Funzioni di loss Parte I
Progettare workflow di Machine Learning in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
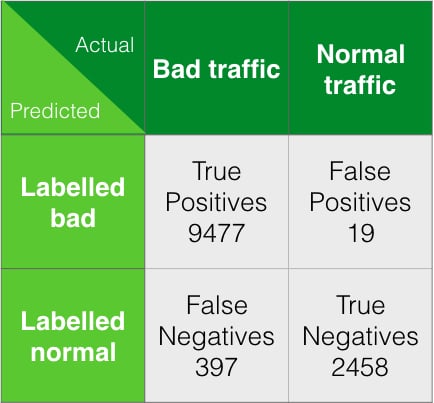
Falsi positivi vs falsi negativi

Falsi positivi vs falsi negativi

Falsi positivi vs falsi negativi

Falsi positivi vs falsi negativi

La matrice di confusione