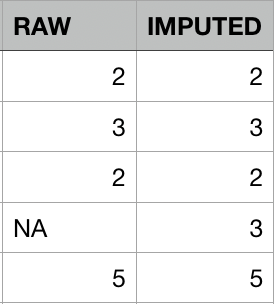
Imputazione con media
Gestione dei dati mancanti con imputazioni in R

Michal Oleszak
Machine Learning Engineer
Imputazione con media
L’imputazione con media funziona bene per serie temporali che oscillano casualmente attorno a una media di lungo periodo.
Per dati trasversali è spesso una scelta pessima:
- Distrugge le relazioni tra variabili.
- I valori imputati non hanno varianza.
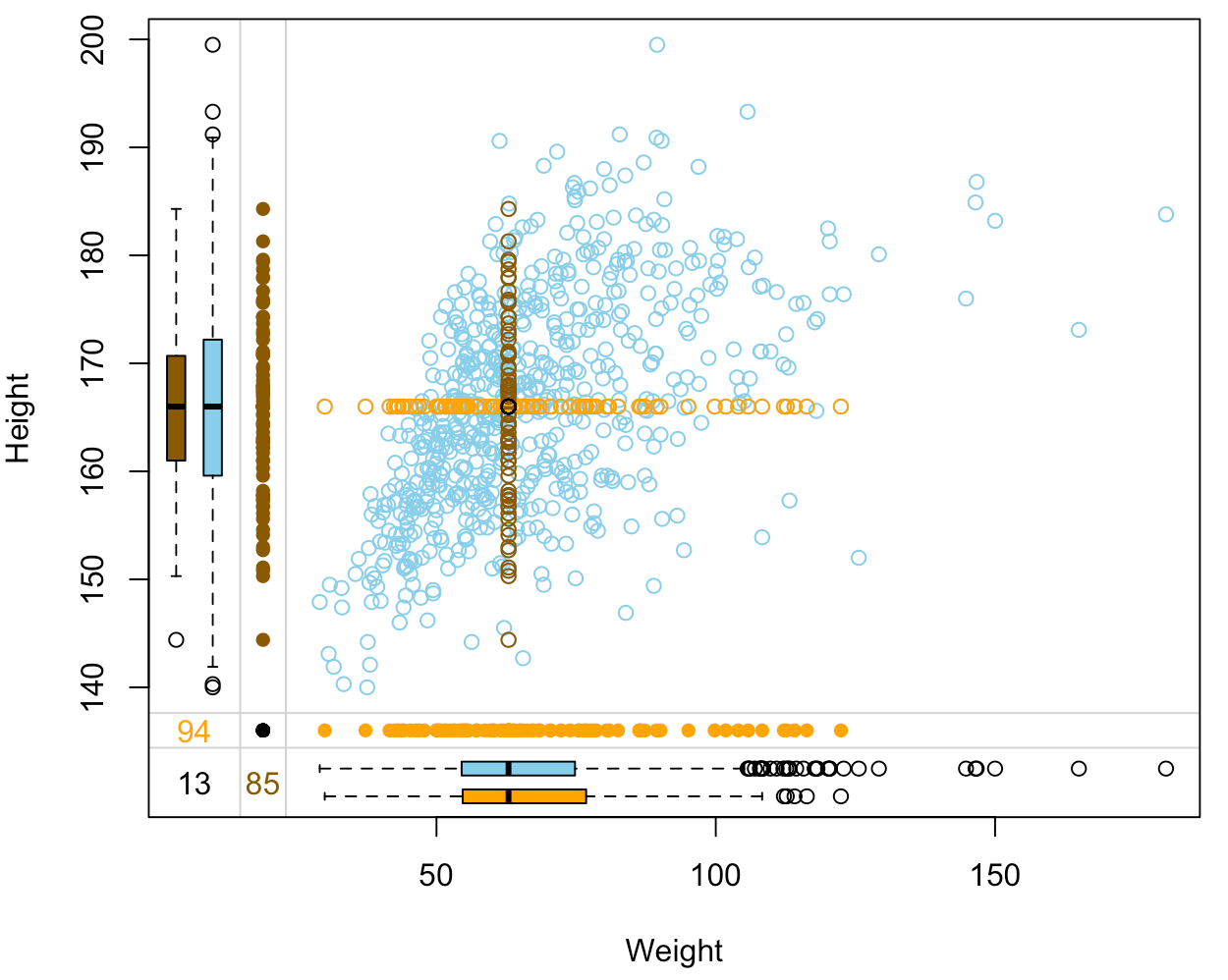
Valutare la qualità: margin plot
nhanes_imp %>% select(Weight, Height, Height_imp, Weight_imp) %>% marginplot(delimiter="imp")
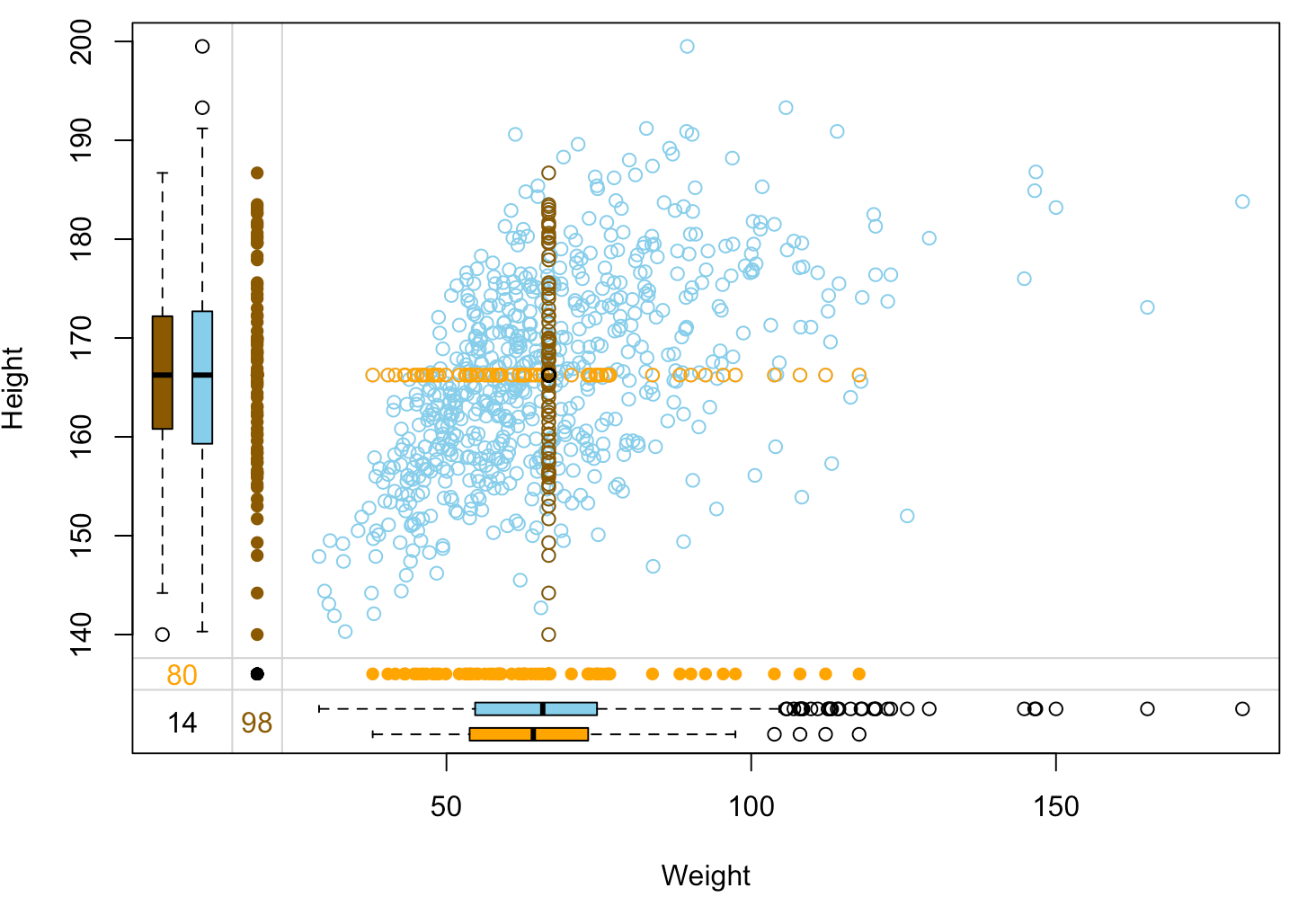
Imputazione con mediana e moda