LDA nella pratica
Introduzione all'Elaborazione del Linguaggio Naturale in R

Kasey Jones
Research Data Scientist
Finalizzare i risultati LDA
- scegli il numero di topic
- perplexity/altri metriche
- una soluzione adatta al tuo contesto
Perplexity
- misura di quanto bene un modello probabilistico generalizza su nuovi dati
- più bassa è meglio
- usata per confrontare modelli
- Nel tuning dei parametri LDA
- Scelta del numero di topic
sample_size <- floor(0.90 * nrow(doc_term_matrix))
set.seed(1111)
train_ind <- sample(nrow(doc_term_matrix), size = sample_size)
train <- matrix[train_ind, ]
test <- matrix[-train_ind, ]
1 https://en.wikipedia.org/wiki/Perplexity
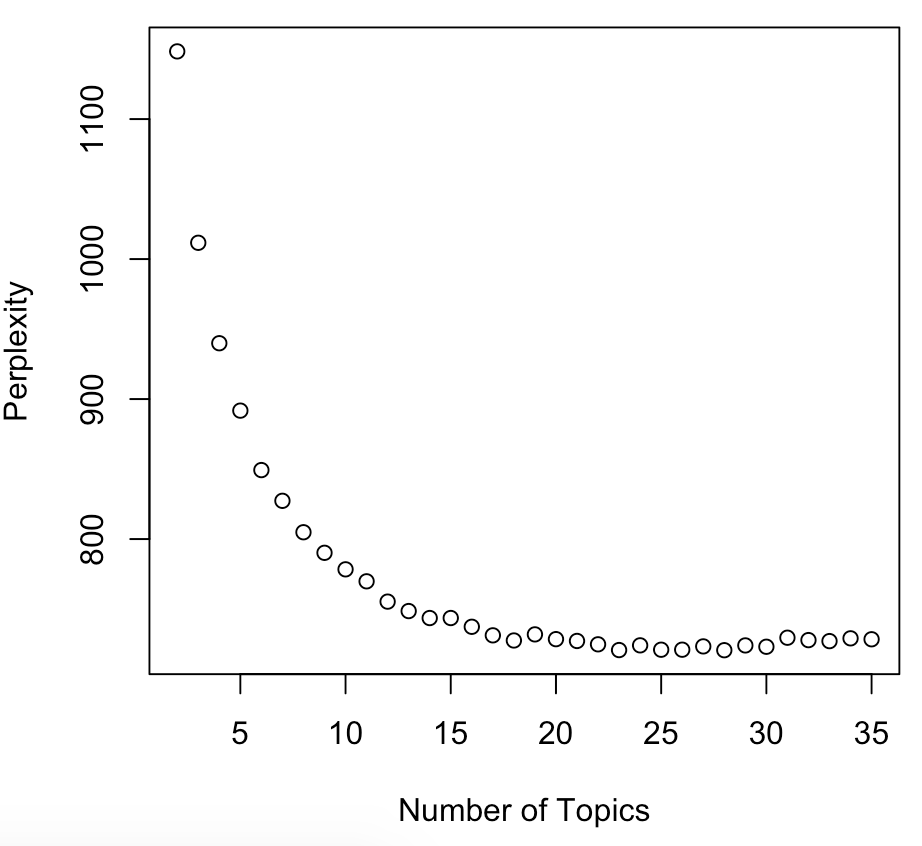
Perplexity in R
library(topicmodels)
values = c()
for(i in c(2:35)){
lda_model <- LDA(train, k = i, method = "Gibbs",
control = list(iter = 25, seed = 1111))
values <- c(values, perplexity(lda_model, newdata = test))
}
plot(c(2:35), values, main="Perplexity for Topics",
xlab="Number of Topics", ylab="Perplexity")
Ancora perplexity!
Scelta pratica
- Quanti topic regge il contesto
- 20 potrebbero essere troppi
- Come mostri i risultati
- Grafici con 5 topic sono più chiari di grafici con 100
- Regole pratiche:
- Usa pochi topic, ciascuno rappresentato da più documenti
- Usa molti topic solo se hai tempo per esplorarli e analizzarli
Usare i risultati
- Rivedi o fai trovare ai revisori i “temi” di ogni topic
- fornisci l’elenco delle parole top del topic
- fornisci l’elenco dei documenti top per quel topic
Rivedi l’output
betas <- tidy(lda_model, matrix = "beta")
betas %>%
filter(topic == 1) %>%
arrange(desc(beta)) %>%
select(term)
# A tibble: 2,000 x 1
term
<chr>
1 athletic
2 quick
3 strong
4 tough
...
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
filter(topic == 1) %>%
arrange(desc(gamma)) %>%
select(document)
# A tibble: 1,000 x 1
document
<chr>
1 232
2 292
3 921
4 643
5 468
Riassumi l’output
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
tally(topic, sort=TRUE)
topic n
1 1 1326
2 5 1215
3 4 804
...
Riassumi di nuovo
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
summarize(avg=mean(gamma)) %>%
arrange(desc(avg))
topic avg
1 1 0.696
2 5 0.530
3 4 0.482
...
LDA: pratica.
Introduzione all'Elaborazione del Linguaggio Naturale in R

