Misurare i benefici
Programmazione parallela in R

Nabeel Imam
Data Scientist
Esempio giocattolo
numbers <- 1:1000000# Sequenziale sqroots <- lapply(numbers, sqrt)# Parallelo cl <- makeCluster(4) sqroots <- parLapply(cl, numbers, sqrt) stopCluster(my_cluster)
Quale andrà meglio?
Benchmark delle prestazioni
Esegui il codice più volte per stimare il tempo medio di esecuzione
library(microbenchmark)microbenchmark( "Sequential" = lapply(numbers, sqrt),"Parallel" = { cl <- makeCluster(4) parLapply(cl, numbers, sqrt) stopCluster(my_cluster) },times = 10 )
Unit: milliseconds
expr min mean max neval
Sequential 633.96 838.09 993.59 10
Parallel 1136.95 1247.29 1557.58 10
- Le operazioni numeriche semplici raramente traggono vantaggio dal parallelo
- Il profiling dà un report riga per riga, il benchmarking i tempi complessivi
L’elefante nella stanza
sqroots <- sqrt(numbers)

Vettorializzazione
sqroots <- sqrt(numbers)
- Le funzioni di base R, come
sqrt(), sono vettorializzate. - Applica una funzione a molti input
- Molto veloce ma adatta solo a operazioni semplici
microbenchmark(
"Vectorized" = sqrt(numbers),
"Sequential" = lapply(numbers, sqrt),
"Parallel" = {
cl <- makeCluster(4)
parLapply(cl, numbers, sqrt)
stopCluster(my_cluster)
},
times = 10)
Unit: milliseconds
expr min mean max neval
Vectorized 2.3904 9.2071 66.303 10
Sequential 352.1166 771.7491 1004.753 10
Parallel 1191.3176 1377.6926 1700.316 10
Il bootstrap
Campionare i dati attuali con reinserimento
print(ls_df)
$`2001`
Country Life_expectancy Year
1 Afghanistan 56.3 2001
2 Albania 74.3 2001
3 Algeria 71.1 2001
...
$`2002`
Country Life_expectancy Year
1 Afghanistan 56.8 2002
2 Albania 74.6 2002
3 Algeria 71.6 2002
...
Versione classica
df <- ls_df$`2001`estimates <- rep(0, 10000)for (i in 1:10000) { b <- sample(df$Life_expectancy, replace = T)estimates[i] <- mean(b) }
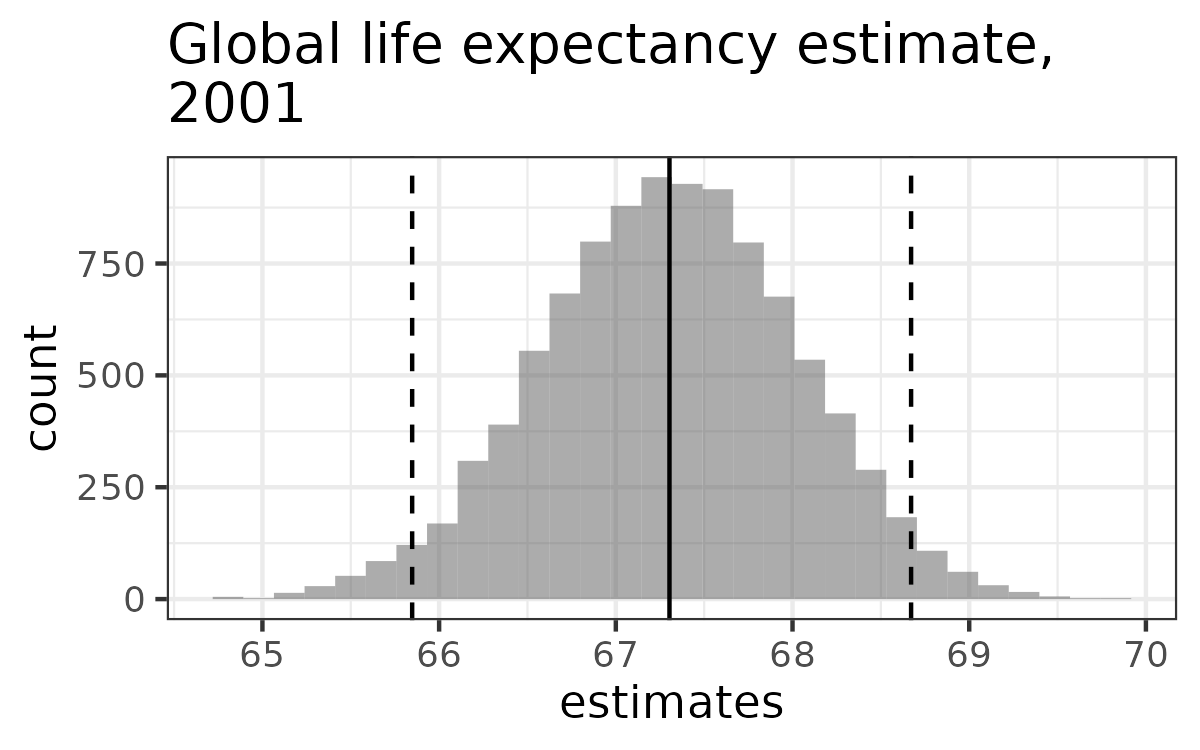
- Intervallo di confidenza con quantili:
quantile(estimates, c(0.025, 0.975))
La buona notizia
I bootstrap si possono parallelizzare
estimates <- rep(0, 10000)
for (i in 1:10000) {
b <- sample(df$Life_expectancy,
replace = T)
estimates[i] <- mean(b)
}
boot_dist <- function (df) { estimates <- rep(0, 10000) for (i in 1:10000) { b <- sample(df$Life_expectancy, replace = T) estimates[i] <- mean(b) } return(estimates) }cl <- makeCluster(4) ls_dists <- parLapply(cl, ls_df, boot_dist) stopCluster(cl)
I benefici
microbenchmark(
"lapply" = lapply(ls_df, boot_dist),
"parLapply" = {
cl <- makeCluster(4)
parLapply(cl, ls_df, boot_dist)
stopCluster(cl)
},
times = 10
)
Unit: seconds
expr min mean max neval
lapply 3.6938 4.2184 4.5267 10
parLapply 1.9006 2.5166 2.7292 10
Come arrivarci:
- Profila il codice, trova la parte più lenta
- Parallelizza/ottimizza quel passaggio
- Fai benchmark e confronta
Andiamo a esercitarci!
Programmazione parallela in R

