Monitorare e gestire la memoria
Programmazione parallela in R

Nabeel Imam
Data Scientist
Coda e spazio

Il flusso parallelo

Il flusso parallelo

Profiling con due worker

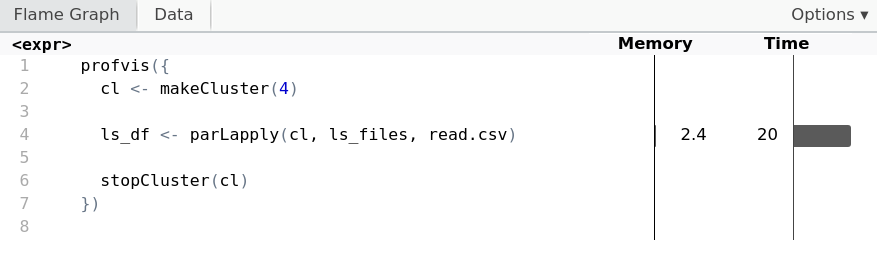
Profiling con quattro worker
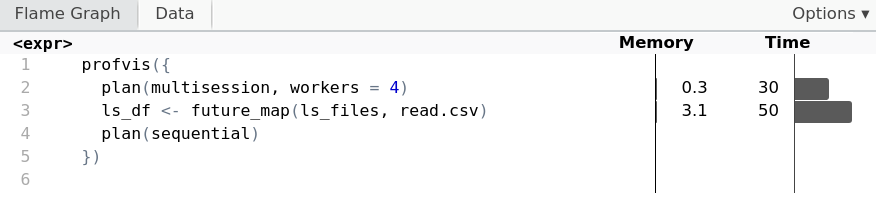
Dietro le quinte
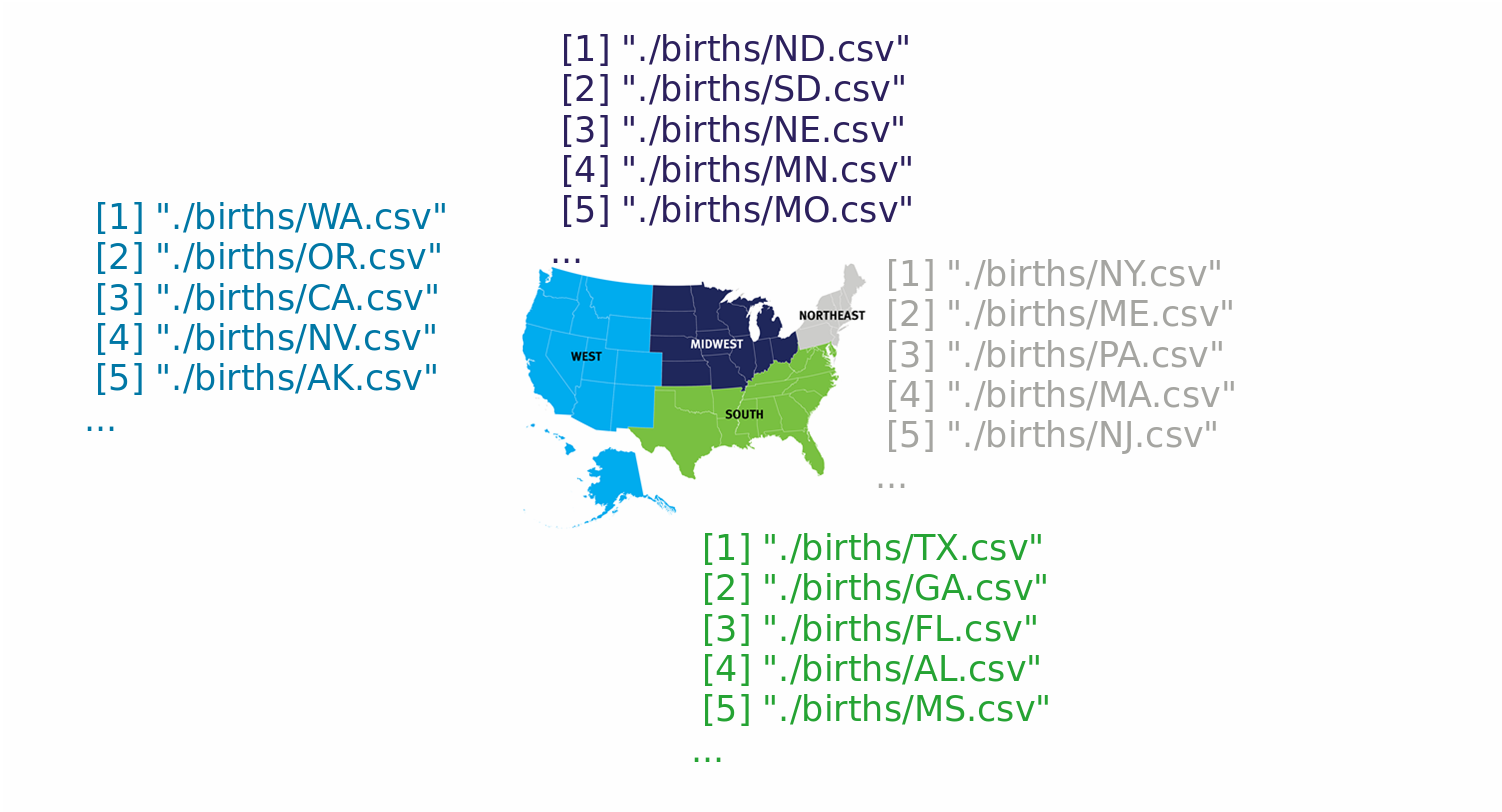
Gestire la memoria con chunk
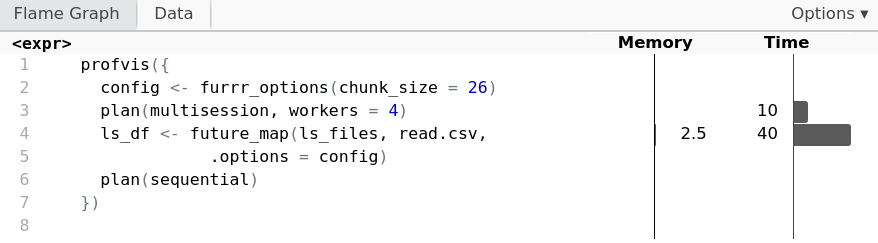
Chunk con parallel
Chunk con parallel
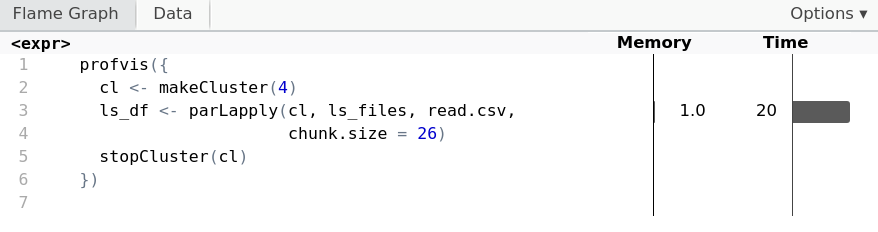
cl <- makeCluster(4) ls_df <- parLapply(cl, ls_files, read.csv,chunk.size = 26)stopCluster(cl)