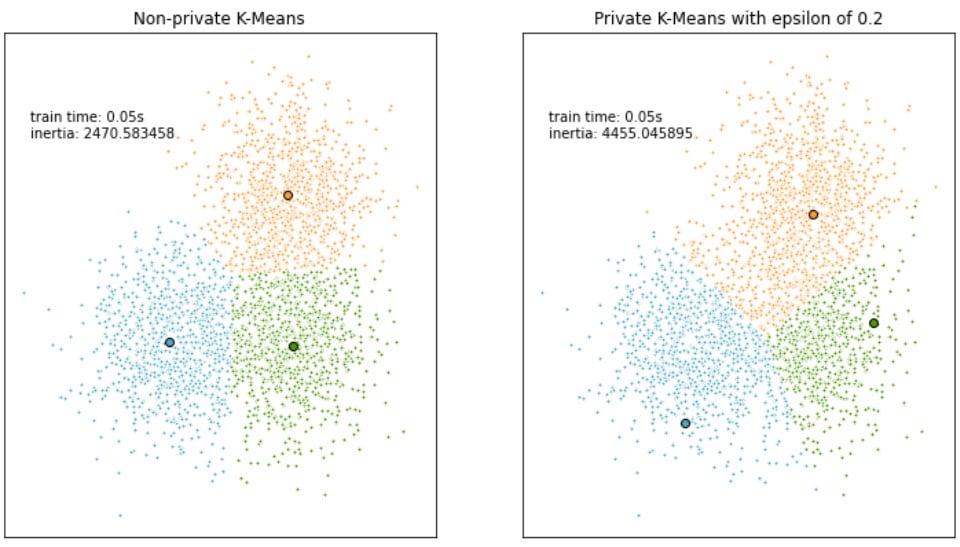
Modelli di clustering differenzialmente privati
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Data engineer
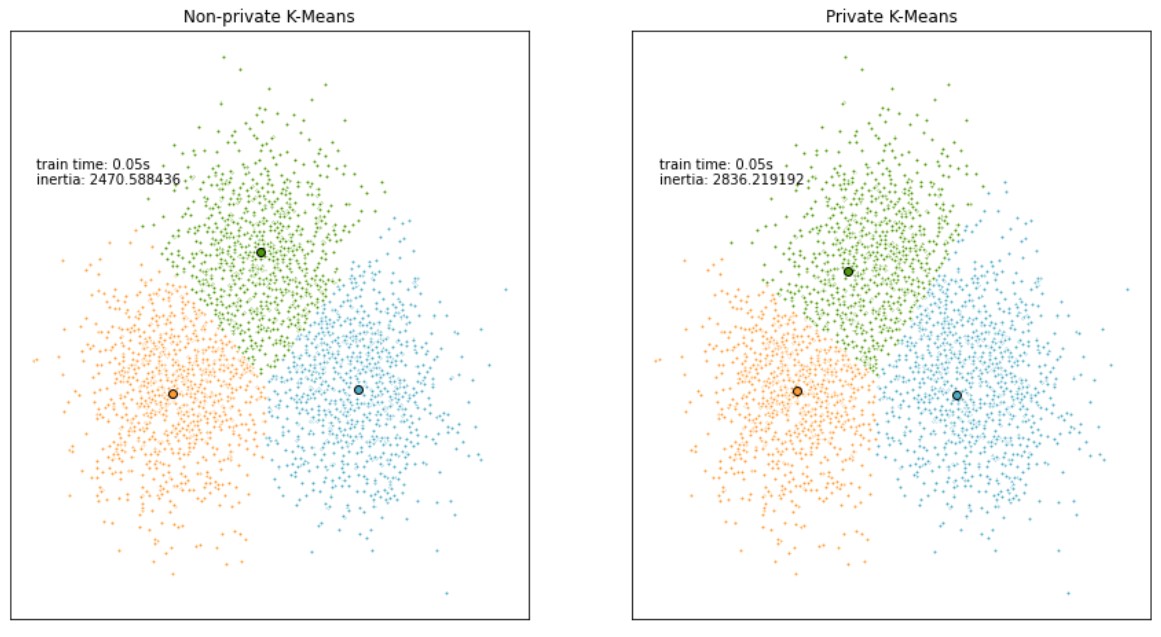
Confronto dei modelli
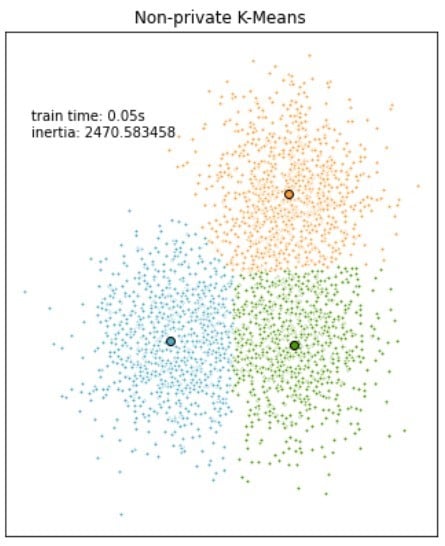
