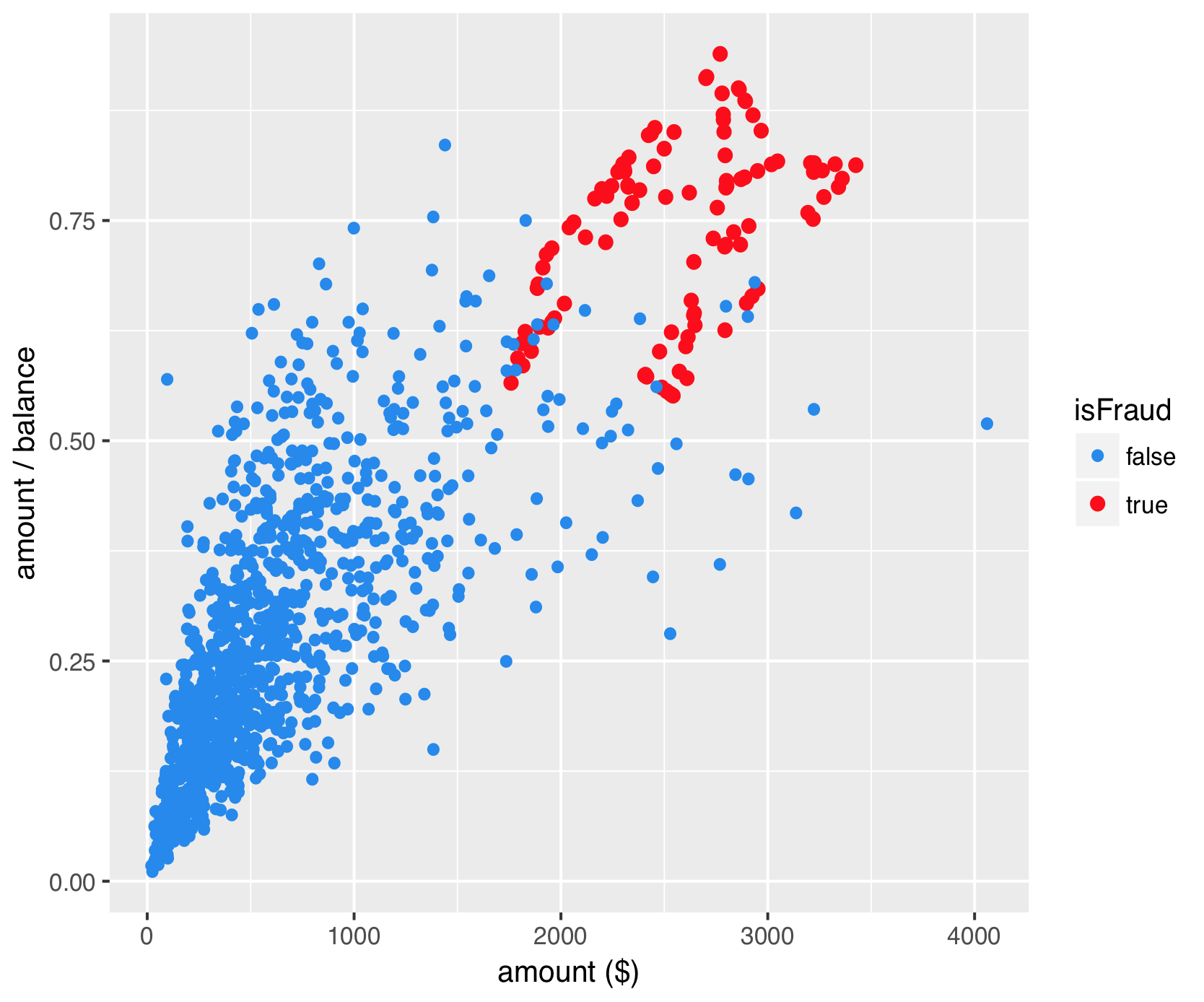
Sovracampionamento sintetico
Rilevamento delle frodi in R

