Pipeline di apprendimento supervisionato
Progettare workflow di Machine Learning in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
Dati etichettati
- Variabili di feature (abbrev.:
X) - Etichette o classe (abbrev.:
y)
credit_scoring.head(4)
checking_status duration ... foreign_worker class
0 '<0' 6 ... yes good
1 '0<=X<200' 48 ... yes bad
2 'no checking' 12 ... yes good
3 '<0' 42 ... yes good
Feature engineering
- Molti classificatori richiedono feature numeriche
- Serve convertire le colonne stringa in numeri
Pre-elabora con LabelEncoder da sklearn.preprocessing:
le = LabelEncoder()
le.fit_transform(credit_scoring['checking_status'])[:4]
array([1, 0, 3, 1])
Addestramento del modello
.fit(features, labels).predict(features)
features, labels = credit_scoring.drop('class', 1), credit_scoring['class']model_nb = GaussianNB() model_nb.fit(features, labels) model_nb.predict(features.head(5))
['good' 'bad' 'good' 'bad' 'good']
60% di accuratezza sui primi 5 esempi.
Selezione del modello
.fit()ottimizza i parametri del modello- E con altri modelli?
AdaBoostClassifier supera GaussianNB sui primi cinque punti:
model_ab = AdaBoostClassifier()
model_ab.fit(features, labels)
model_ab.predict(features.head(5))
numpy.array(labels[0:5])
['good' 'bad' 'good' 'good' 'bad']
['good' 'bad' 'good' 'good' 'bad']
Valutazione delle prestazioni
Campioni più grandi => stime di accuratezza migliori:
from sklearn.metrics import accuracy_score
accuracy_score(labels, model_nb.predict(features)) # naive bayes
0.706
accuracy_score(labels, model_ab.predict(features)) # adaboost
0.802
Cosa non va in questo calcolo?
Overfitting e split dei dati
Overfitting: un modello va sempre meglio sui dati di training che su dati mai visti.
Allena su X_train, y_train, valuta l’accuratezza su X_test, y_test:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)GaussianNB().fit(X_train, y_train).predict(X_test)
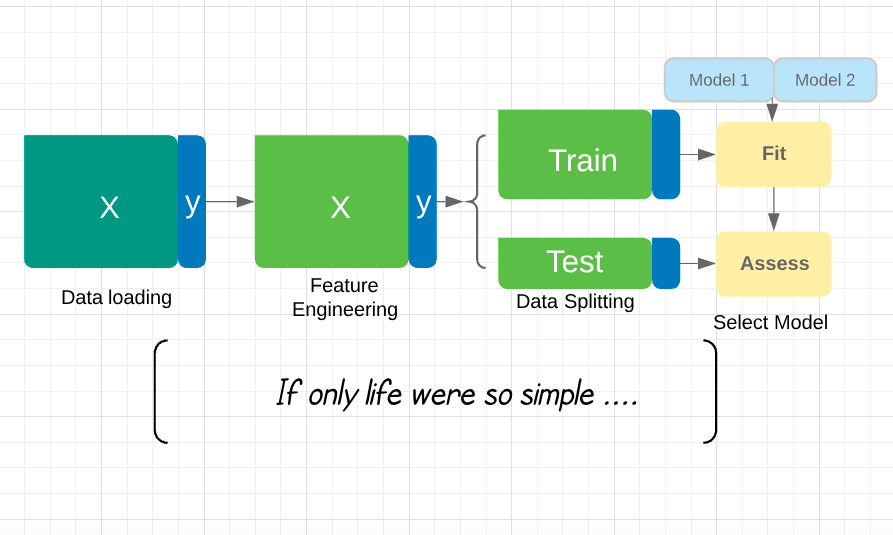
Di cosa parla il corso?
- Metodi scalabili per ottimizzare la pipeline.
- Rendere le previsioni utili coinvolgendo esperti di dominio.
- Garantire buone performance nel tempo.
- Allenare modelli con poche etichette.
Avresti potuto prevenire la crisi dei mutui?
Progettare workflow di Machine Learning in Python

