Dai workflow alle pipeline
Progettare workflow di Machine Learning in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
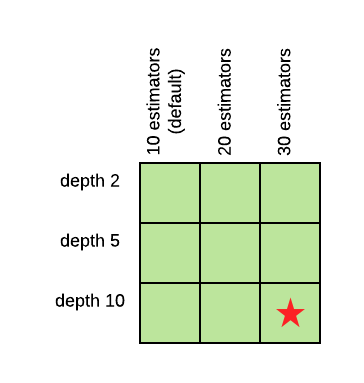
La potenza della grid search
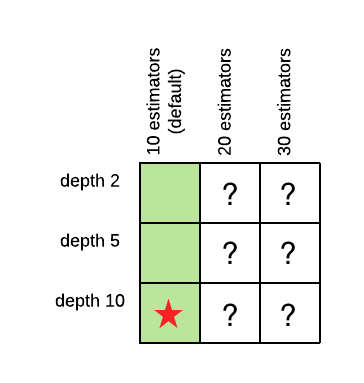
La potenza della grid search
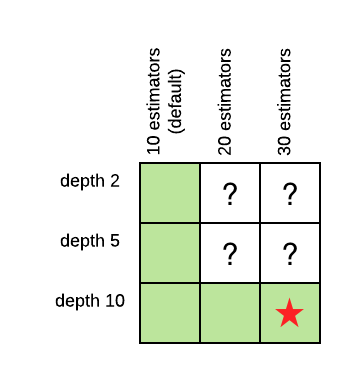
La potenza della grid search
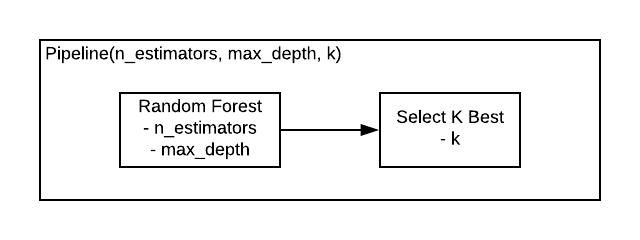
Pipeline
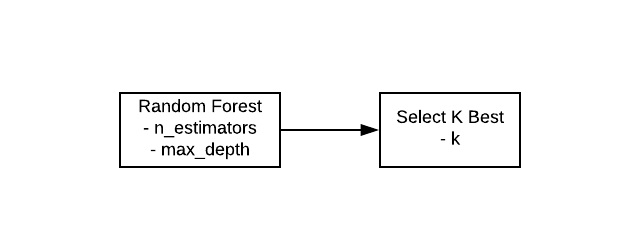
Pipeline
Progettare workflow di Machine Learning in Python
Dr. Chris Anagnostopoulos
Honorary Associate Professor

