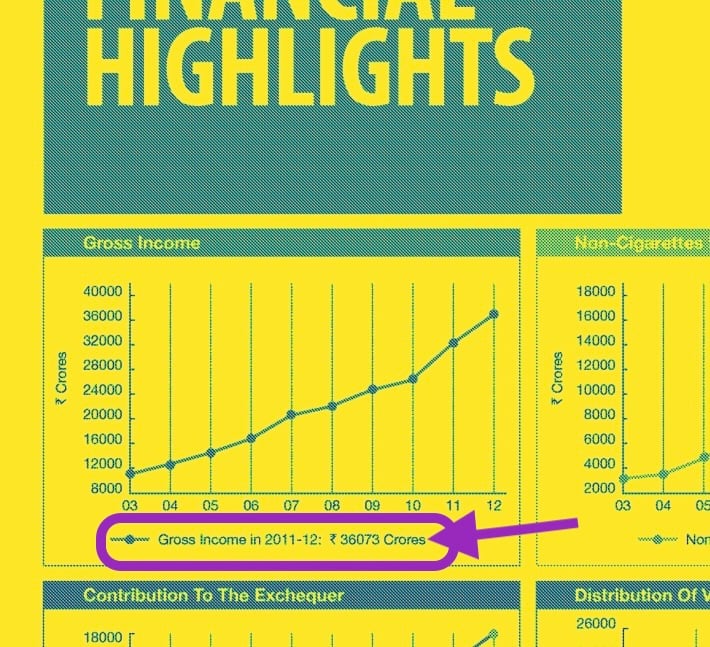
Visual question-answering (VQA)
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
Attività di QA multimodale
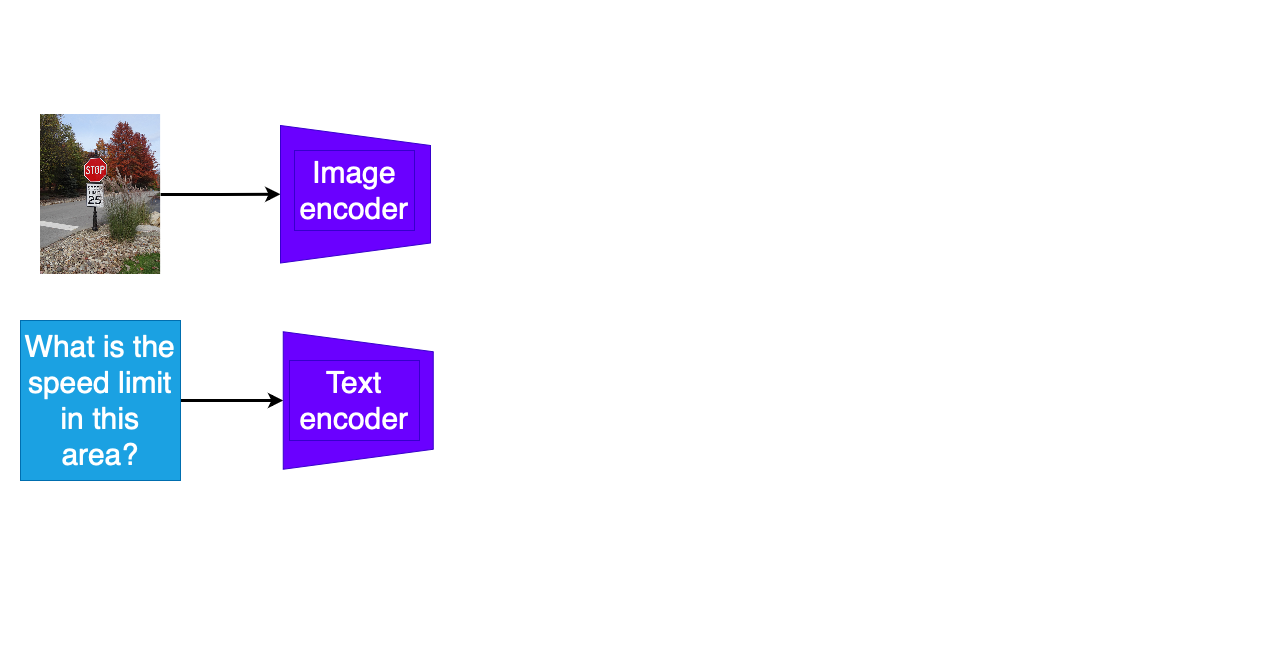
- Codifica separata della domanda e dell'altra modalità
Attività di QA multimodale
