Introduzione alla k-anonymity
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Data engineer
Perché la k-anonymity è importante?

Perché è importante?
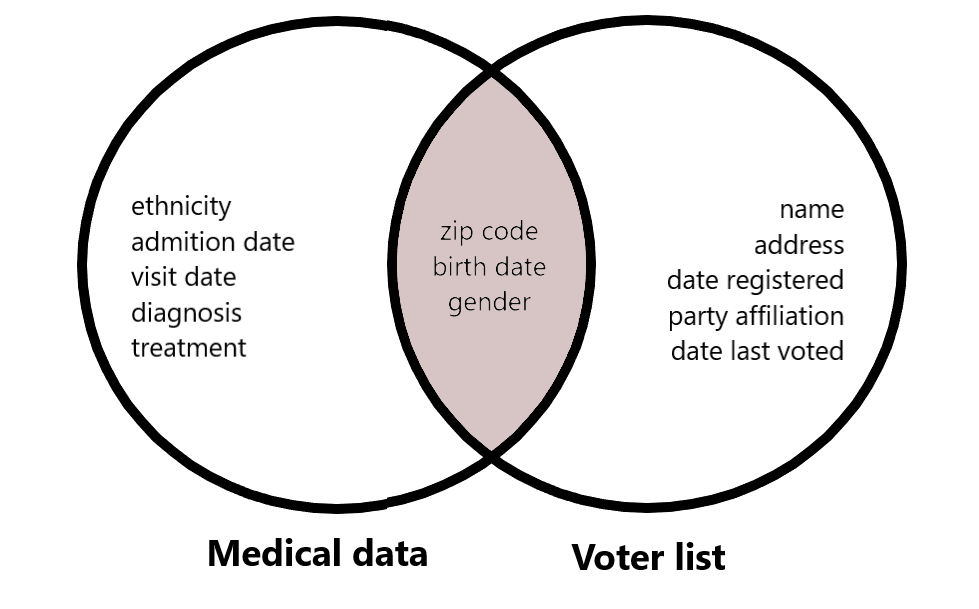
Definizione di k-anonymity

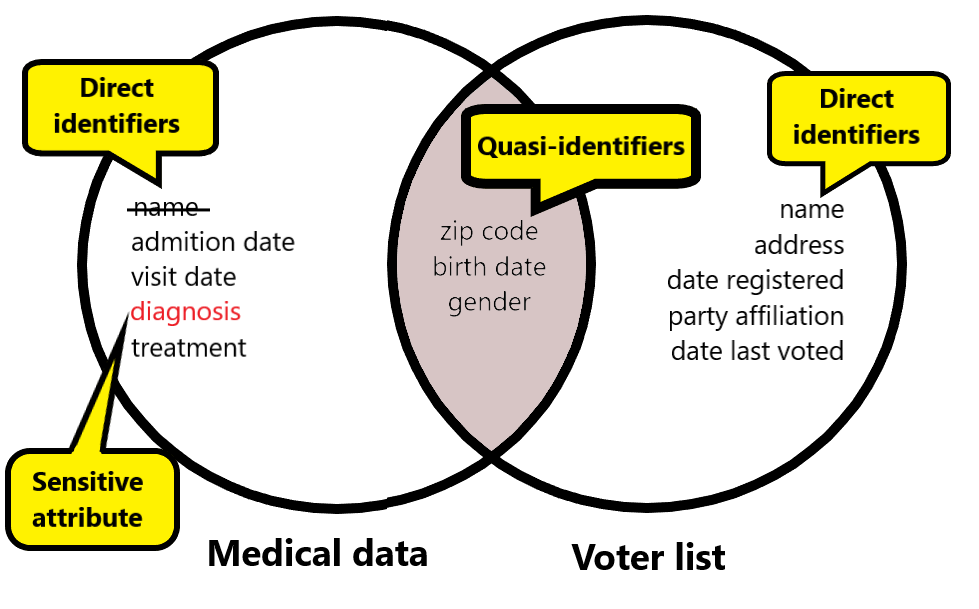
K-anonymity: terminologia
Riservatezza dei dati e anonimizzazione in Python
Rebeca Gonzalez
Data engineer

