Codifica delle variabili categoriali con apprendimento supervisionato
Feature Engineering in R

Jorge Zazueta
Research Professor and Head of the Modeling Group at the School of Economics, UASLP
Introduzione alla codifica supervisionata
La codifica supervisionata usa i valori dell’outcome per ricavare feature numeriche da predittori nominali.
Introduzione alla codifica supervisionata
La codifica supervisionata usa i valori dell’outcome per ricavare feature numeriche da predittori nominali.
Alcune funzioni di codifica supervisionata nel pacchetto embed
| Function | Definition |
|---|---|
| step_lencode_glm() | Usa codifiche di verosimiglianza per convertire un predittore nominale in un singolo vettore di punteggi da un modello lineare generalizzato. |
| step_lencode_bayes() | Applica codifiche bayesiane di verosimiglianza per convertire un predittore nominale in un singolo vettore di punteggi da un modello lineare generalizzato stimato con analisi bayesiana. |
| step_lencode_mixed() | Converte predittori nominali in un singolo vettore di punteggi da un modello lineare generalizzato misto. |
Prevedere il successo delle domande di finanziamento
Vogliamo prevedere il successo delle domande di finanziamento usando solo il codice sponsor.
lr_model <- logistic_reg() # declare model
lr_recipe_glm <- # Set recipe glm
recipe(class ~ sponsor_code,
data = grants_train) %>%
step_lencode_glm(sponsor_code,
# Declare outcome variable
outcome = vars(class))
lr_workflow_glm <- # Create Workflow
workflow() %>%
add_model(lr_model) %>%
add_recipe(lr_recipe_glm)
Riepilogo del workflow
lr_workflow_glm
-- Workflow ------------------------------------
Preprocessor: Recipe
Model: logistic_reg()
-- Preprocessor --------------------------------
1 Recipe Step
- step_lencode_glm()
-- Model --------------------------------------
Logistic Regression Model Specification (classification)
Computational engine: glm
Addestrare, aumentare e valutare
Addestriamo e valutiamo il modello
lr_fit_glm <- # Fit
lr_workflow_glm %>%
fit(grants_train)
lr_aug_glm <- # Augment
lr_fit_glm %>%
augment(grants_test)
glm_model <- lr_aug_glm %>% # Assess
class_evaluate(truth = class,
estimate = .pred_class,
.pred_successful)
I risultati delle prestazioni sono salvati in glm_model
glm_model
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.728
2 roc_auc binary 0.684
Unire i modelli
Creiamo bayes_model e mixed_model per confrontare le prestazioni dei relativi step.
# Define model names
model <- c("glm", "glm",
"bayes","bayes",
"mixed", "mixed")
# Bind models in a tibble
models <-
bind_rows(glm_model,
bayes_model,
mixed_model)%>%
add_column(model = model)%>%
select(-.estimator) %>%
spread(model,.estimate)
Una tabella di prestazioni pratica
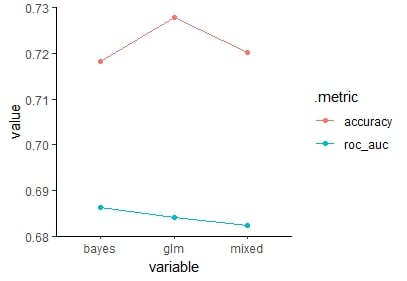
models
# A tibble: 2 × 4
.metric bayes glm mixed
<chr> <dbl> <dbl> <dbl>
1 accuracy 0.718 0.728 0.720
2 roc_auc 0.686 0.684 0.682
Visualizzare i risultati
Visualizza i risultati con un grafico a coordinate parallele dal pacchetto GGally.
# Libraries
library(GGally)
# Parallel coordinates chart
ggparcoord(models,
columns = 2:4,
groupColumn = 1,
scale="globalminmax",
showPoints = TRUE)
Grafico a coordinate parallele di accuracy e roc_auc per tutti i modelli.
Passiamo alla pratica !
Feature Engineering in R

