Aumentare le informazioni nei dati grezzi
Feature Engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
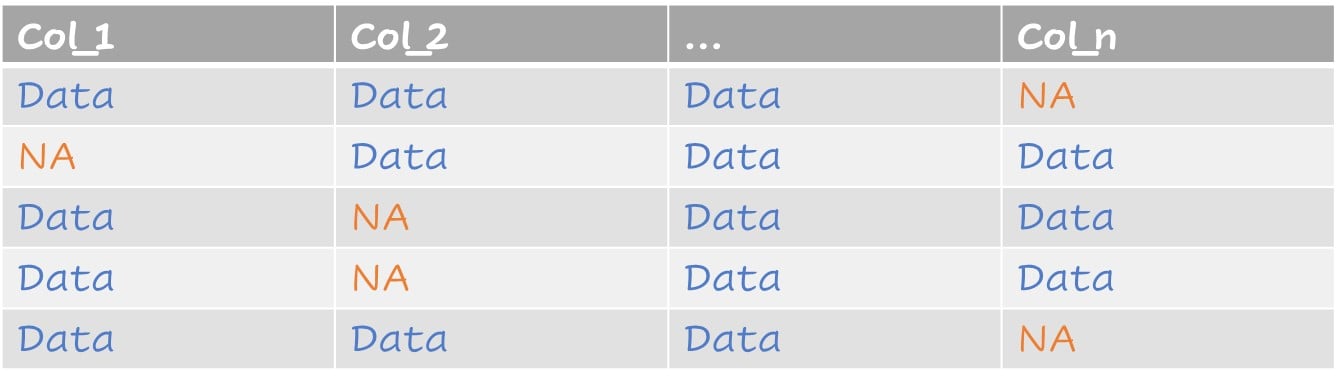
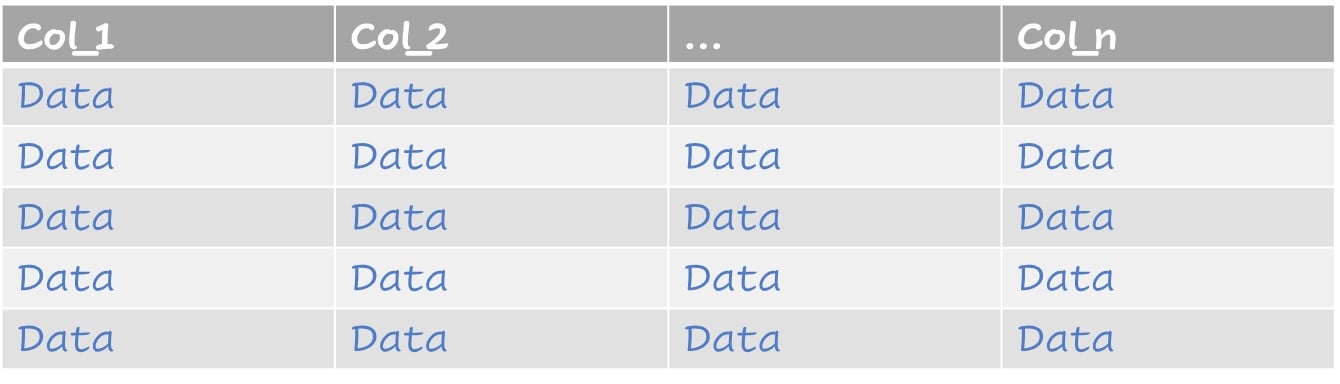
Gestire i dati grezzi
Un tipico dataset con valori mancanti
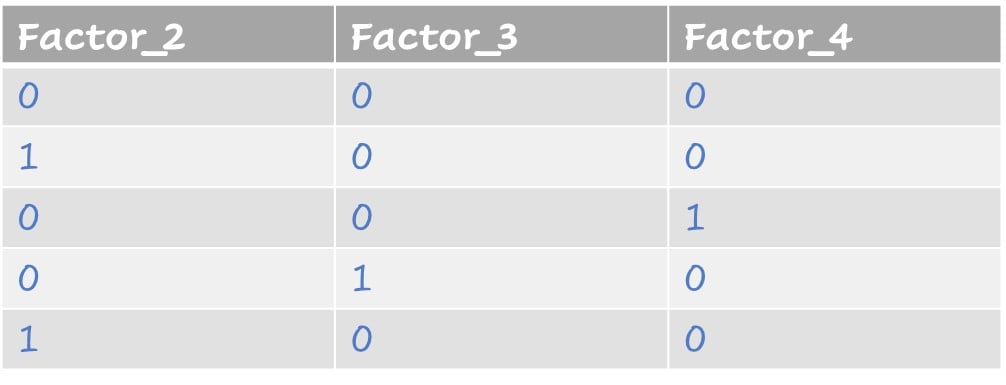
Valori come fattori

Gestire i dati grezzi
Dataset con valori imputati
Fattori rappresentati come variabili dummy
Valori mancanti
Possiamo identificare visivamente i valori mancanti in loans usando vis_miss(loans) dal pacchetto naniar.