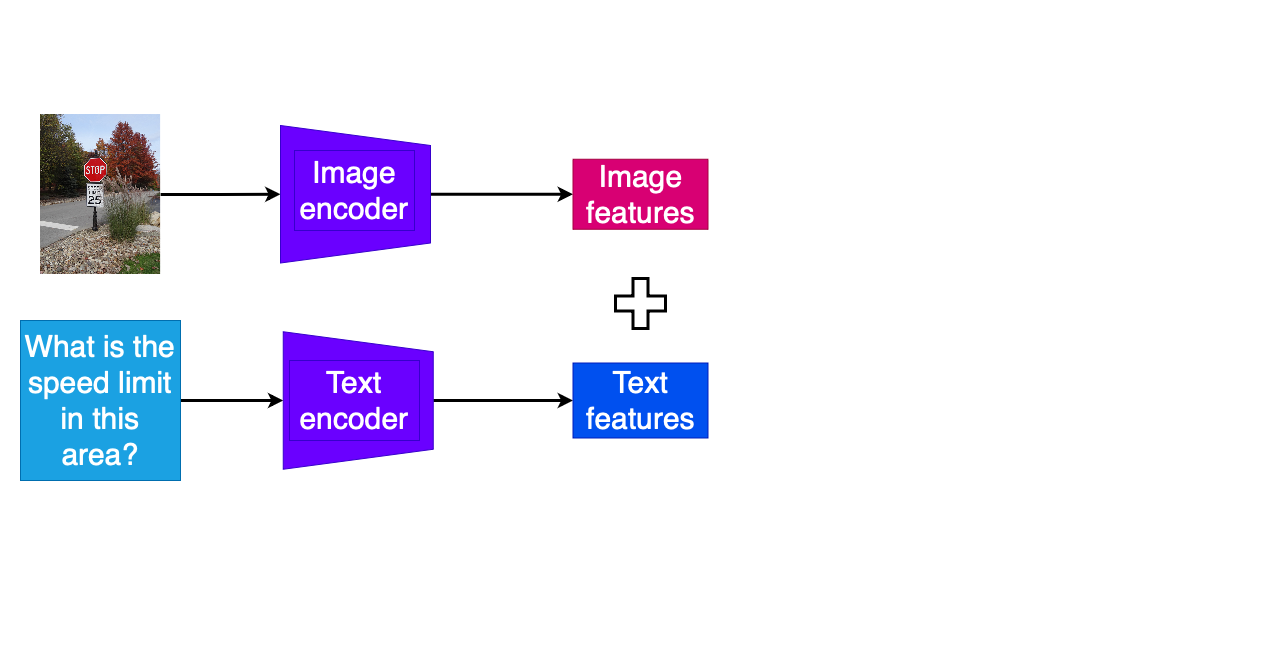
- Codifica separata della domanda e dell'altra modalità
- Combinazione delle feature codificate
Attività di QA multimodale
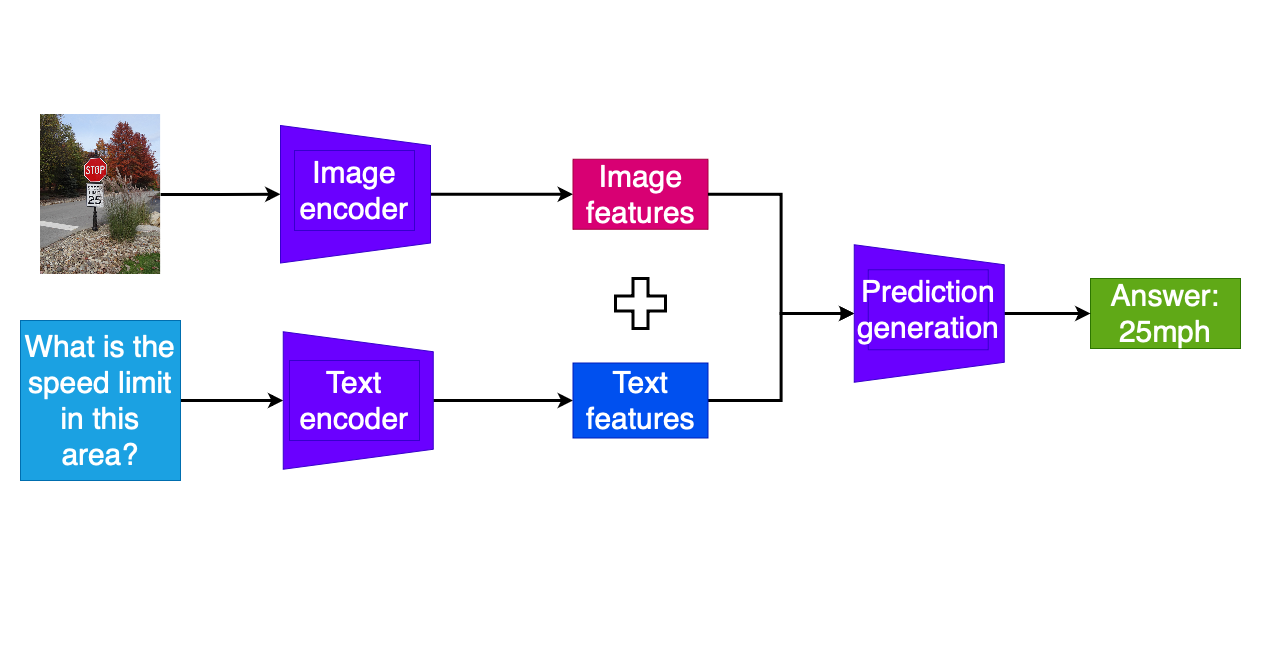
- Codifica separata della domanda e dell'altra modalità
- Combinazione delle feature codificate
