Anonimizzazione con generalizzazione dei dati
Riservatezza dei dati e anonimizzazione in Python

Rebeca Gonzalez
Data engineer
Aggregazione dei dati
Dataset medico
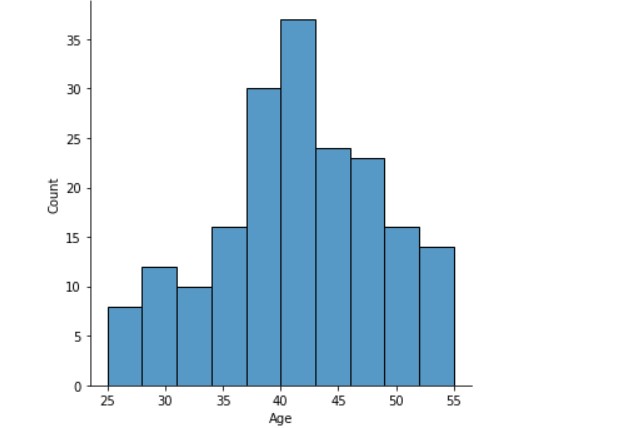
# Esplora l'istogramma della variabile età
df_medical['age'].hist(bins=15)
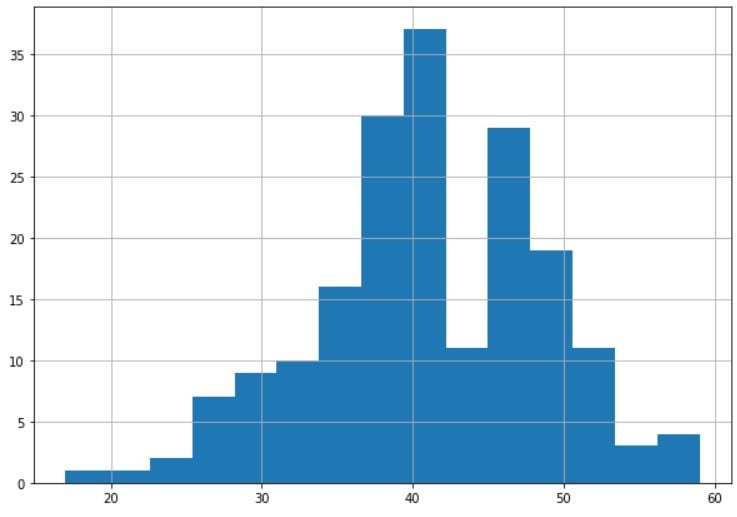
Top e bottom coding
# Esplora l'istogramma della variabile età
df_medical['age'].hist(bins=15)
Bottom coding
# Esplora l'istogramma della variabile età
df_medical['age'].hist(bins=15)
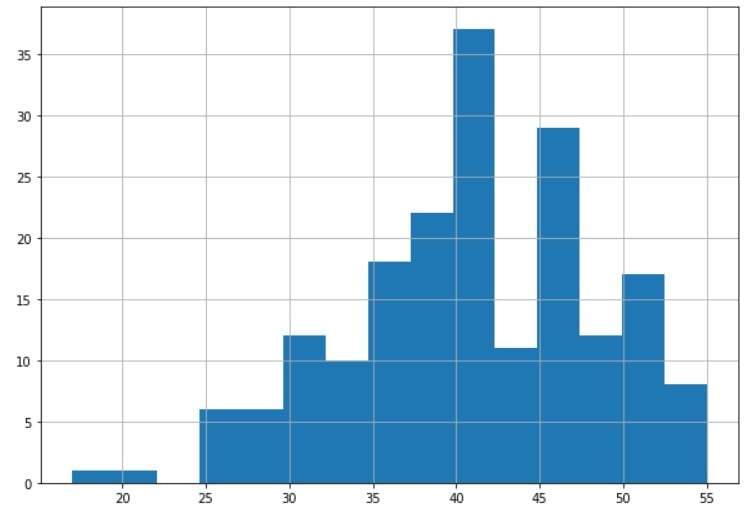
Bottom code
# Bottom code dell'età a 25 df_medical.loc[df['age'] < 25, 'age'] = 25# Esplora l'istogramma della variabile età df_medical['age'].hist(bins=15)