PCA per l’anonimizzazione
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Data engineer
Analisi delle componenti principali (PCA)
$$ $$ Metodo di riduzione della dimensionalità, spesso usato per ridurre la dimensionalità di dataset grandi.
Mascheramento dati con PCA
La PCA crea nuove “componenti principali” da trasformazioni lineari delle feature originali.
In un dataset di birre, la PCA costruisce nuove feature. Per esempio:
$$ 2\times AlcoholicVolume - BitternessLevel$$
Mascheramento dati con PCA
Nuove proiezioni dei dati
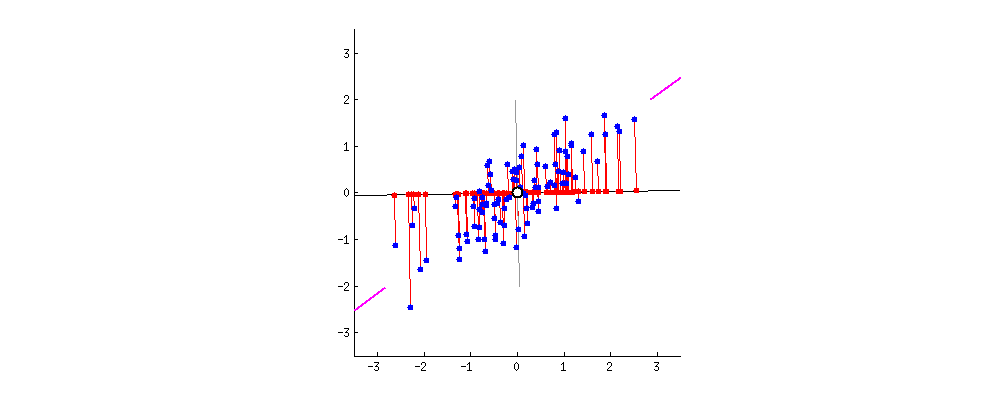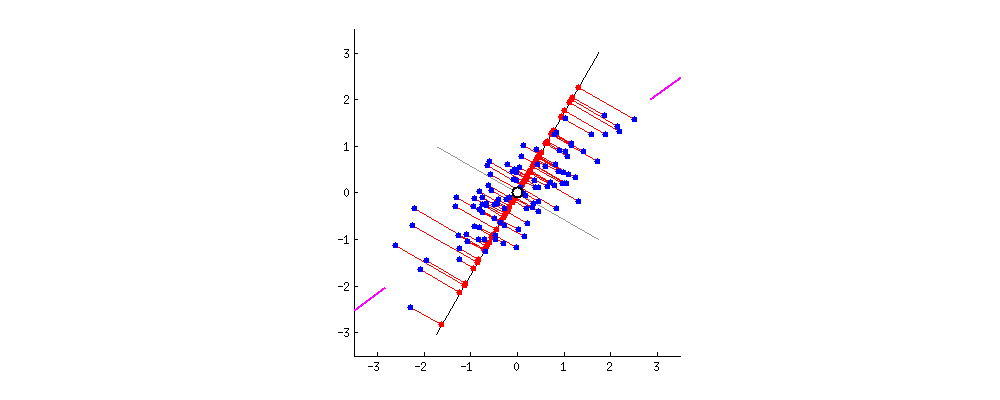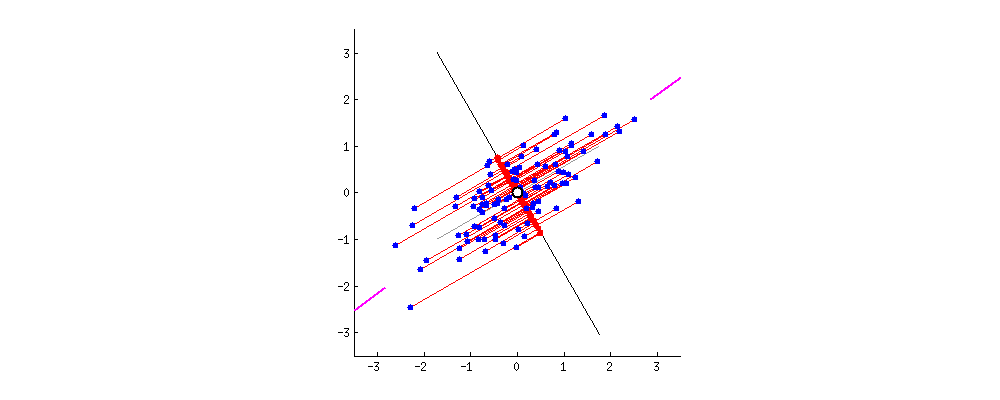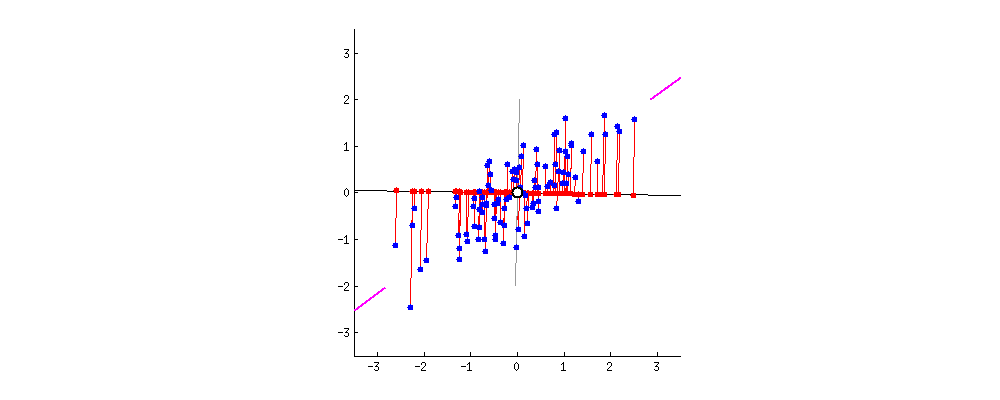
Mascheramento dati con PCA
PCA senza riduzione della dimensionalità
$$
- È solo una rotazione dello spazio originale del dataset.
- Le distanze vengono preservate.
- Un vantaggio per compiti e algoritmi predittivi.
Mascheramento dati con PCA
- Se quei valori risultanti vengono pubblicati senza spiegazioni, si possono comunque addestrare algoritmi e ottenere previsioni accurate.
- Gli avversari non saprebbero interpretare quei valori mascherati.
Mascheramento dati con PCA
# Esplora il dataset
heart_df.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target
0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1
1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1
2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1
3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1
4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1
Mascheramento dati con PCA e Scikit-learn
# Ottieni i dati senza la colonna target x_data = df.drop(['target'], axis = 1)# Colonna target come array di valori y = df.target.values
Mascheramento dati con PCA e Scikit-learn
# Importa PCA da Scikit-learn from sklearn.decomposition import PCA# Inizializza PCA con numero di componenti uguale al numero di colonne pca = PCA(n_components=len(x_data.columns))# Applica PCA ai dati x_data_pca = pca.fit_transform(x_data)
Mascheramento dati con PCA e Scikit-learn