Sebastiaan Höppner
PhD researcher in Data Science at KU Leuven
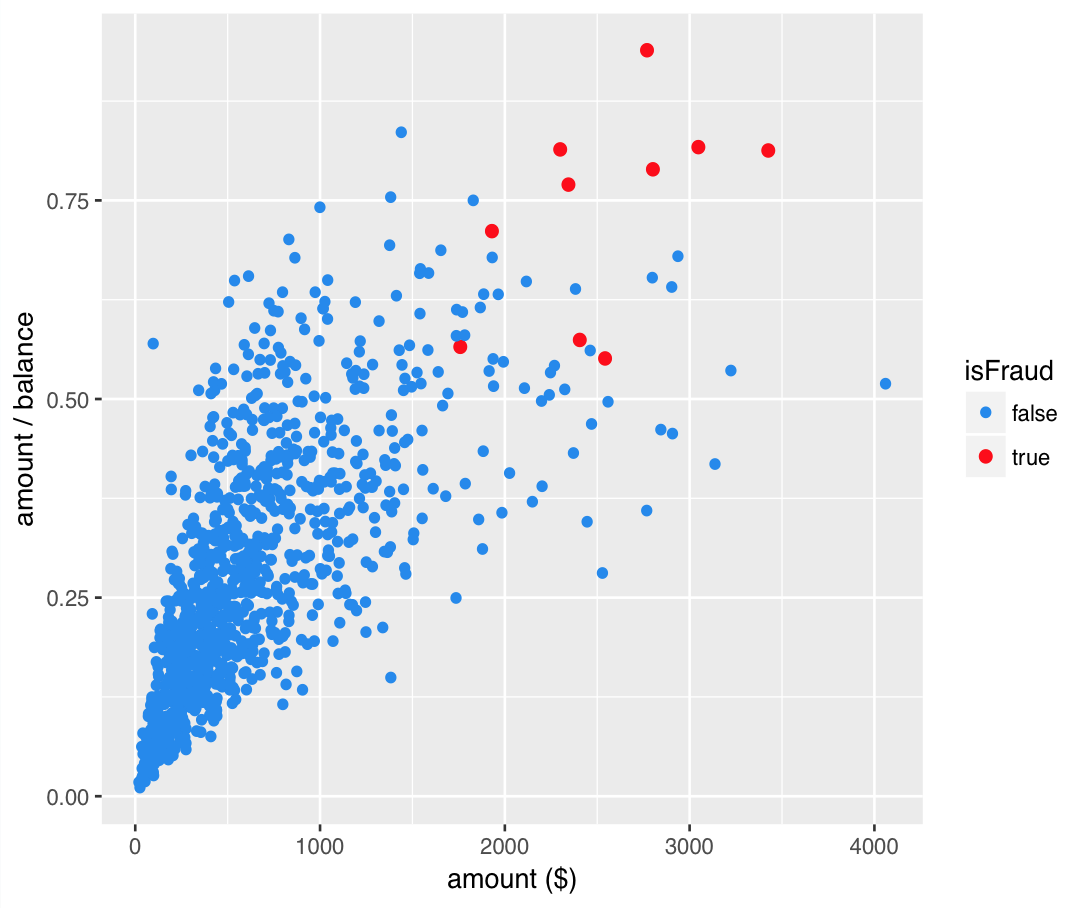
