Analisi del sentiment multimodale
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
Vision Language Models (VLM)
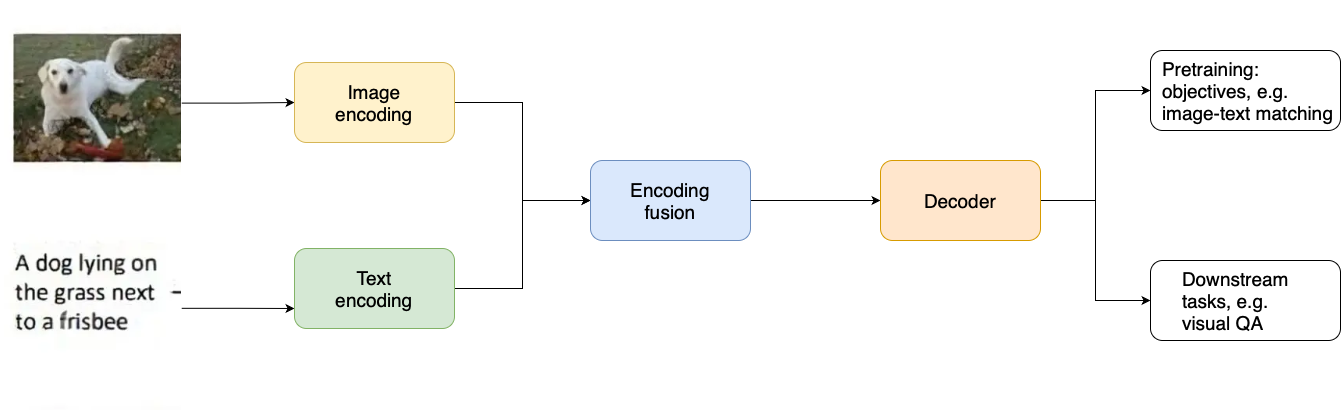
- Immagine e testo codificati separatamente
- Fusione delle feature
- Rappresentazioni condivise
- Più task con un solo modello
Task di ragionamento visivo
- VQA: Immagine + domanda → Risposte dirette sul contenuto
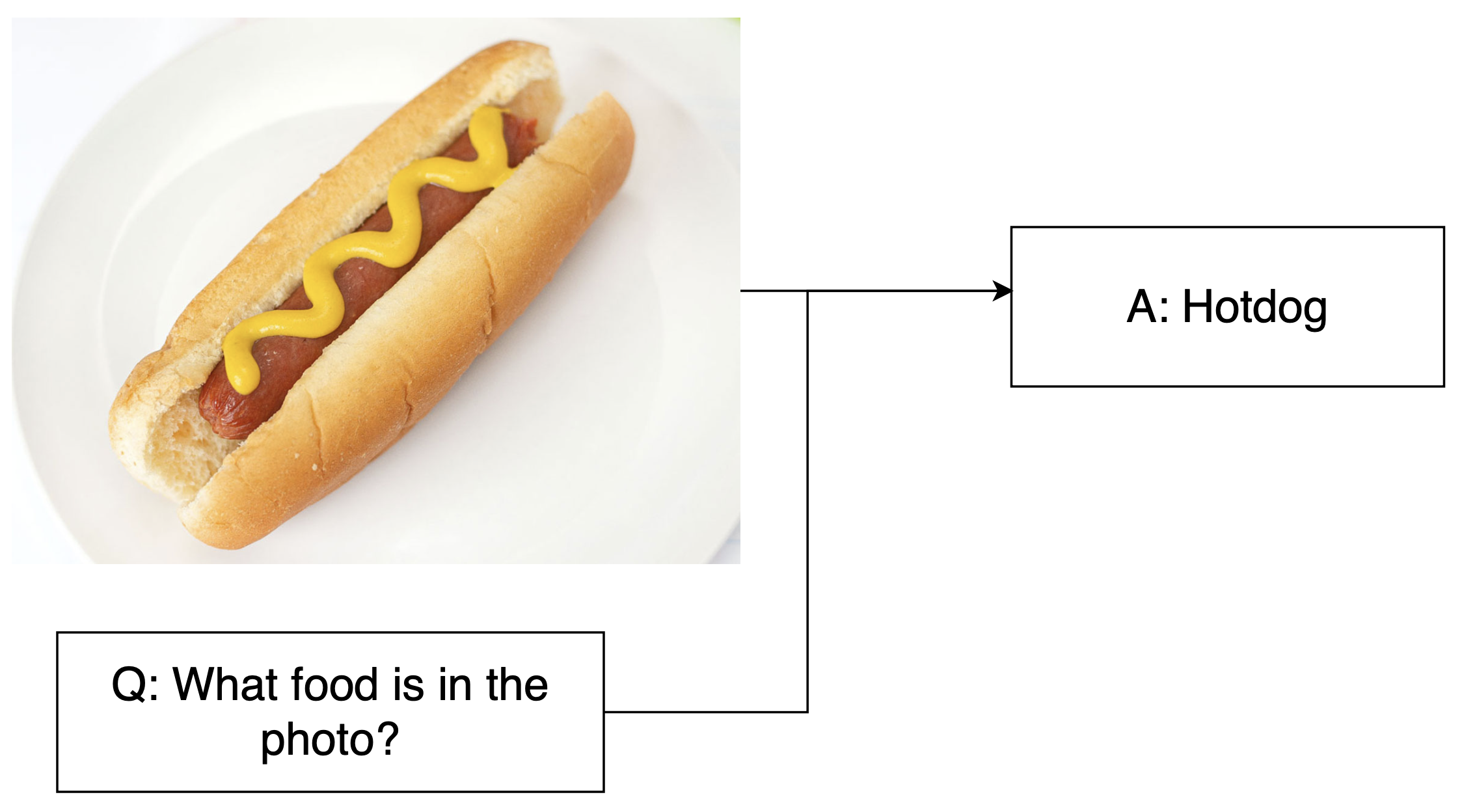
1 https://arxiv.org/pdf/1505.00468
Task di ragionamento visivo
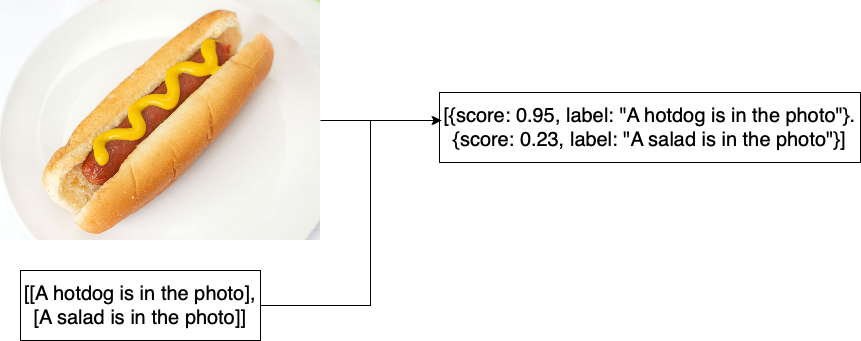
Task di ragionamento visivo

Caso d’uso: impatto sul prezzo dell’azione


