Gestire dataset sbilanciati
Rilevamento delle frodi in R

Bart Baesens
Professor Data Science at KU Leuven
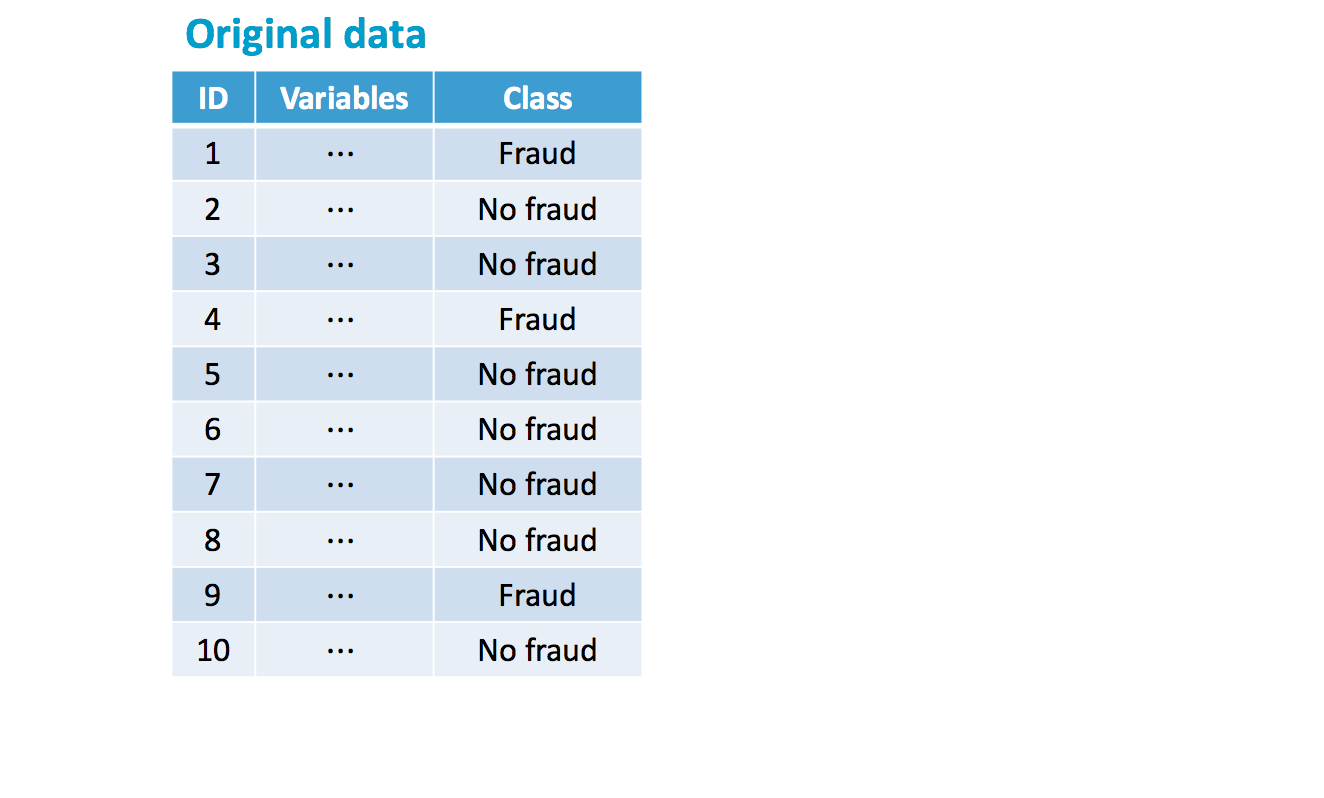
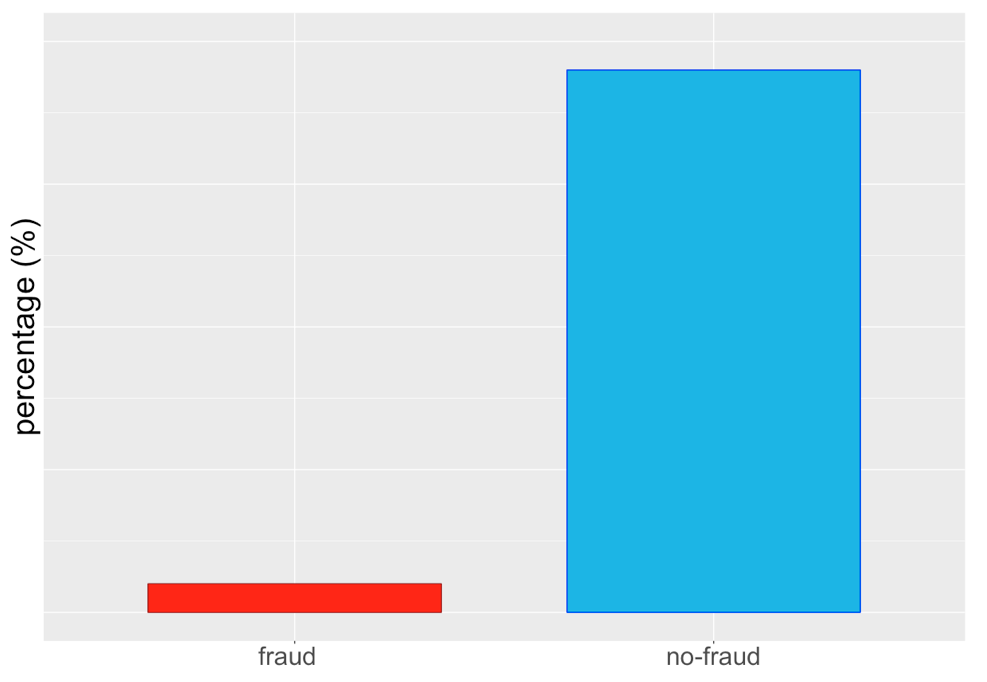
Dataset sbilanciati

Dataset sbilanciati