- Ulteriori layer del modello per predire i token della risposta
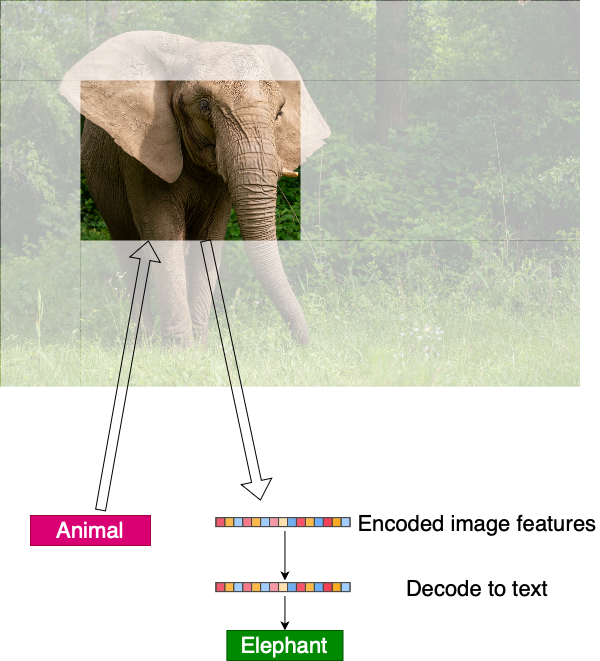
VQA

VQA
Document VQA
Document VQA

- Servono dipendenze extra per eseguire l'OCR
pytesseractsi installa conpip- Tesseract OCR via installer (es.
apt-get,exeohomebrew/macports)

Document VQA