Preprocessare diverse modalità
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
Preprocessare testo

Preprocessare testo

Preprocessare testo
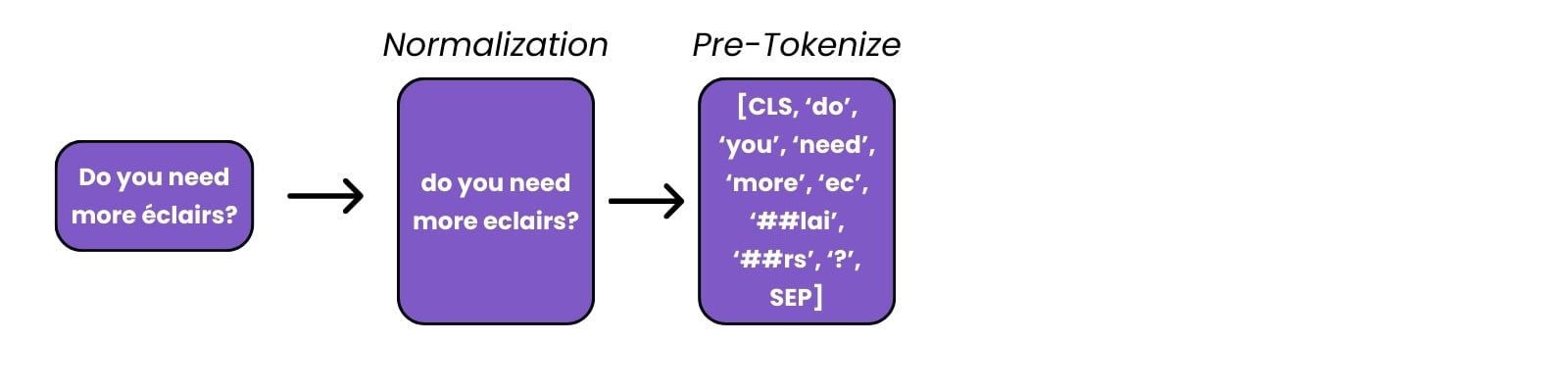
Preprocessare testo
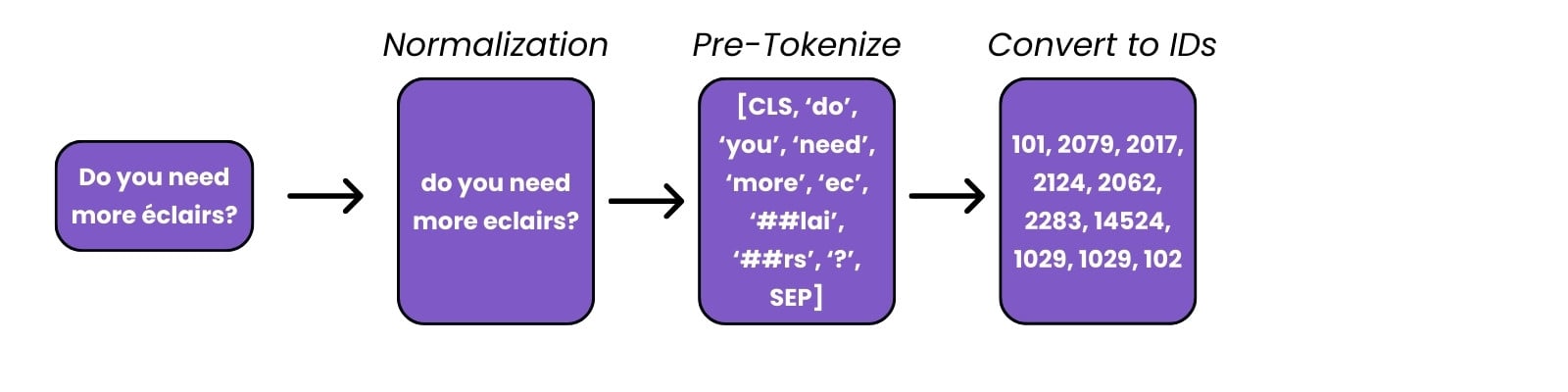
Preprocessare testo
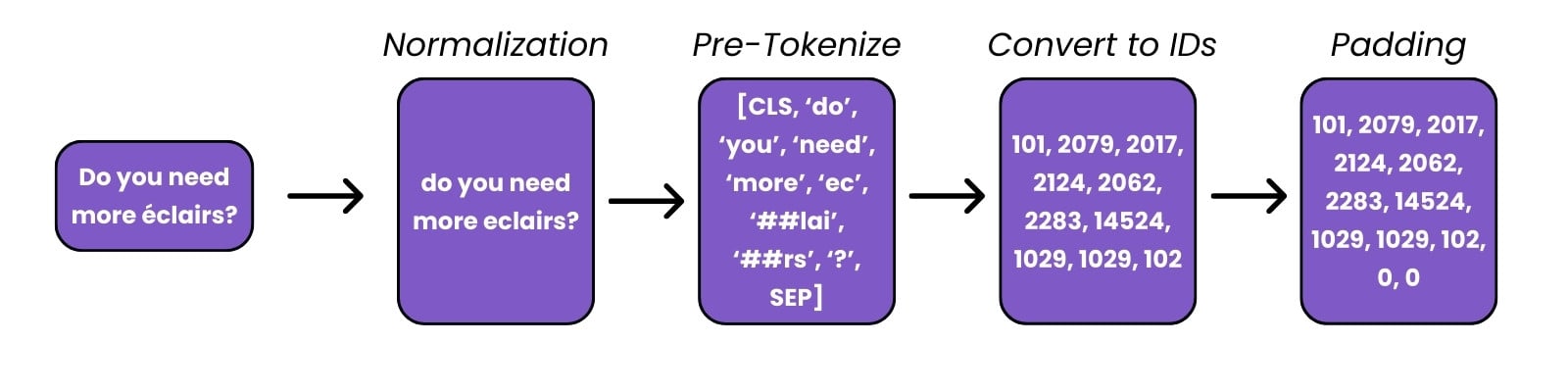
Preprocessare immagini