SMOTE
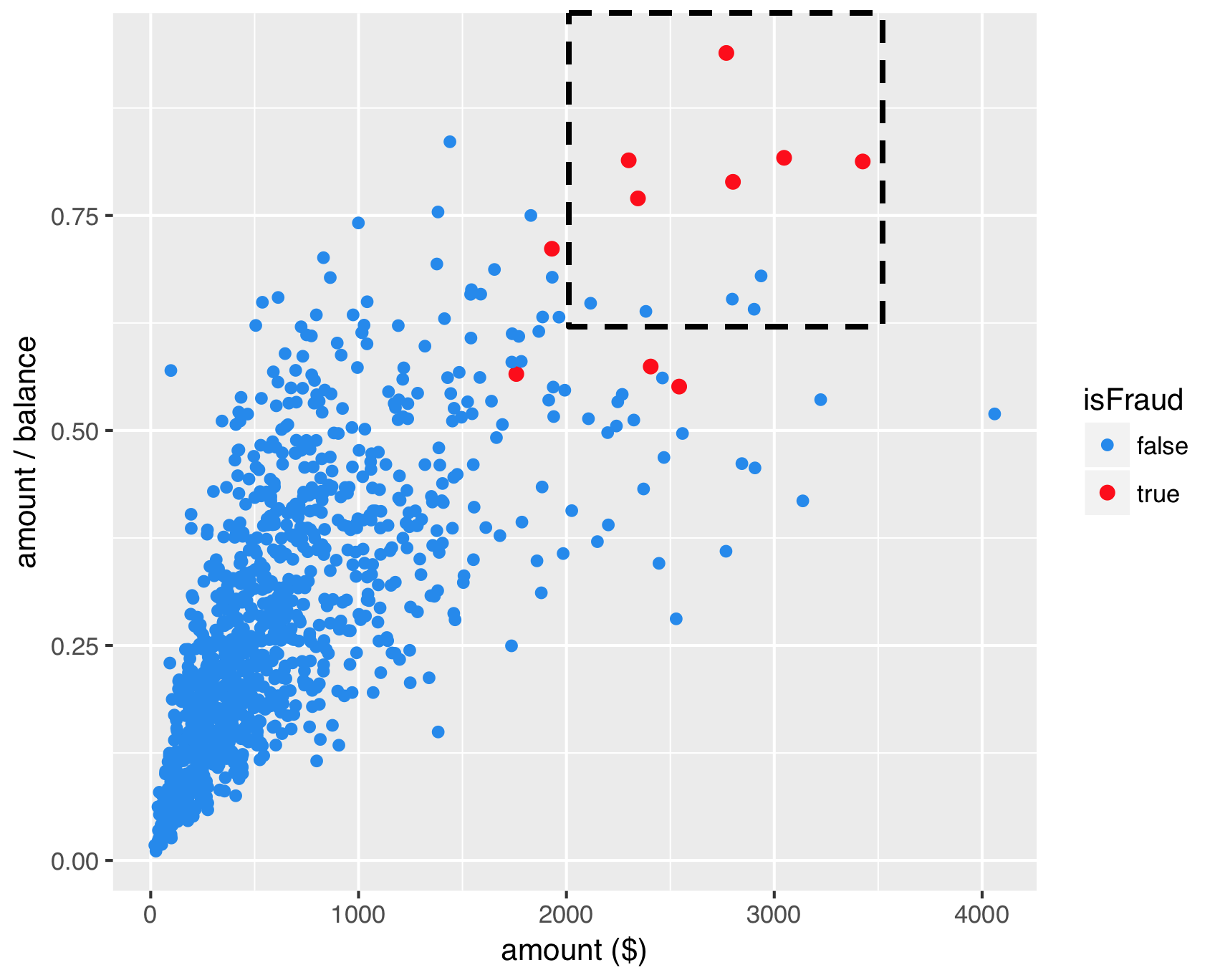
SMOTE - passo 1
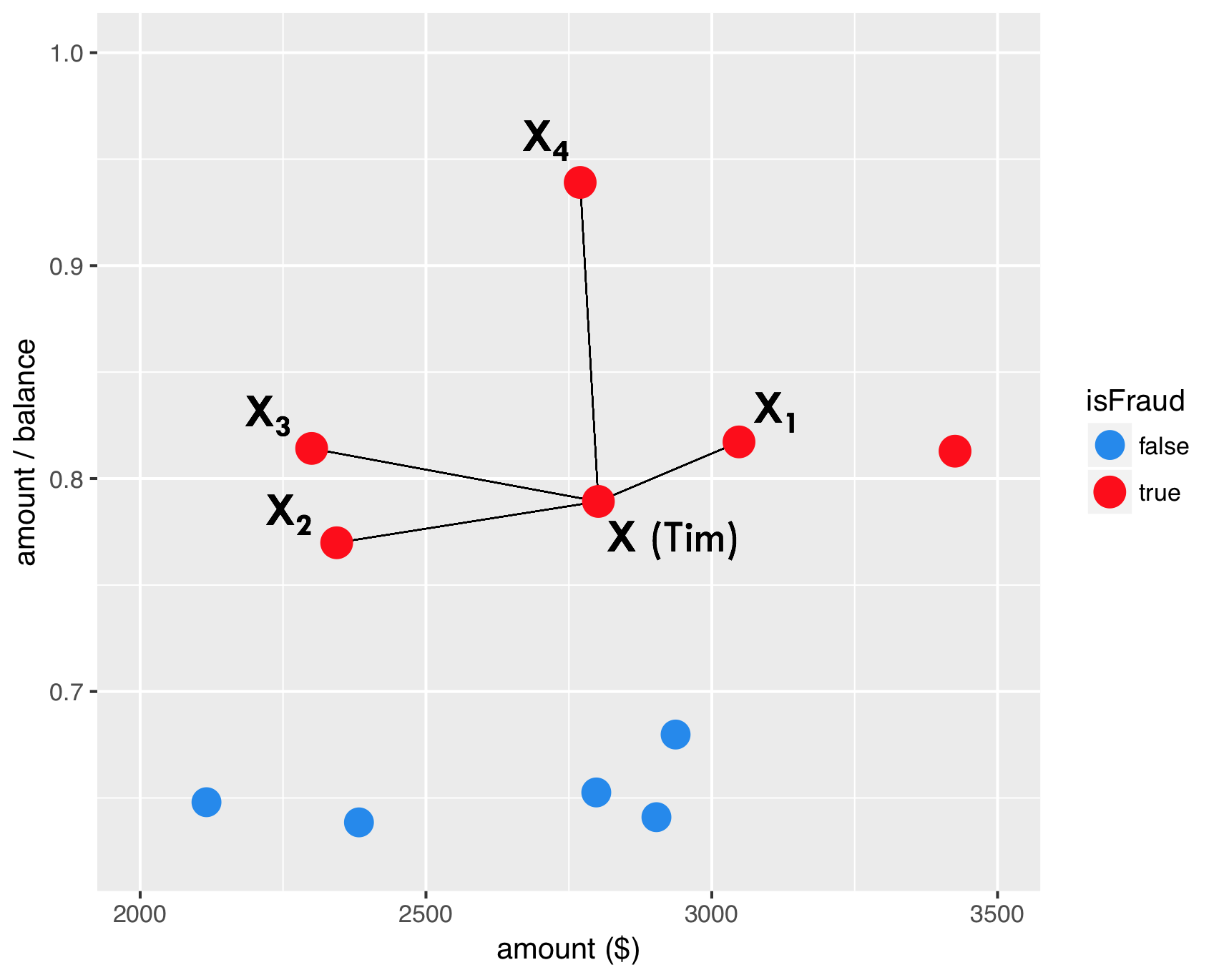