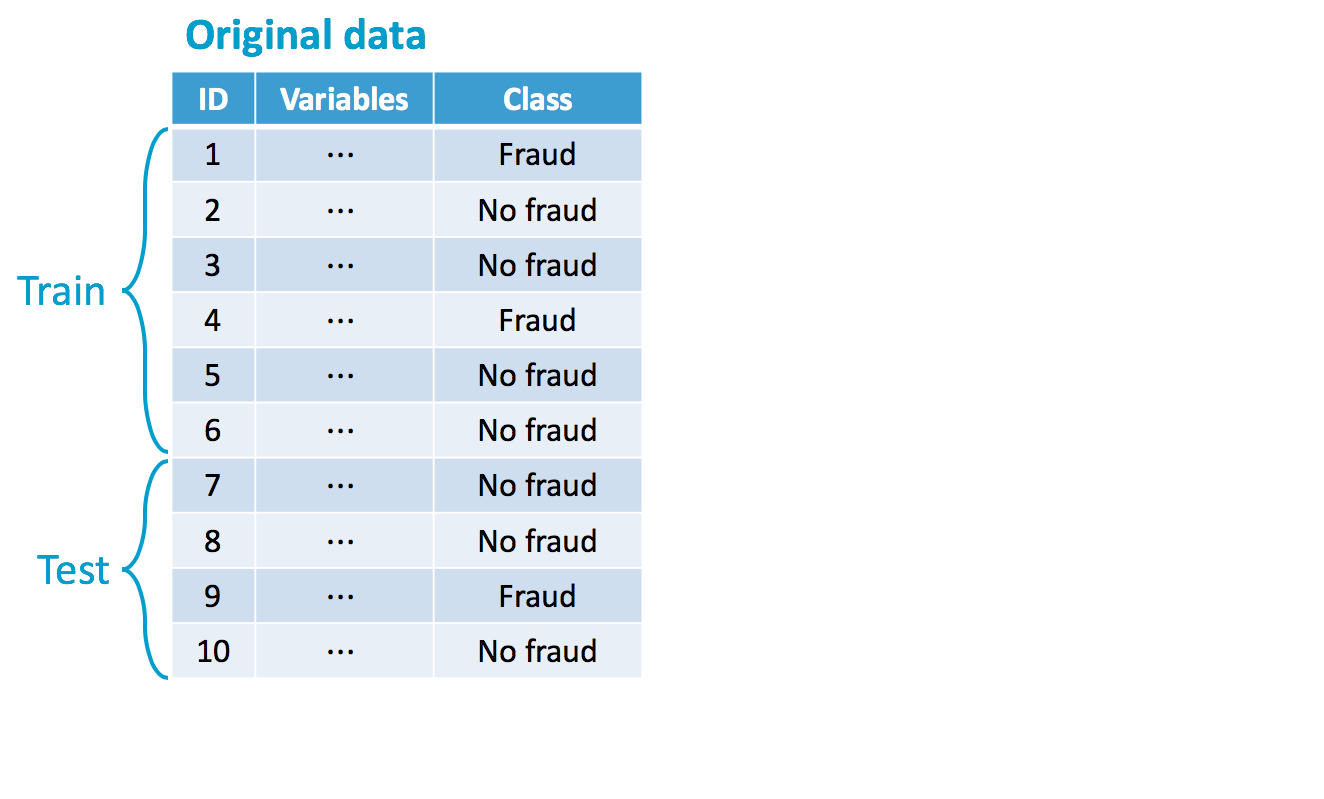
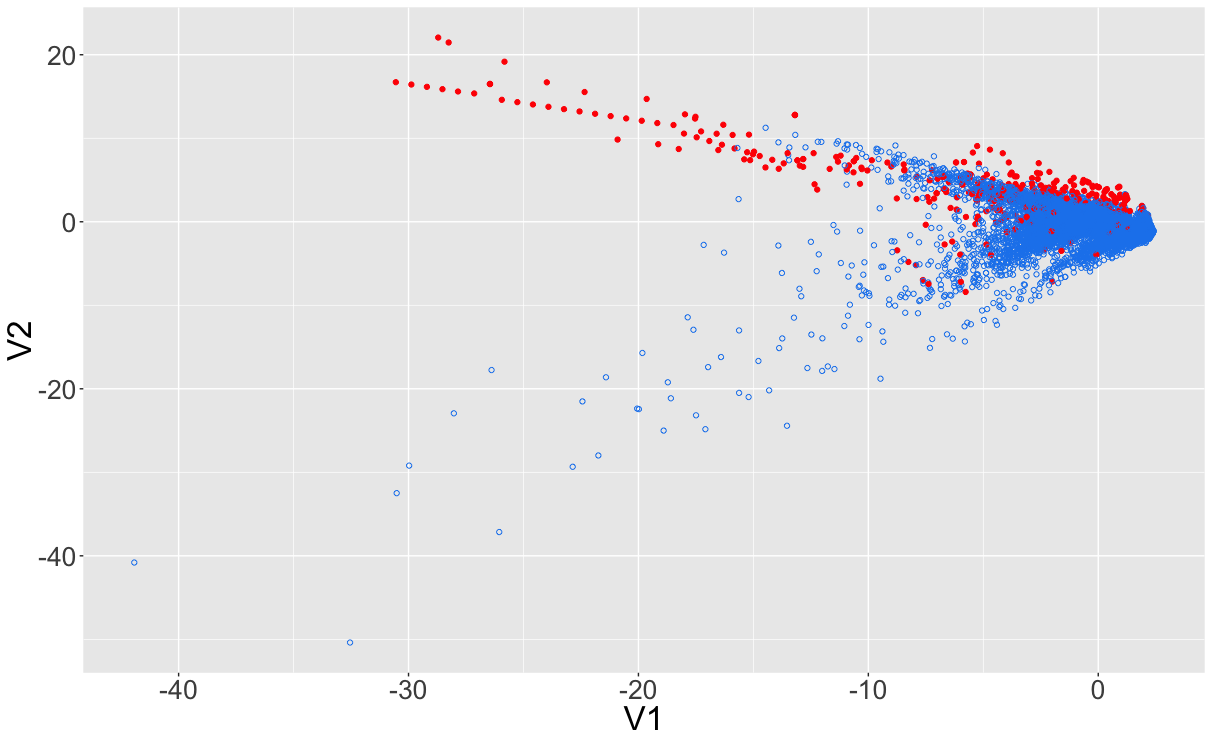
Sbilanciamento iniziale