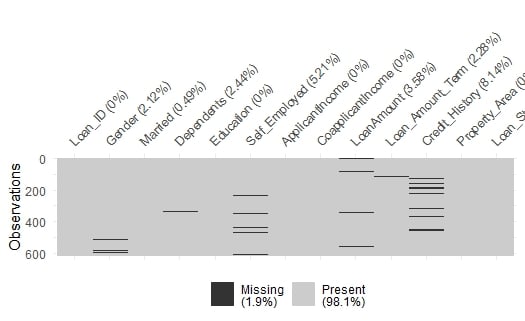
Valori mancanti
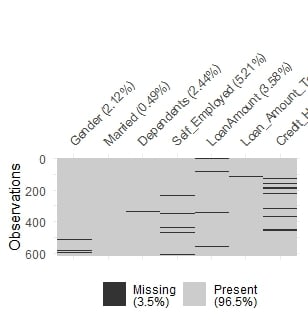
Uno sguardo più da vicino ai valori mancanti
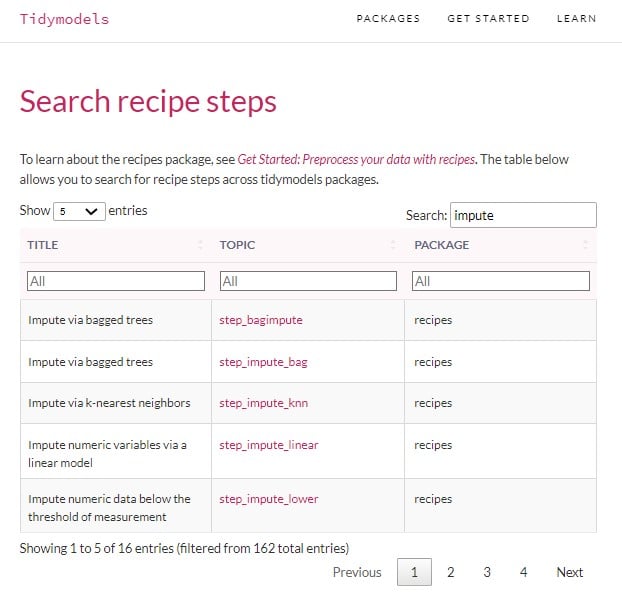
Trovare lo step giusto della recipe
Trovi altri metodi di imputazione e tutti gli step delle recipe nella documentazione di tidymodels su www.tidymodels.org/find/recipes
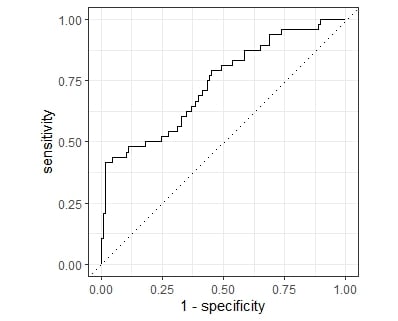
Fitting e valutazione del modello
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.738
2 accuracy binary 0.792