SMOTE - passo 2
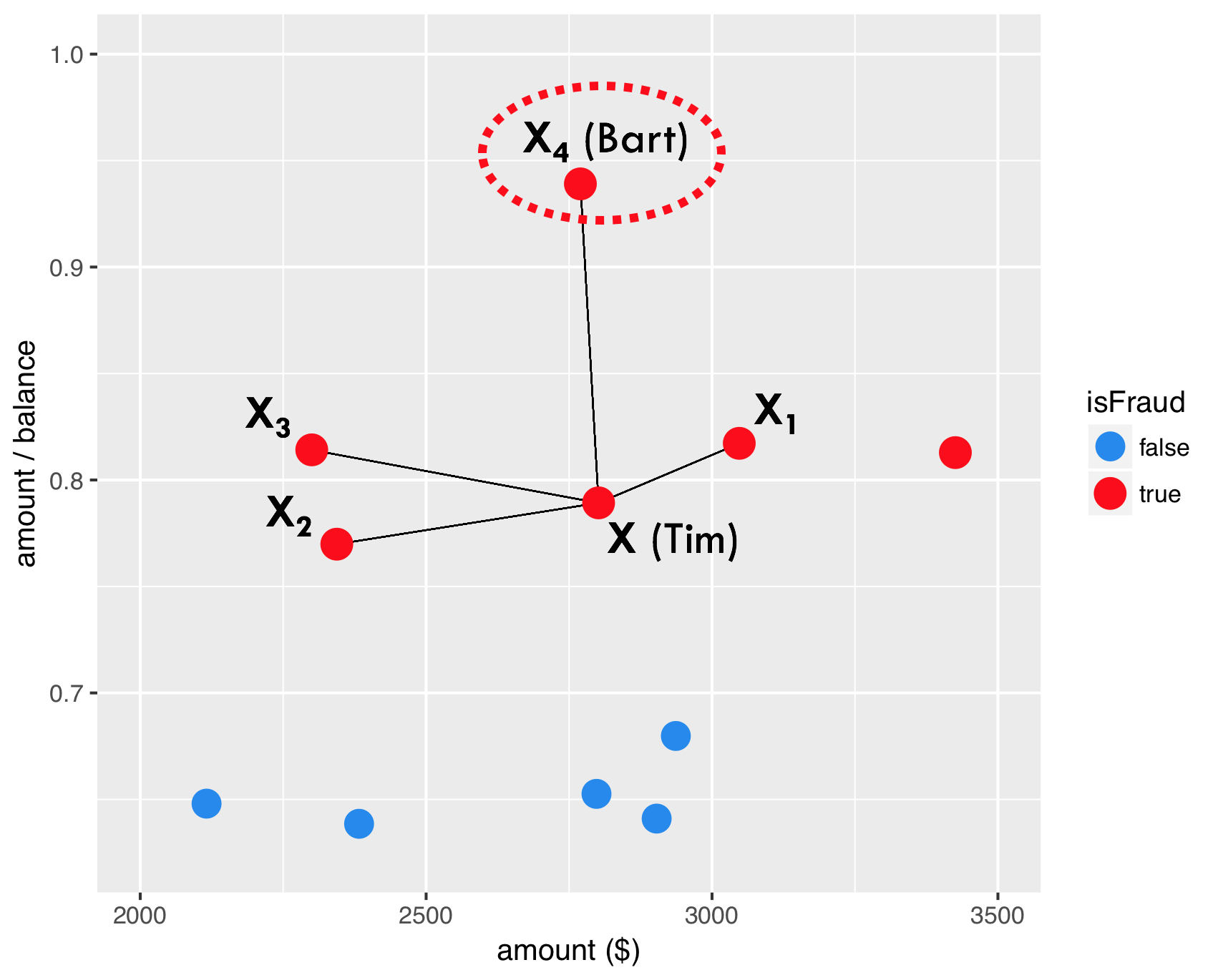
SMOTE - passo 3
