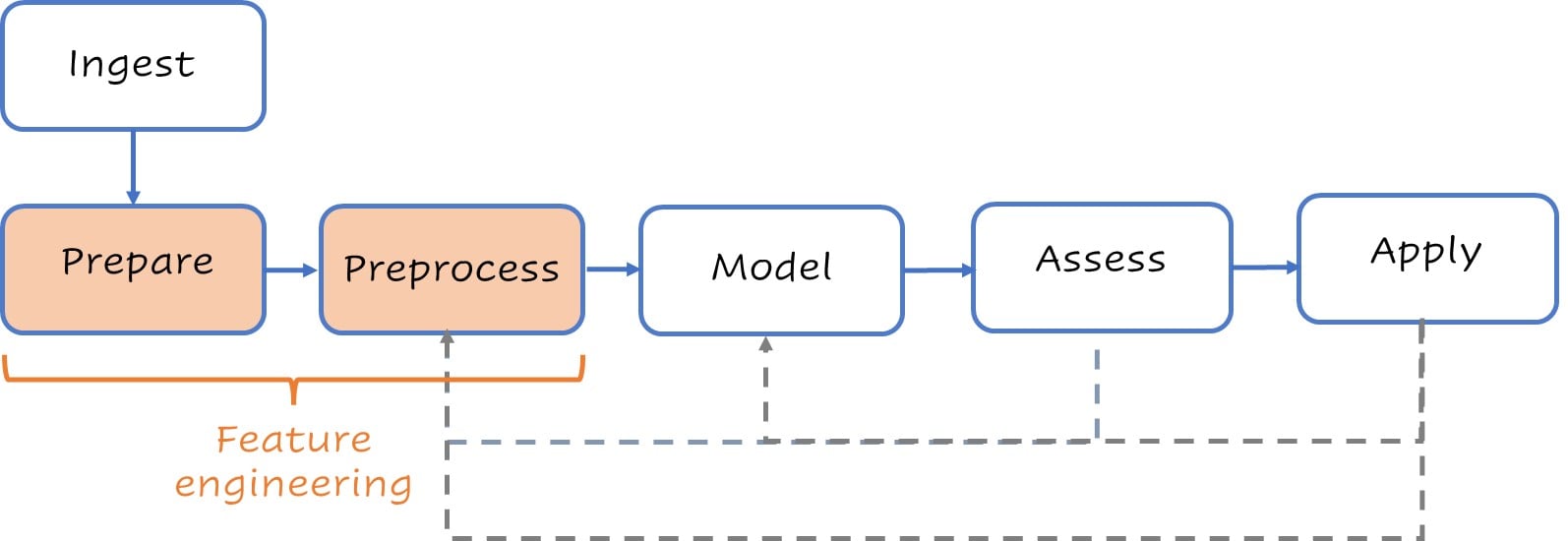
Un flusso di modellazione stilizzato
Tipici passaggi di modellazione ad alto livello.
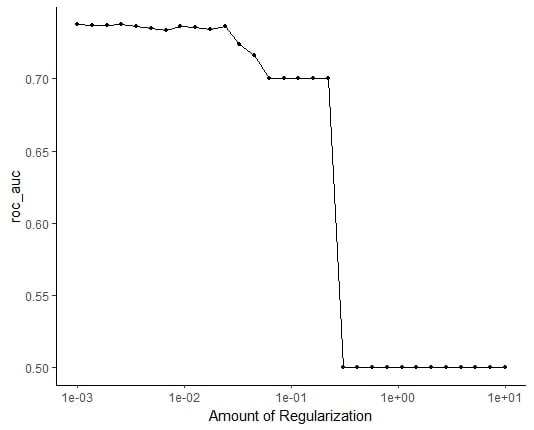
Valuta
ROC_AUC vs. regolarizzazione