Fai di più con future_map()
Programmazione parallela in R

Nabeel Imam
Data Scientist
I dati e la storia
head(data)
state year month plurality
1 AK 1995 1 1
2 AK 1995 1 1
3 AK 1995 1 1
4 AK 1995 1 1
5 AK 1995 1 1
6 AK 1995 1 1
Generare una nuova colonna di testo
twins <- function (x) {
ifelse(x == 2,"Twins", "Not twins")
}
Etichettare i gemelli
plan(multisession, workers = 4)data %>% mutate(label = future_map_chr(plurality, twins))plan(sequential)
state year month plurality label
1 AK 1995 1 1 Not twins
2 AK 1995 1 1 Not twins
3 AK 1995 1 1 Not twins
4 AK 1995 1 1 Not twins
5 AK 1995 1 1 Not twins
6 AK 1995 1 1 Not twins
7 AK 1995 1 1 Not twins
8 AK 1995 1 1 Not twins
9 AK 1995 1 1 Not twins
10 AK 1995 1 1 Not twins
...
Etichettare i gemelli
microbenchmark(
"map_chr" = {
data %>%
mutate(label = map_chr(plurality, twins))
},
"future_map_chr" = {
data %>%
mutate(label = future_map_chr(plurality, twins))
}
)
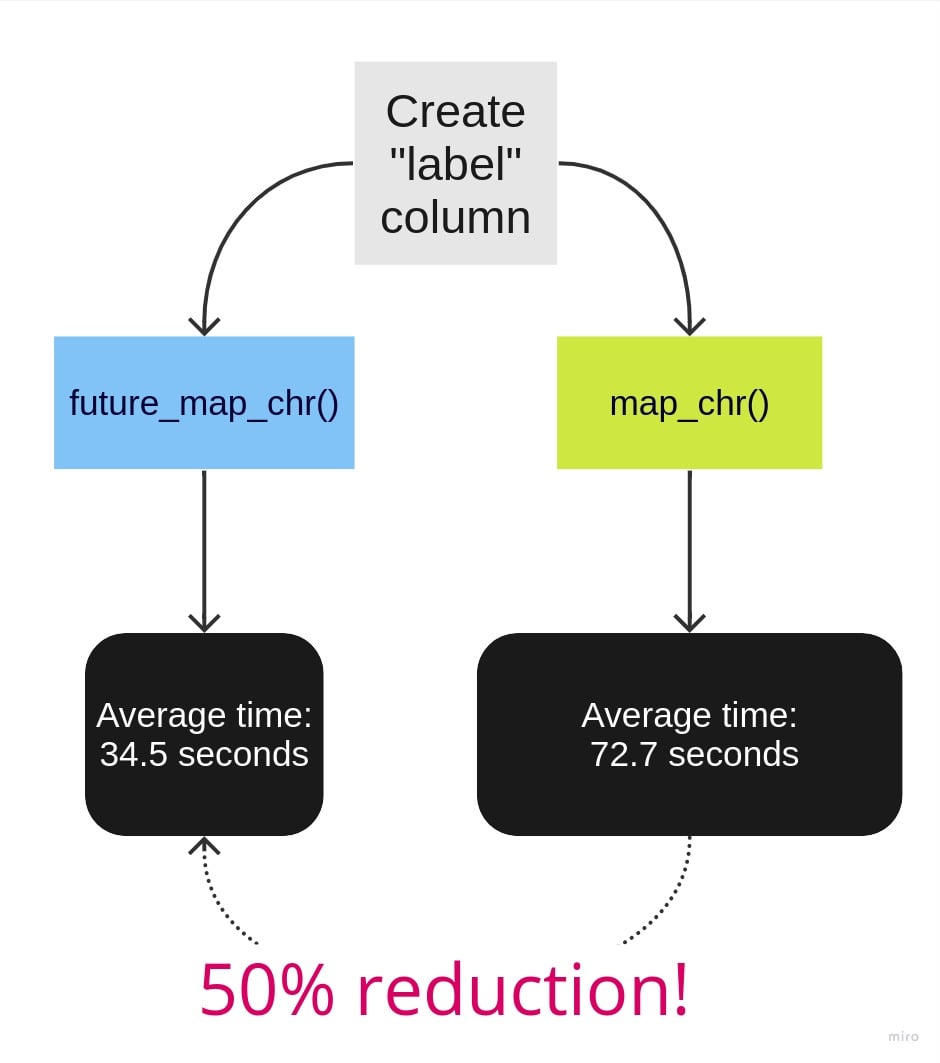
Unit: seconds
expr mean median neval
1 map_chr 72.69067 73.50705 10
2 future_map_chr 34.52351 34.56357 10
Operazioni per gruppi
La proporzione di gemelli
birth_prop <- function (df) {
N <- sum(df$plurality == 2) # Numero totale di nascite gemellari
prop <- N/nrow(df) # Proporzione sul totale delle nascite
names(prop) <- "proportion" # Nome al valore
return(prop)
}
Operazioni per gruppi
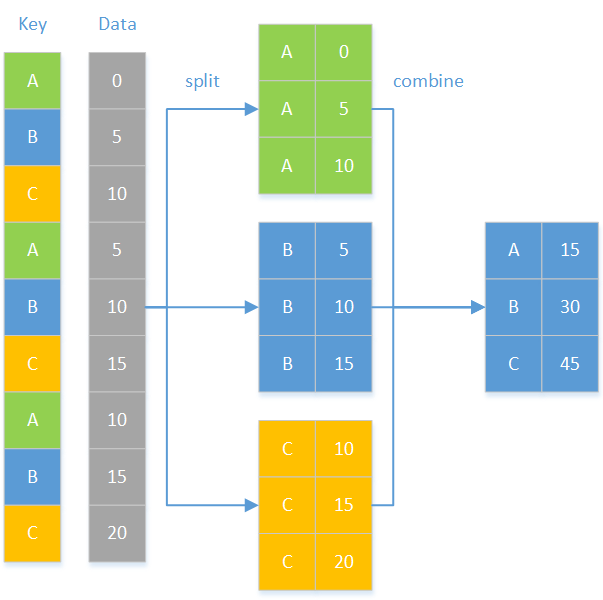
Operazioni per gruppi