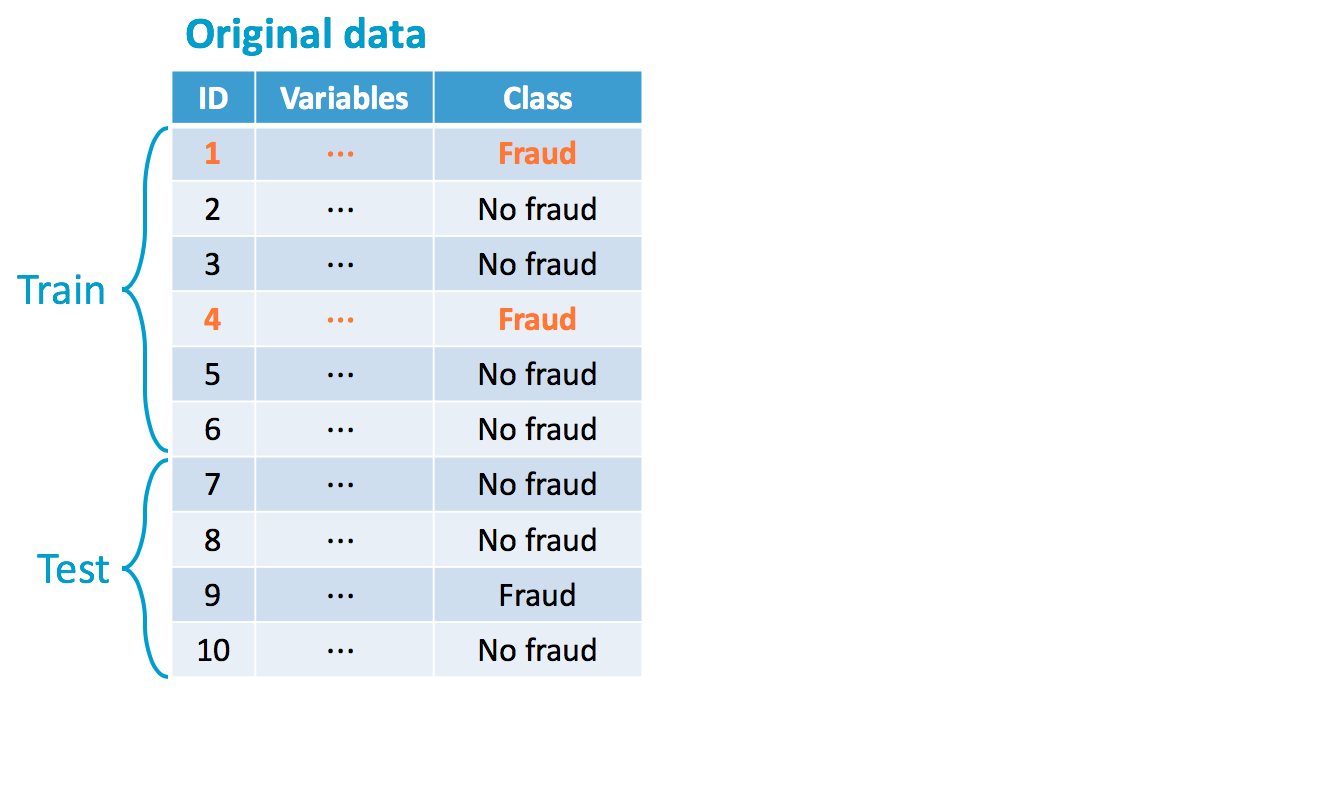
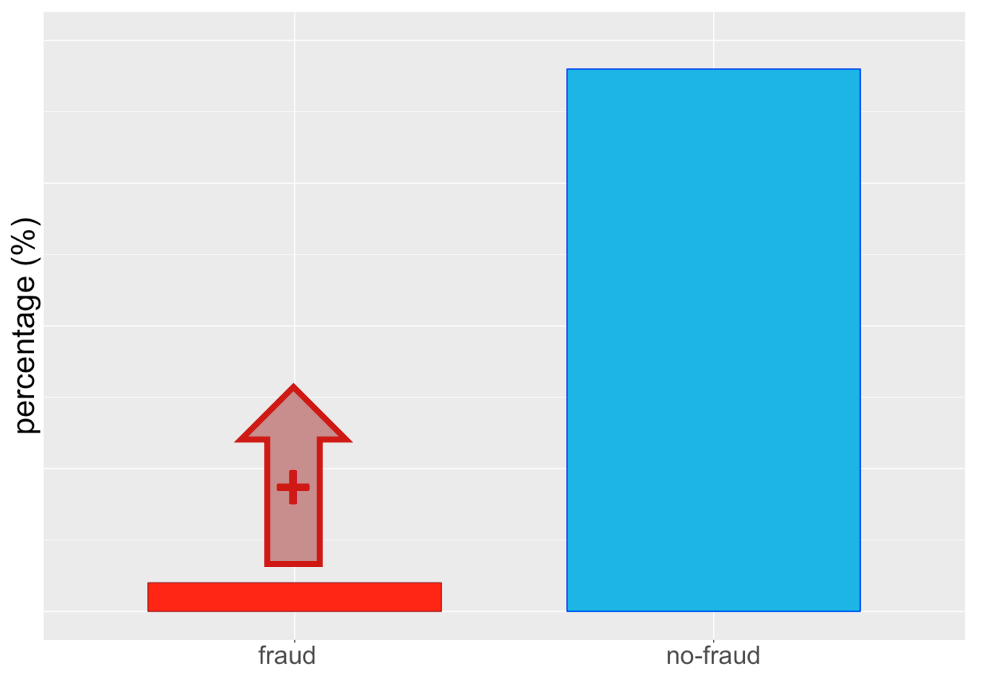
Over-sampling della classe minoritaria...