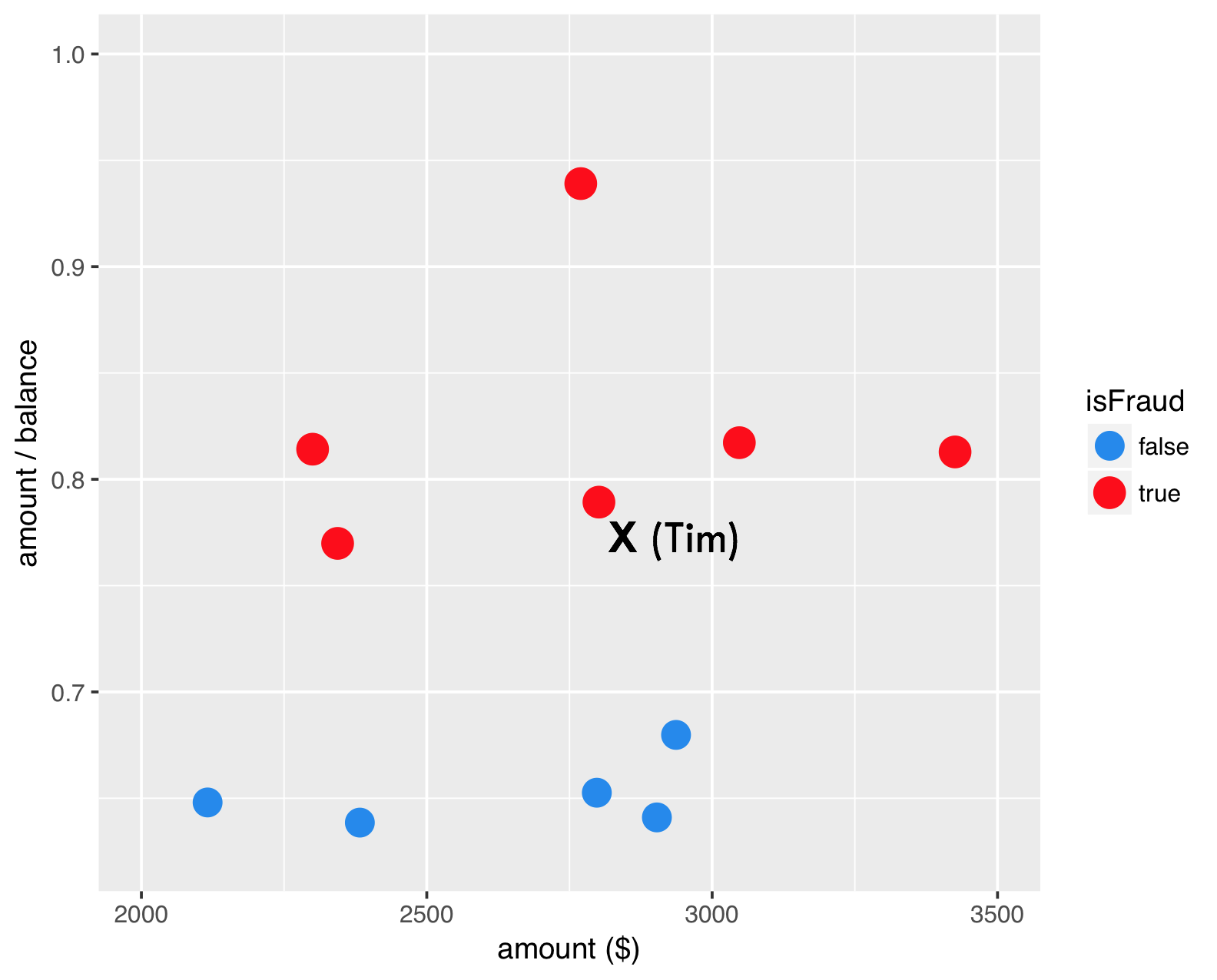
Passo 3: crea un campione sintetico

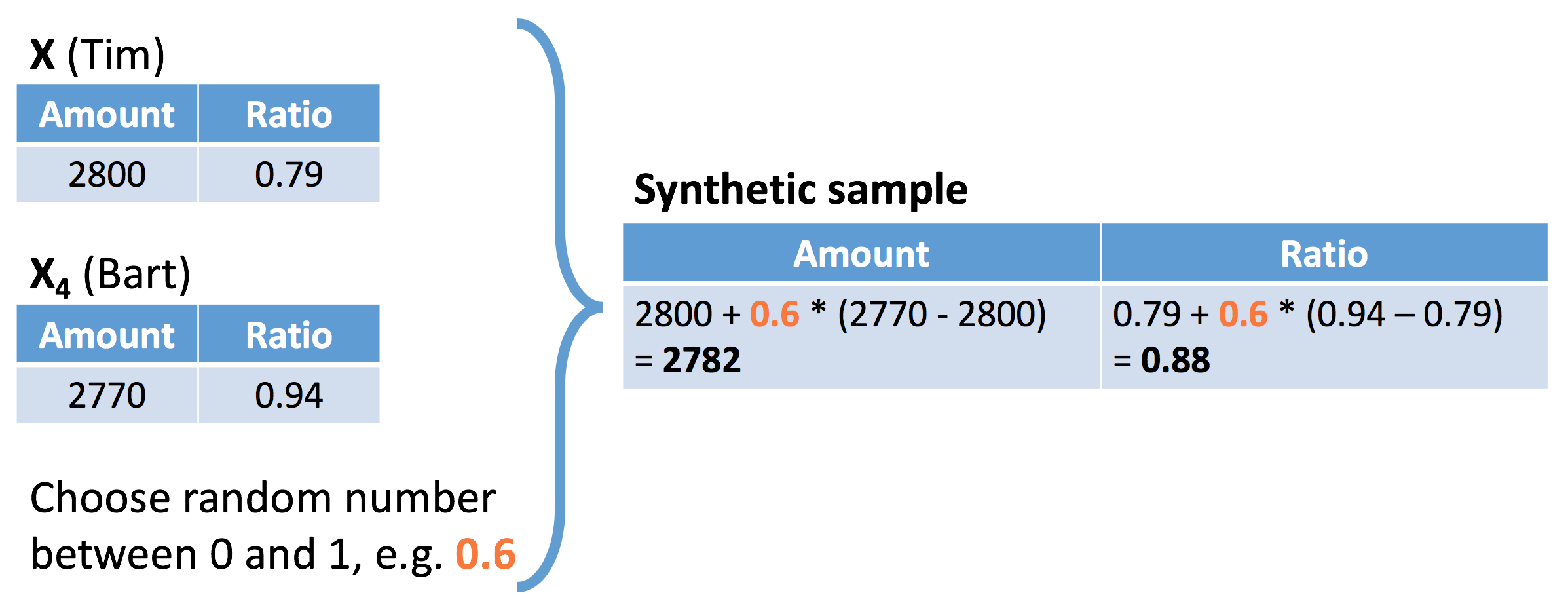