plan(multisession, workers = 6)data %>% # Dividi per anno, passa a future_map_dfr() split(data$state) %>%# Fornisci solo la funzione qui future_map_dfr(birth_prop,# Nome della colonna di raggruppamento in .id .id = "state")plan(sequential)
Risultati uniti per righe in un unico data frame
year proportion
1 AK 0.0114
2 AL 0.0264
3 AR 0.0196
4 AZ 0.0218
5 CA 0.0197
6 CO 0.0217
7 CT 0.0225
8 DC 0.0283
9 DE 0.0268
10 FL 0.0212
...
Uso di variabili globali
# Secondo argomento per specificare il valore di plurality birth_prop <- function (df, plur_value) { N <- sum(df$plurality == plur_value) # Numero totale di nascite con quella plurality prop <- N/nrow(df) names(prop) <- "proportion" return(prop) }new_plur <- 3 # Variabile globale a singolo valore
Uso di variabili globali
config <- furrr_options(globals = "new_plur")plan(multisession, workers = 4)data %>% split(data$state) %>% future_map_dfr(birth_prop, plur_value = new_plur, .options = config, .id = "state") plan(sequential)
state proportion
1 AK 0
2 AL 0.000659
3 AR 0
4 AZ 0.000605
5 CA 0.000673
6 CO 0.000776
7 CT 0.000867
8 DC 0.00189
9 DE 0
10 FL 0.00106
...
Unione per colonne in un data frame
data %>%
split(data$state) %>%
future_map_dfc(birth_prop, # Variante _dfc
plur_value = new_plur,
.options = config)
AK AL AR AZ CA CO CT DC
1 0 0.000659 0 0.000605 0.000673 0.000776 0.000867 0.00189 ...
Ayo berlatih!
Programmazione parallela in R