... o sotto-campionare la classe maggioritaria ...
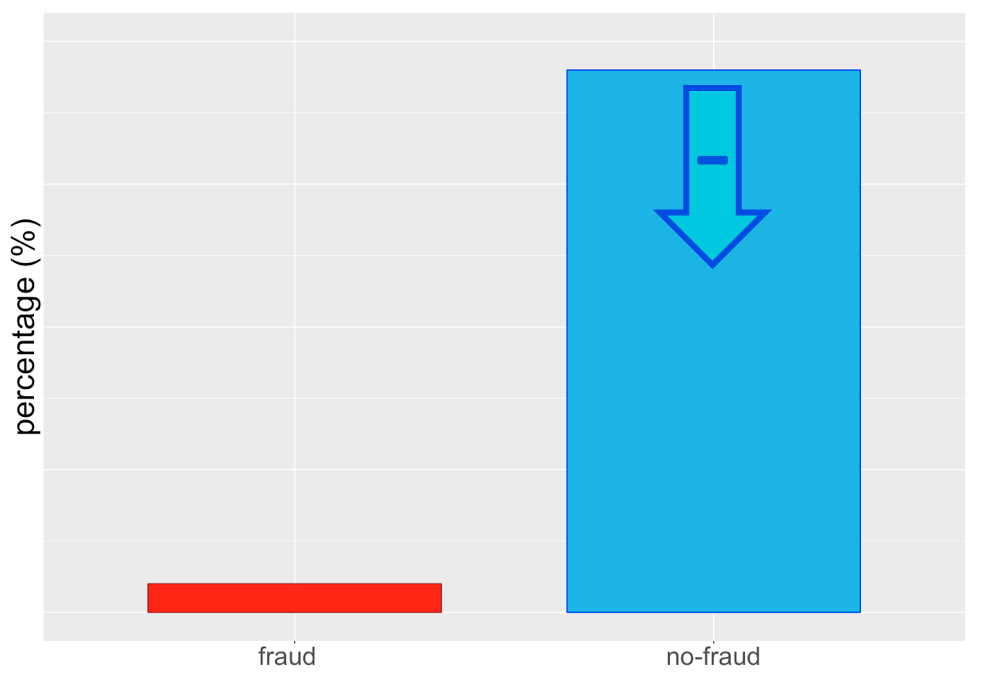
... o entrambi!
