Creare dataset sintetici con scikit-learn
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Data engineer
Generare dataset con Scikit-learn
Possiamo creare dataset campionati da distribuzioni di probabilità
Come la distribuzione normale
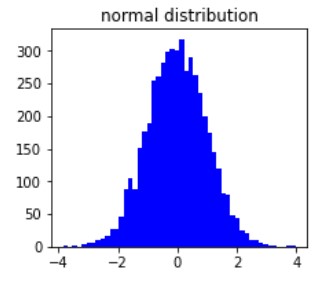
Distribuzione normale
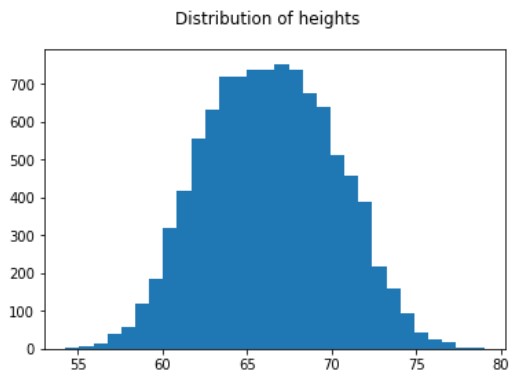
Campionare da una distribuzione normale
# Disegna l'istogramma per vedere la distribuzione delle altezze
new_measures['Height'].hist(bins=50)
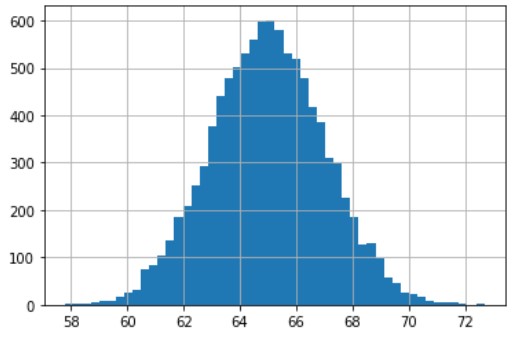
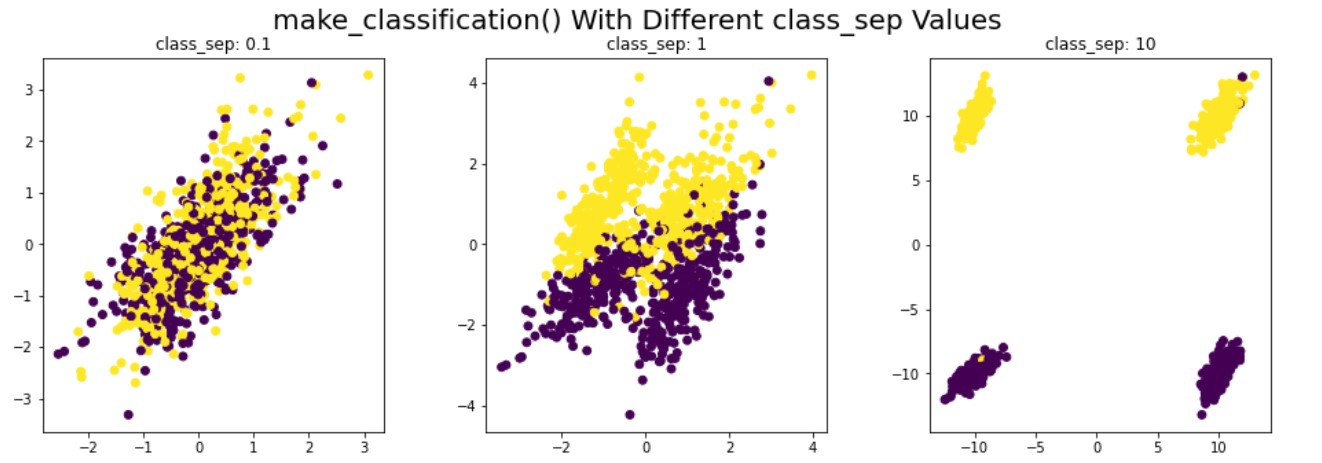
Dati sintetici per la classificazione
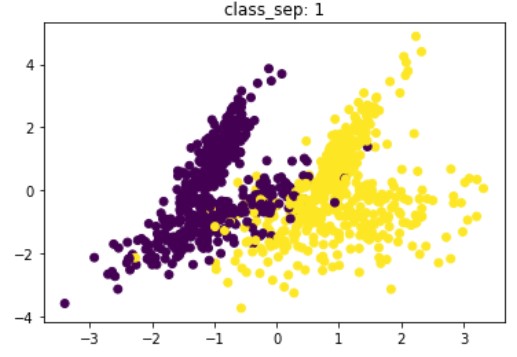
Dati sintetici per la classificazione
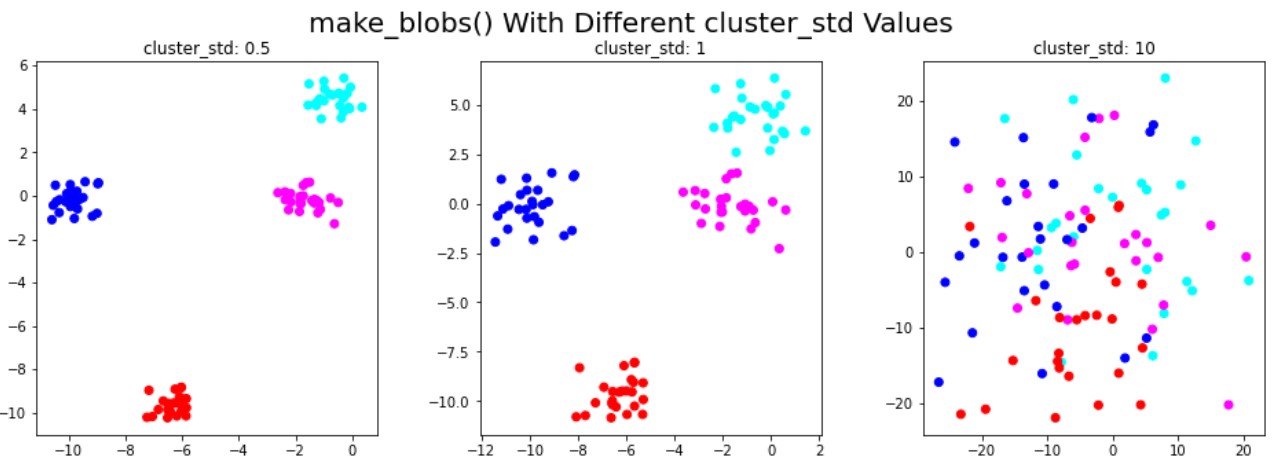
Dati sintetici per il clustering
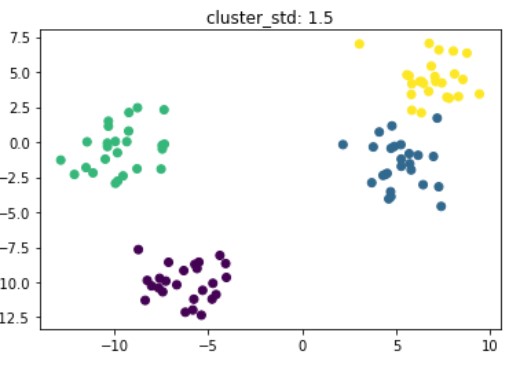
Dati sintetici per il clustering