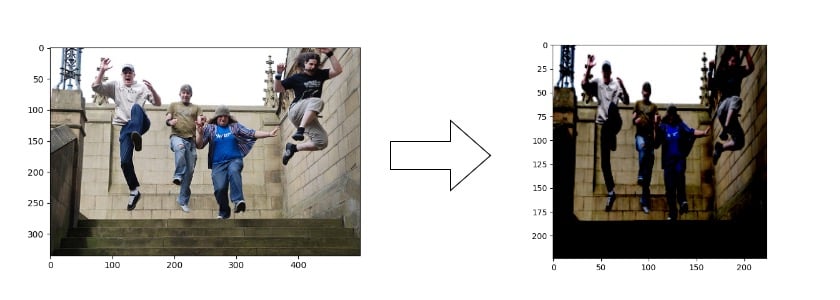
1 https://huggingface.co/datasets/nlphuji/flickr30k
Preprocessare audio
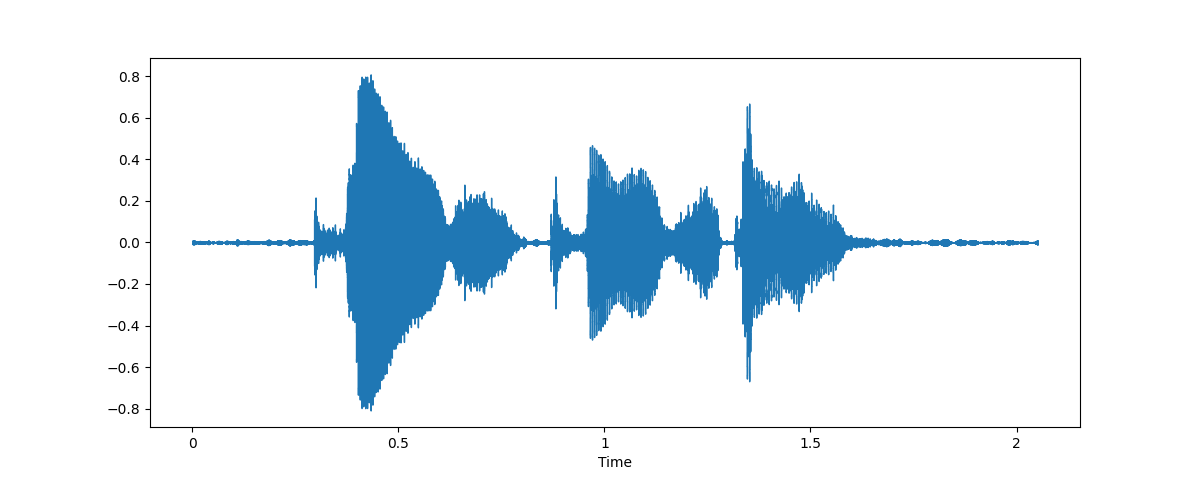
- Preprocessamento audio:
- Array sequenziale → filtro/padding
- Frequenza di campionamento → ricampionamento
Estrazione di feature come input del modello (spettrogramma)