Dask DataFrame
Programmazione parallela con Dask in Python

James Fulton
Climate Informatics Researcher
pandas DataFrame vs Dask DataFrame
import pandas as pd# Leggi un singolo file CSV pandas_df = pd.read_csv( "dataset/chunk1.csv" )
Questo legge subito un singolo file CSV.
import dask.dataframe as dd# Leggi pigramente tutti i file CSV dask_df = dd.read_csv( "dataset/*.csv" )
Questo legge in modo lazy tutti i CSV nella cartella dataset.
Dask DataFrame
print(dask_df)
Struttura Dask DataFrame:
ID col1 col2 col3 col4 ...
npartitions=3
int64 object object int64 float64 ...
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
Dask Name: getitem, 3 tasks
Task graph di Dask DataFrame
dask.visualize(dask_df)
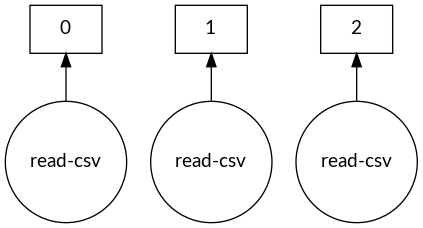
Controllare la dimensione dei blocchi
# Imposta la memoria massima di un blocco dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")print(dask_df)
Struttura Dask DataFrame:
ID col1 col2 col3 col4 ...
npartitions=7
int64 object object int64 float64 ...
... ... ... ... ... ...
... ... ... ... ... ...
... ... ... ... ... ...
Dask Name: getitem, 7 tasks
Spiegare le partizioni
# Imposta la memoria massima di un blocco
dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")
Perché 7 partizioni?
size file
9M dataset/chunk1.csv
18M dataset/chunk2.csv
32M dataset/chunk3.csv
Spiegare le partizioni
# Imposta la memoria massima di un blocco
dask_df = dd.read_csv("dataset/*.csv", blocksize="10MB")
Perché 7 partizioni?
size file
9M dataset/chunk1.csv # diventa 1 partizione
18M dataset/chunk2.csv # diventa 2 partizioni
32M dataset/chunk3.csv # diventa 4 partizioni
Analisi con Dask DataFrame
- Seleziona colonna
col1 = dask_df['col1'] - Assegna colonne
dask_df['double_col1'] = 2 * col1 - Operazioni matematiche, es.:
dask_df.std() dask_df.min()
- Groupby
dask_df.groupby(col1).mean() - Anche funzioni usate prima
dask_df.nlargest(n=3, columns='col1')
Datetime e altre funzionalità di pandas
import pandas as pd # Converti stringa in datetime pd.to_datetime(pandas_df['start_date'])# Attributi datetime pandas_df['start_date'].dt.year pandas_df['start_date'].dt.day pandas_df['start_date'].dt.hour pandas_df['start_date'].dt.minute
import dask.dataframe as dd # Converti stringa in datetime dd.to_datetime(dask_df['start_date'])# Attributi datetime dask_df['start_date'].dt.year dask_df['start_date'].dt.day dask_df['start_date'].dt.hour dask_df['start_date'].dt.minute
Rendere i risultati non-lazy
# Mostra 5 righe
print(dask_df.head())
ID double_col1 col1 col2 col3 ...
0 543795 20 10 436 0 ...
1 874535 24 12 268 0 ...
2 781326 62 31 211 0 ...
3 112457 18 9 898 1 ...
4 103256 142 71 663 0 ...
# Converte il Dask DataFrame lazy in un pandas DataFrame in memoria
results_df = df.compute()
Scrivere l'output direttamente su file
# 7 partizioni (blocchi) quindi 7 file di output
dask_df.to_csv('answer/part-*.csv')
part-0.csv
part-1.csv
part-2.csv
part-3.csv
part-4.csv
part-5.csv
part-6.csv
Formati più veloci: Parquet
# Leggi da Parquet
dask_df = dd.read_parquet('dataset_parquet')
# Salva in Parquet
dask_df.to_parquet('answer_parquet')
- Il formato Parquet è più volte più veloce da leggere rispetto al CSV
- Può essere più rapido anche in scrittura
Ayo berlatih!
Programmazione parallela con Dask in Python