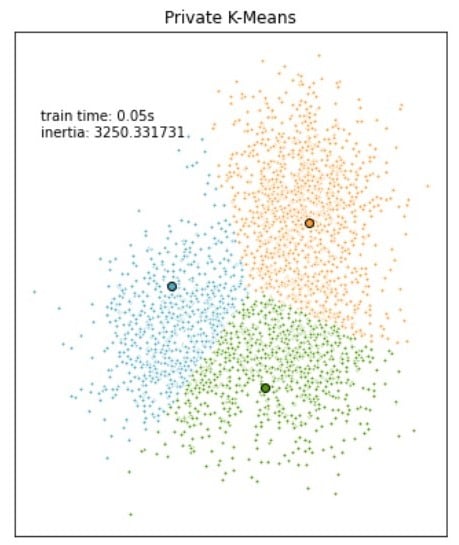
Confronto tra i modelli
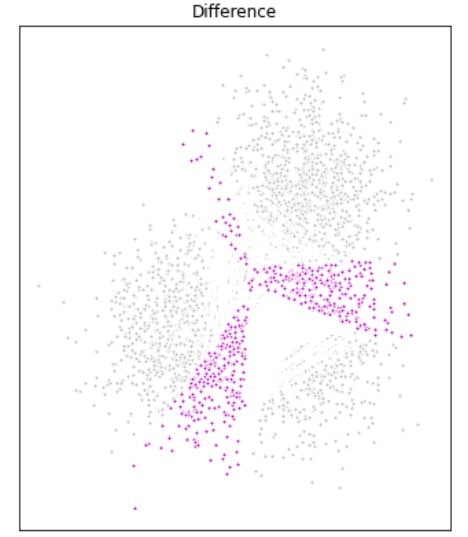
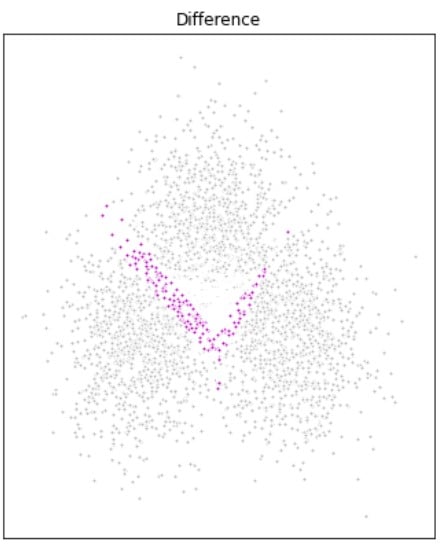
Migliorare i modelli DP di clustering
Migliorare i modelli DP di clustering
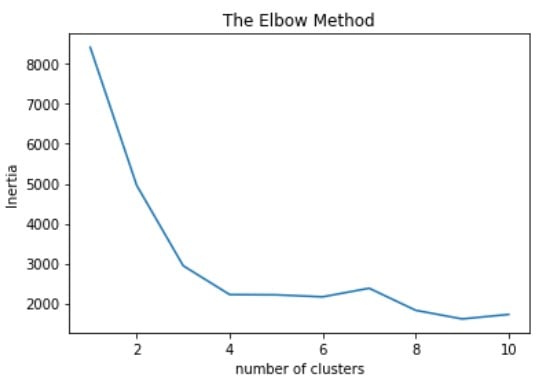
Elbow method
Epsilon