# Vedi i dati
x_data_pca
array([[-1.22673448e+01, 2.87383781e+00, 1.49698788e+01, ...,
7.31102828e-01, -2.90393586e-01, 5.12575925e-01],
[ 2.69013712e+00, -3.98713736e+01, 8.77882303e-01, ...,
4.04206943e-01, -4.25920179e-01, -1.48124511e-01],
[-4.29502141e+01, -2.36368199e+01, 1.75944589e+00, ...,
-9.15397287e-01, 2.17828257e-01, 7.97593843e-02],
...,
Mascheramento dati con PCA e Scikit-learn
# Crea un DataFrame dai dati trasformati con PCA df_x_data_pca = pd.DataFrame(x_data_pca)# Controlla la shape del dataset df_x_data_pca.shape
(1213, 13)
Utilità dei dati dopo mascheramento PCA
- Esegui una classificazione con regressione logistica e verifica la perdita di accuratezza confrontando dati originali e risultanti.
$$
- La regressione logistica è un algoritmo di classificazione per predire un esito binario da variabili indipendenti.
Utilità dei dati dopo mascheramento PCA
Esegui una classificazione con regressione logistica e verifica la perdita di accuratezza.
# Dividi il dataset risultante in train e test x_train, x_test, y_train, y_test = train_test_split(x_data_pca, y, test_size=0.2)# Crea il modello lr = LogisticRegression(max_iter=200)# Allena il modello lr.fit(x_train,y_train)# Esegui il modello e ottieni l’accuracy acc = lr.score(x_test, y_test) * 100 print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Utilità dei dati prima del mascheramento PCA
Esegui una classificazione con regressione logistica e confronta lo score con i dati originali
# Dividi il dataset risultante in train e test
x_train, x_test, y_train, y_test = train_test_split(x_data.to_numpy(),y,test_size = 0.2)
# Crea il modello
lr = LogisticRegression(max_iter=200)
# Allena il modello
lr.fit(x_train,y_train)
# Esegui il modello e ottieni l’accuracy
acc = lr.score(x_test,y_test) * 100
print("Test Accuracy is ", acc)
Test Accuracy is 85.24590163934425
Passons à la pratique !
Riservatezza dei dati e anonimizzazione in Python

