Modelli di machine learning con privacy differenziale
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Data Engineer
Condividere dati in modo sicuro
Aziende con dati simili che condividono info per migliorare prodotti e servizi.
- Inclusi i modelli di Machine Learning (ML)

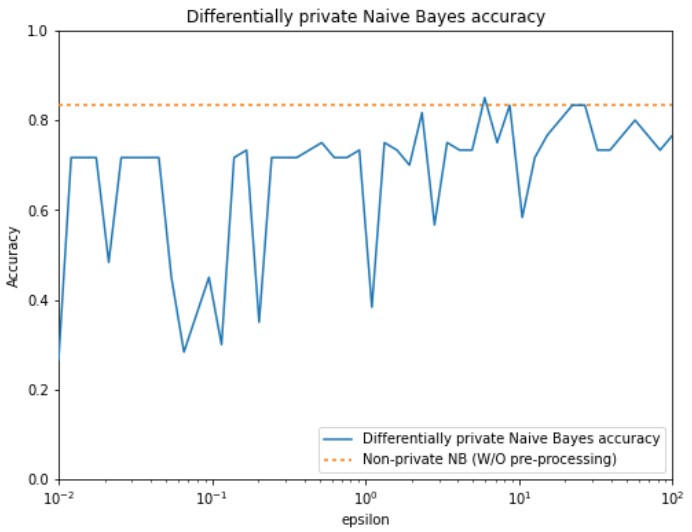
Modelli di machine learning con privacy differenziale
- Azienda SaaS con più negozi online partner.
- Quando arriva un nuovo partner, servono mesi per raccogliere dati a sufficienza
- Con la DP, l’azienda può incoraggiare i partner a condividere dati

$$
$$

Valori diversi di epsilon