Visione artificiale
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
Modelli di visione
1 https://arxiv.org/abs/1409.1556
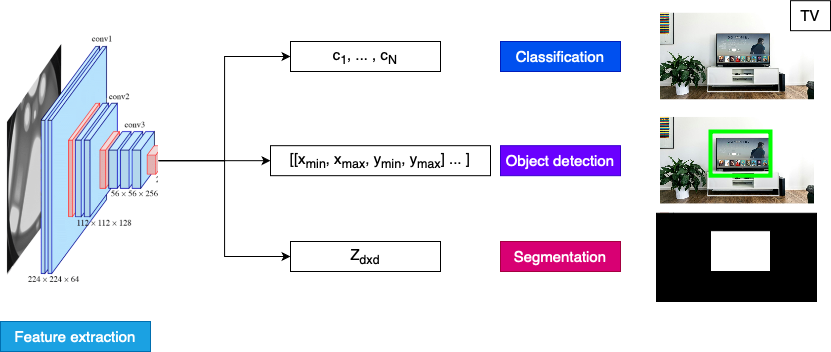
Classificazione
from datasets import load_dataset
dataset = load_dataset("nlphuji/flickr30k")
image = dataset['test'][134]["image"]

Rilevamento oggetti
dataset['test'][52]["image"]

Rilevamento oggetti

Segmentazione

- Output: matrice 2D con stesse dimensioni dell’input
- Rimozione sfondo: ogni pixel è
1(primo piano) o0(sfondo) - Immagine × Output → immagine senza sfondo
Segmentazione


