Classificazione di immagini zero-shot
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
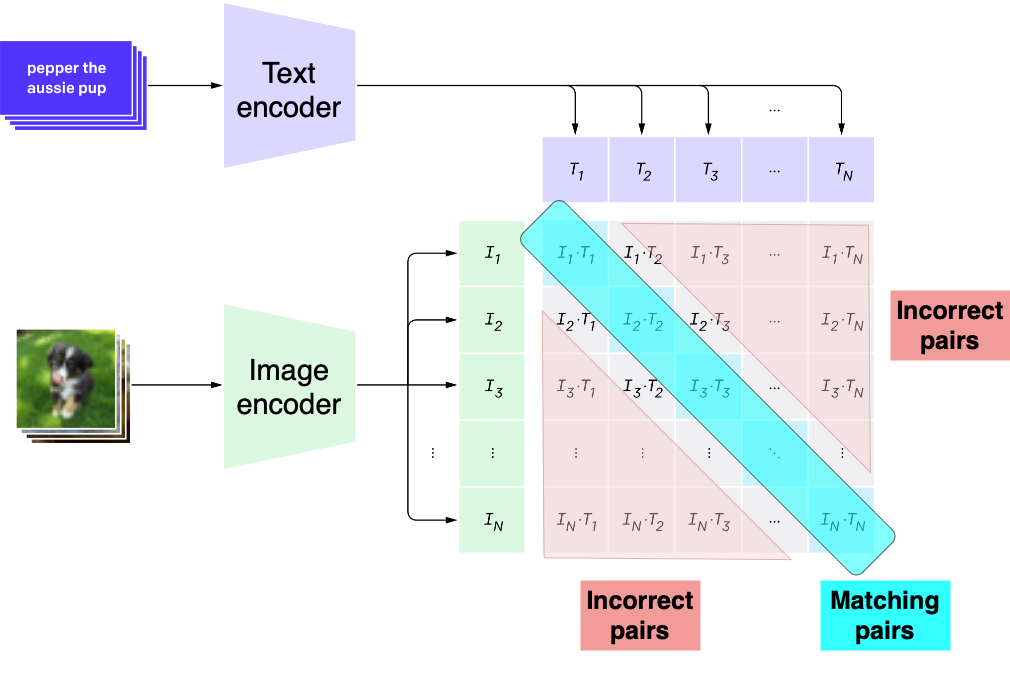
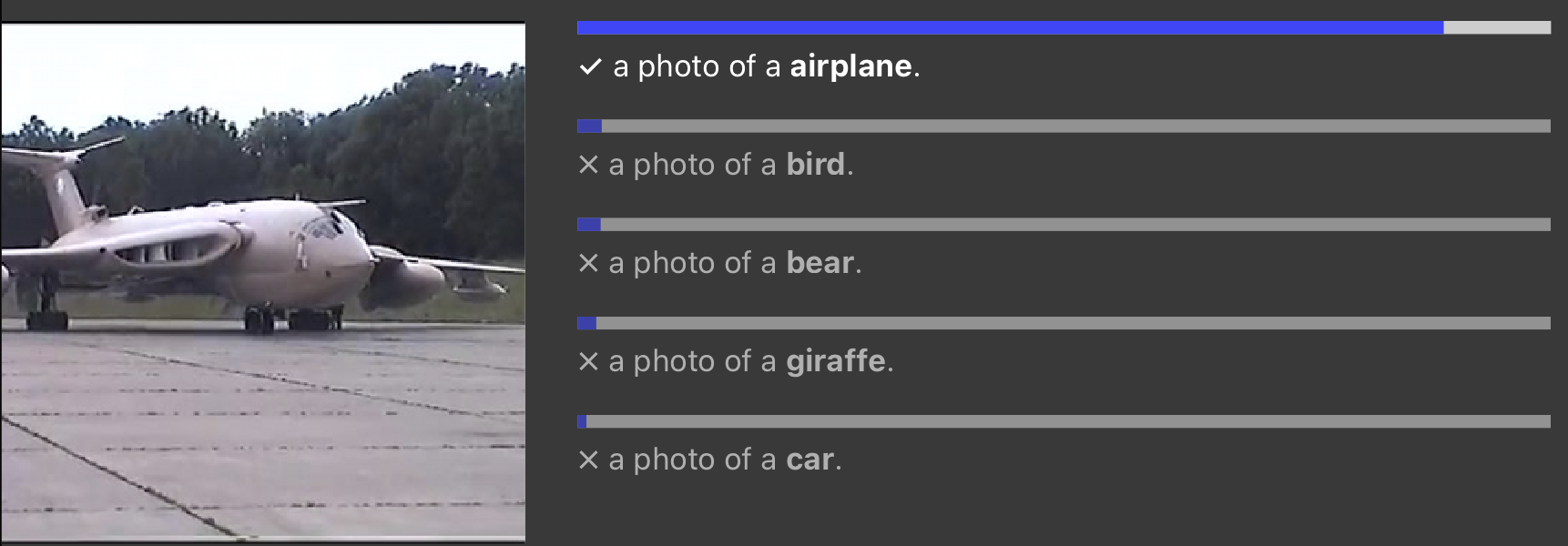
CLIP
1 https://openai.com/index/clip/
Zero-shot learning
- Svolge compiti per cui il modello non è stato addestrato
1 https://openai.com/index/clip/
Caso d'uso: categorizzazione prodotti