SMOTE - passo 3
Passo 3: crea un campione sintetico

SMOTE - passo 3
Passo 3: crea un campione sintetico
SMOTE - passo 3
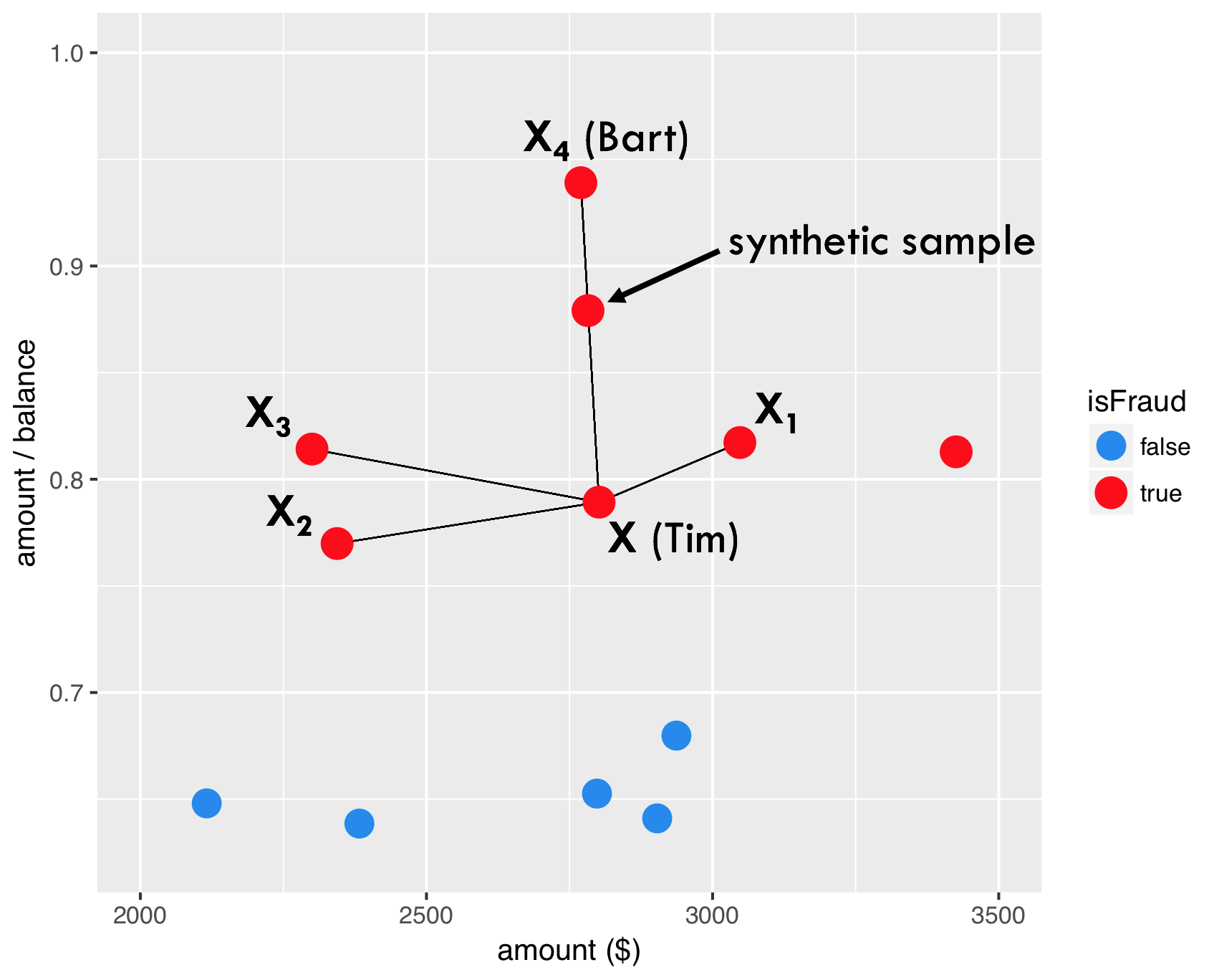
SMOTE - passo 4