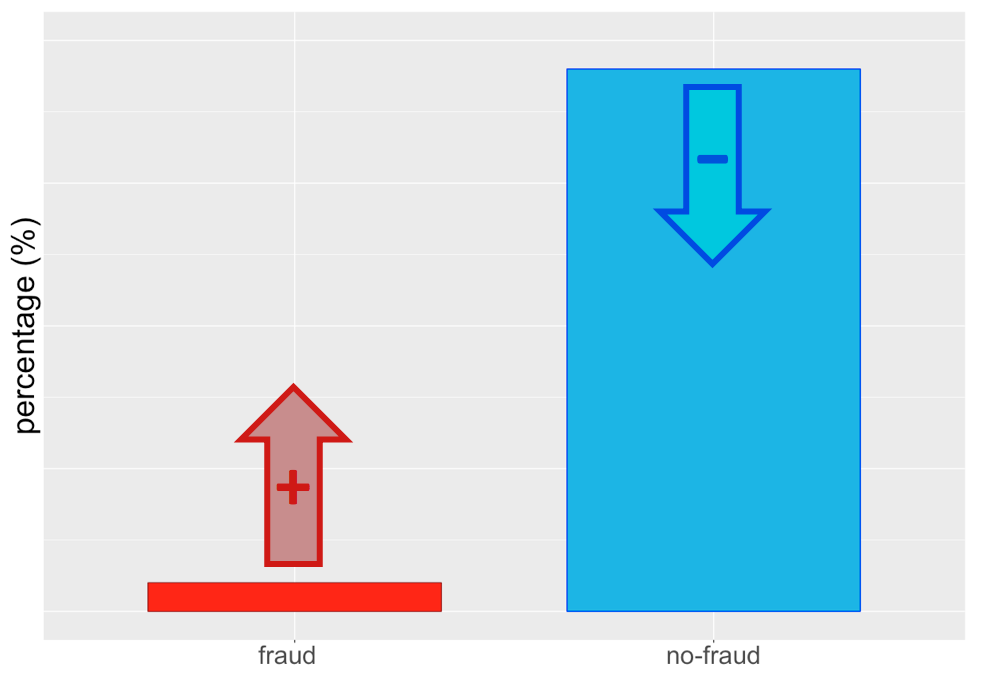
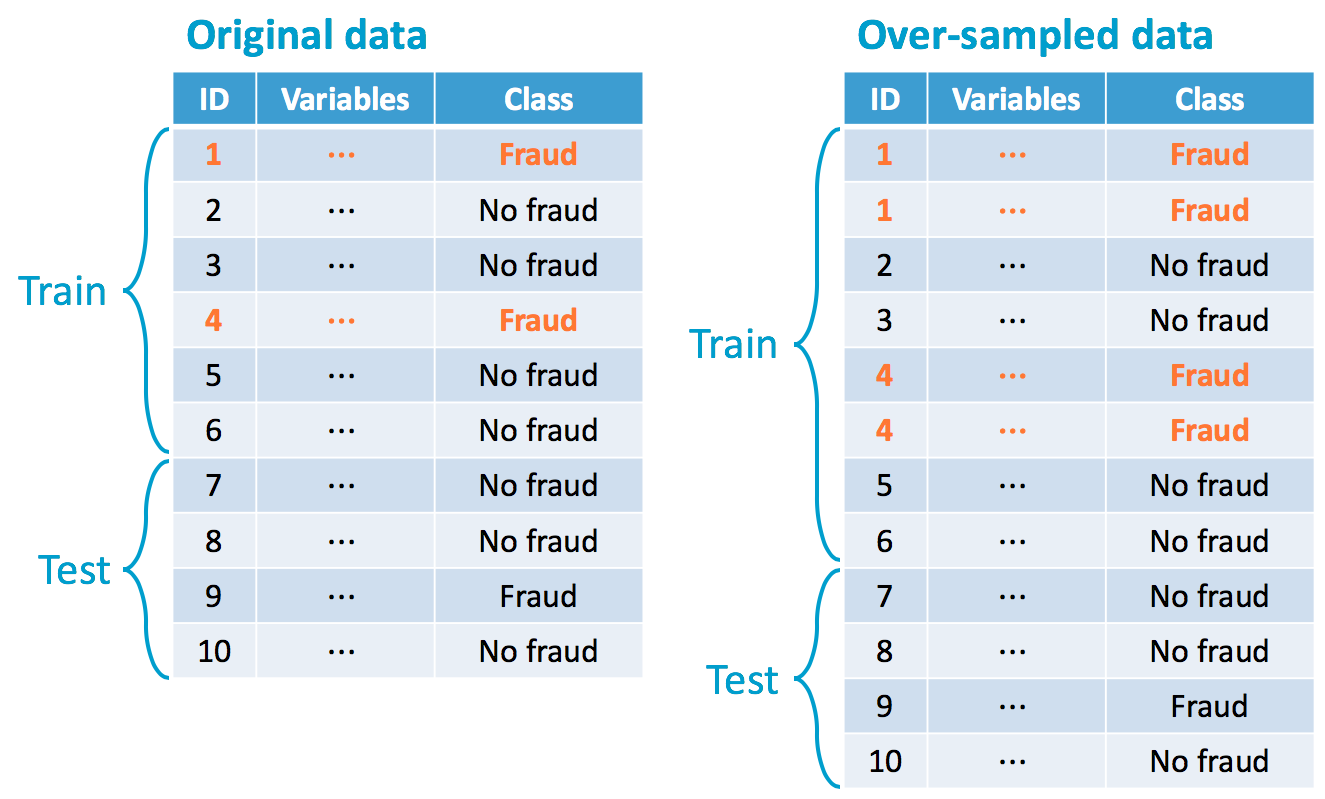
