Basi delle espressioni regolari
Introduzione all'Elaborazione del Linguaggio Naturale in R

Kasey Jones
Research Data Scientist
Pratica RegEx
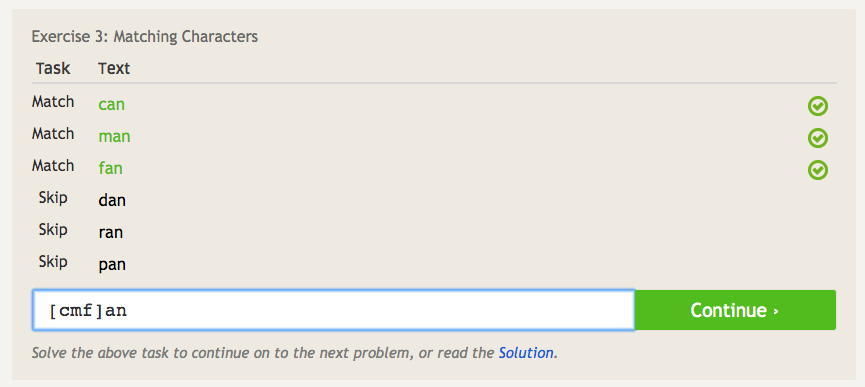
1 https://regexone.com/lesson/matching_characters
Introduzione all'Elaborazione del Linguaggio Naturale in R
Kasey Jones
Research Data Scientist

