Imputazione multipla con bootstrap
Gestione dei dati mancanti con imputazioni in R

Michal Oleszak
Machine Learning Engineer
Incertezza dall'imputazione
- L'imputazione è di solito il primo passo prima di analisi o modellazione.
- I valori mancanti sono stimati con incertezza.
- Questa incertezza va considerata in ogni analisi su dati imputati.

In quasi metà degli studi, i risultati chiave scompaiono
Bootstrap
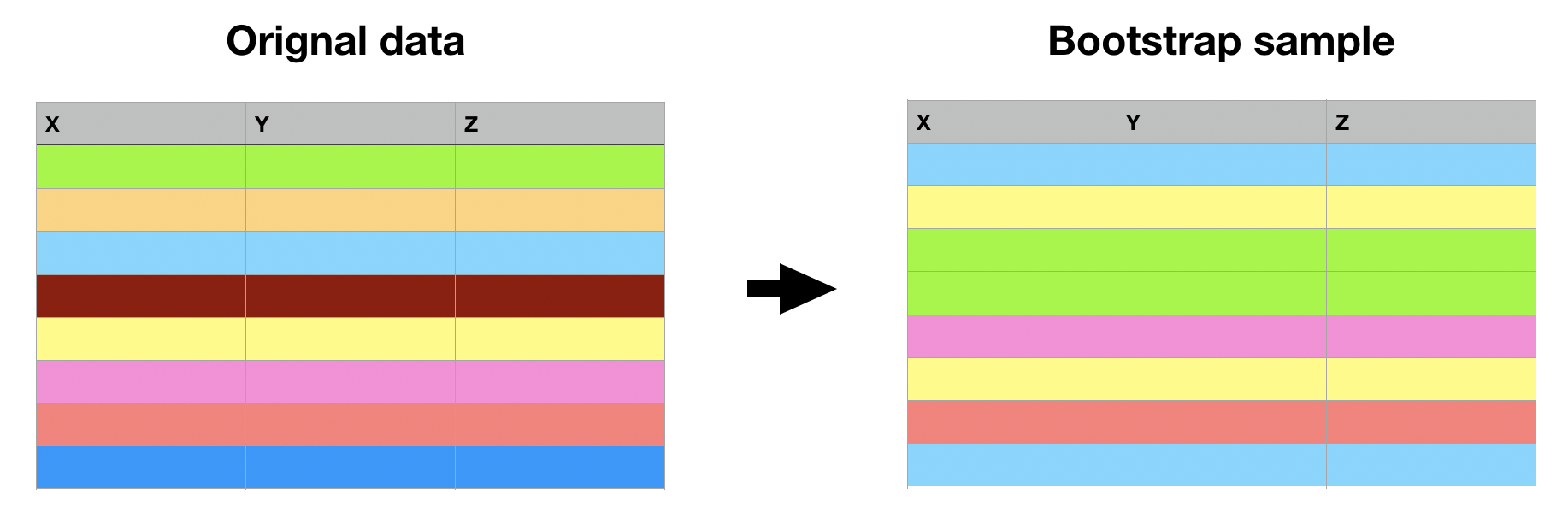
Bootstrap = campionare righe con reinserimento per ottenere dati della dimensione originale
Imputazione multipla con bootstrap
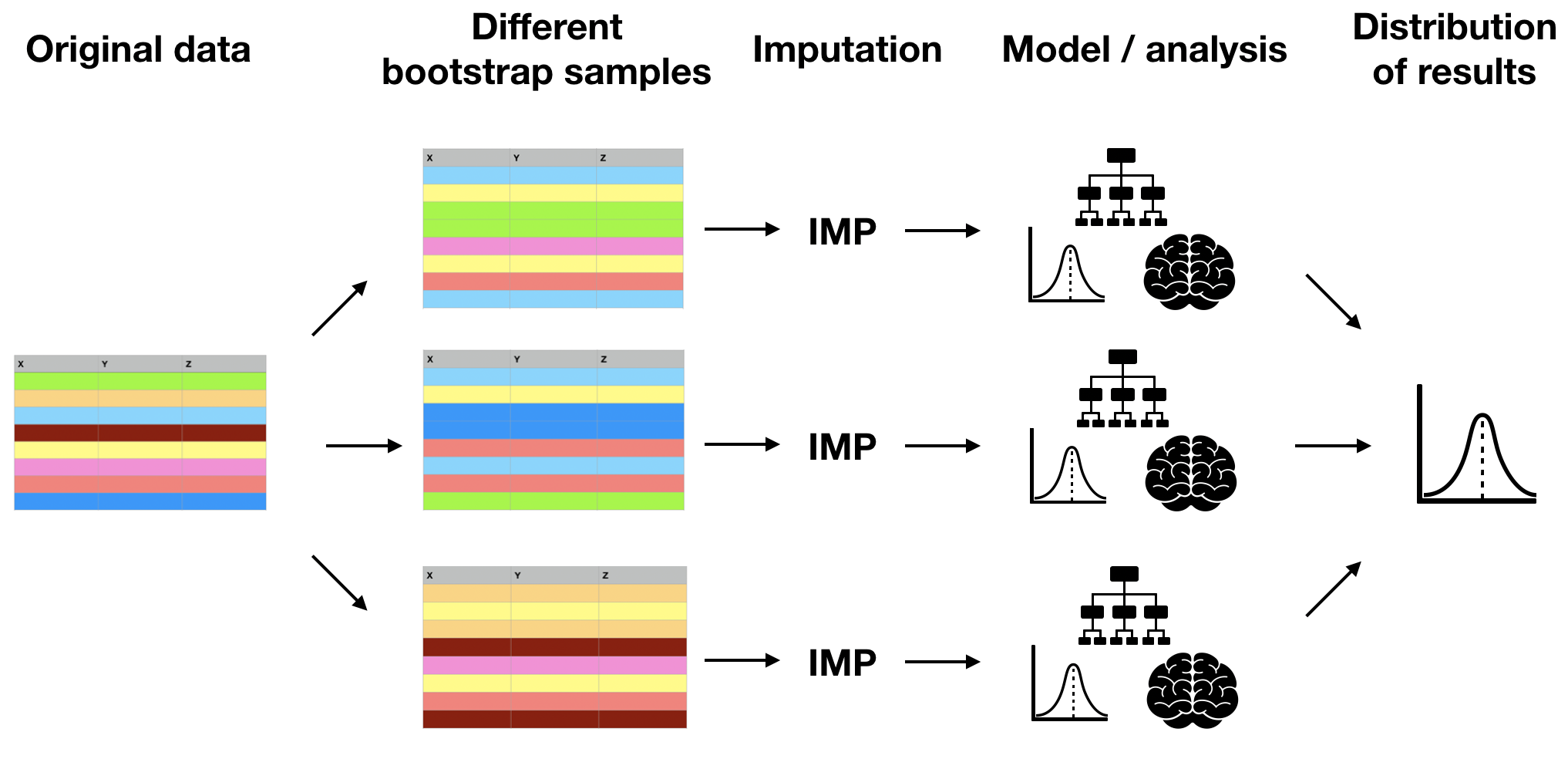
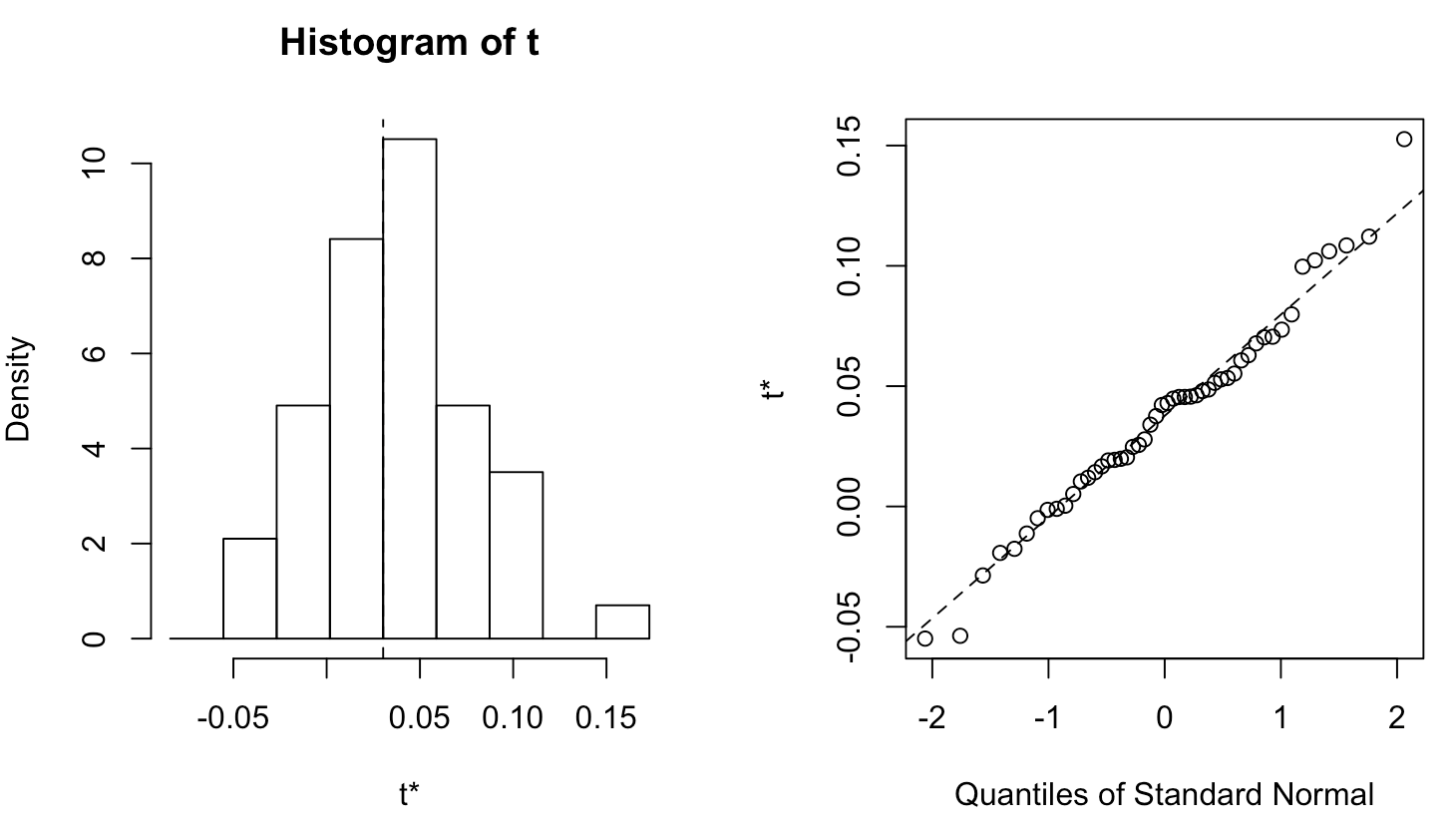
Grafico dei risultati bootstrap
plot(boot_results)