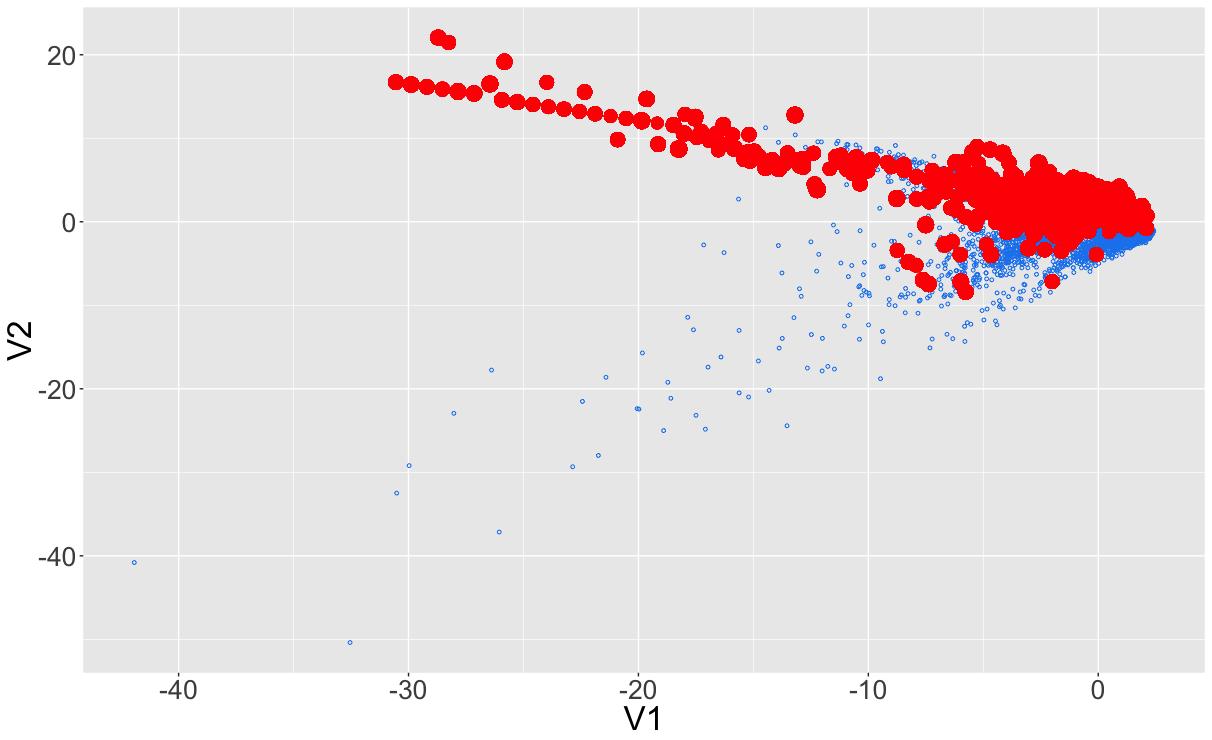
Risultato dopo il campionamento...
