Introduzione al topic modeling
Introduzione all'Elaborazione del Linguaggio Naturale in R

Kasey Jones
Research Data Scientist
Latent Dirichlet Allocation

1 https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
Parole principali (continua)
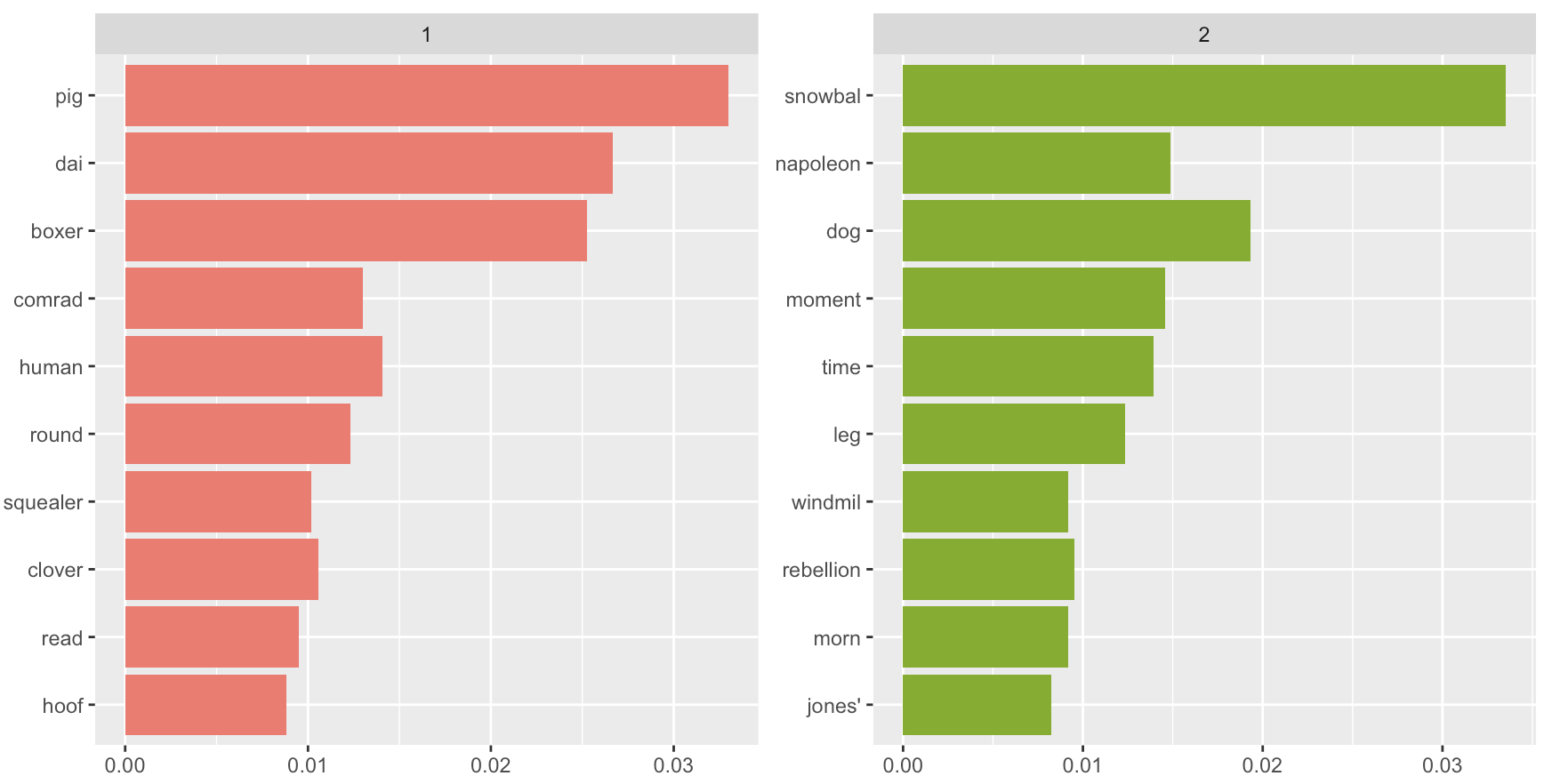
1 https://www.tidytextmining.com/topicmodeling.html

