Anonimizzare i dati categoriali
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Instructor
Generalizzazione
Age Gender Department Condition
0 30 F Finance Anxiety disorders
1 42 M Production Bronchitis
2 35 F Marketing Dysthymia
3 39 F Production Dysthymia
4 40 M Marketing Flu
Age Gender Department Condition
0 <40 F Finance Anxiety disorders
1 >=40 M Production Bronquitis
2 <40 F Finance Dysthymia
3 <40 F Production Dysthymia
4 >=40 M Marketing Flu
Generalizzazione dei dati categoriali
# Vedi il dataset
hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Life Sciences 2
2 37 Travel_Rarely Research & Development Other 4
3 33 Travel_Frequently Research & Development Life Sciences 5
4 27 Travel_Rarely Research & Development Medical 7
Dati categoriali
Numero limitato o fisso di valori possibili.
- razza
- genere
- città d’origine
- fascia d’età
- livello di istruzione
- film e preferenze
Anonimizzare i dati categoriali
Anonimizzare i dati categoriali
Department EducationField
0 Sales Life Sciences
1 Research & Development Life Sciences
2 Research & Development Other
3 Research & Development Life Sciences
4 Research & Development Medical
Dataset originale
Department EducationField
0 Sales Medical
1 Research & Development Marketing
2 Research & Development Life Sciences
3 Research & Development Other
4 Research & Development Life Sciences
Dataset risultante dopo il campionamento dalla distribuzione di probabilità della colonna educationField nel dataset originale.
Campionare dai dati
Il Census USA pubblica campioni dei dati raccolti sui cittadini.
Permette di calcolare pattern statistici su larga scala:
- medie
- varianze
- cluster
Esplora la distribuzione
# Mostra le frequenze assolute di ogni valore unico
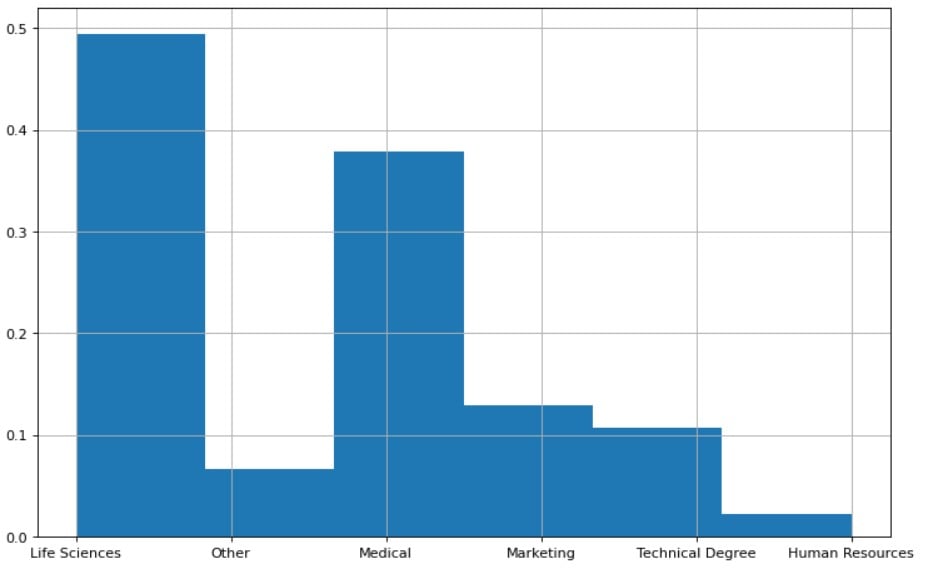
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
Esplora la distribuzione
# Genera un bar plot per le categorie
df['BusinessTravel'].value_counts().plot(kind='bar')
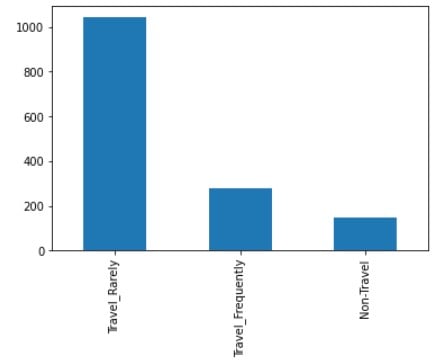
Esplora la distribuzione
# Ottieni le frequenze assolute di ogni valore unico
counts = hr['EducationField'].value_counts()
# Stampa la lista degli indici
print(counts.index)
Index(['Life Sciences', 'Medical', 'Marketing',
'Technical Degree', 'Other', 'Human Resources'],
dtype='object')
Esplora la distribuzione
# Distribuzioni di probabilità di ogni valore unico
counts = df['EducationField'].value_counts(normalize=True)
Life Sciences 0.412245
Medical 0.315646
Marketing 0.108163
Technical Degree 0.089796
Other 0.055782
Human Resources 0.018367
Name: EducationField, dtype: float64
Esplora la distribuzione
# Valori delle frequenze di ogni valore unico
df['EducationField'].value_counts(normalize=True).values
array([0.4122449 , 0.31564626, 0.10816327, 0.08979592, 0.05578231,
0.01836735])
Campionare dalla stessa distribuzione
# Campiona da una distribuzione di probabilità hr_sample['EducationField']= np.random.choice(counts.index, p=counts.values, size=len(hr))# Vedi il dataset risultante hr.head()
Age BusinessTravel Department EducationField EmployeeNumber
0 41 Travel_Rarely Sales Life Sciences 1
1 49 Travel_Frequently Research & Development Medical 2
2 37 Travel_Rarely Research & Development Marketing 4
3 33 Travel_Frequently Research & Development Technical Degree 5
4 27 Travel_Rarely Research & Development Medical 7
Campionare dalla stessa distribuzione
# Mostra le frequenze assolute di ogni categoria
hr['EducationField'].value_counts()
Life Sciences 606
Medical 464
Marketing 159
Technical Degree 132
Other 82
Human Resources 27
Name: EducationField, dtype: int64
# Mostra le frequenze della colonna risultante
hr_sample['EducationField'].value_counts()
Life Sciences 604
Medical 493
Marketing 158
Technical Degree 120
Other 61
Human Resources 34
Name: EducationField, dtype: int64
Ayo berlatih!
Riservatezza dei dati e anonimizzazione in Python