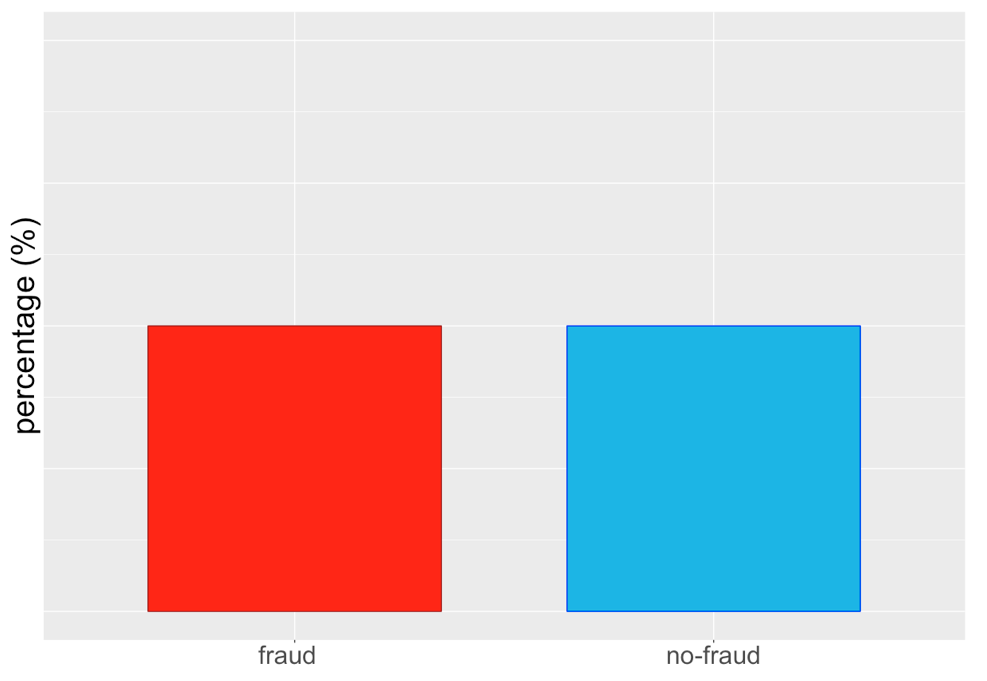
... o così
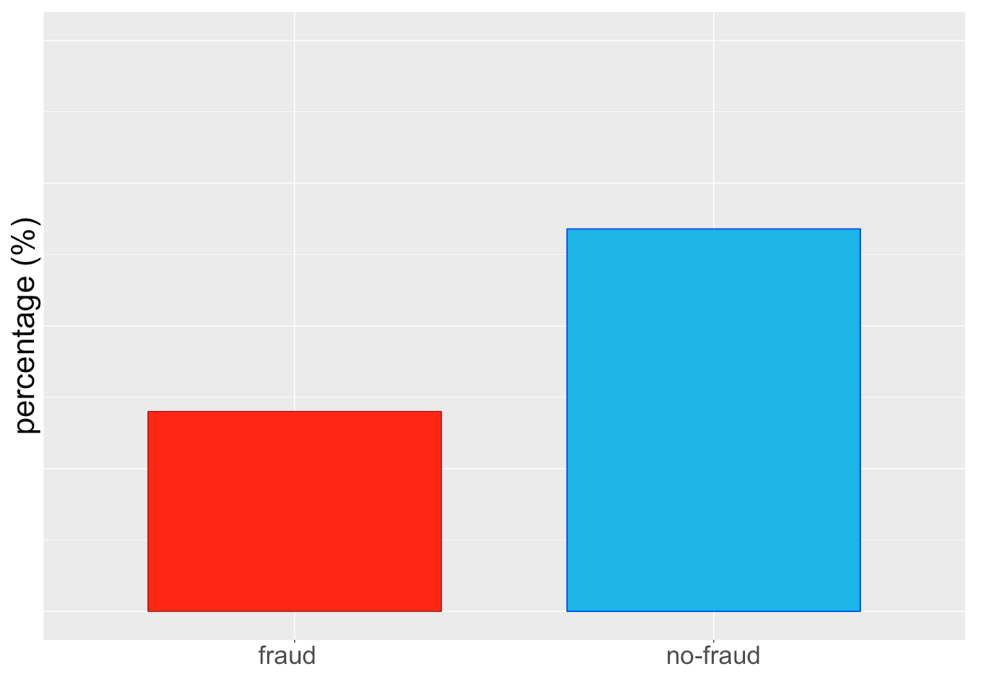
Random over-sampling (ROS)