Ottimizzare i modelli text-to-speech
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
Perché il fine-tuning del text-to-speech
Es.: grande modello inglese per pretraining generale ⇏ parlato italiano realistico

Perché il fine-tuning del text-to-speech
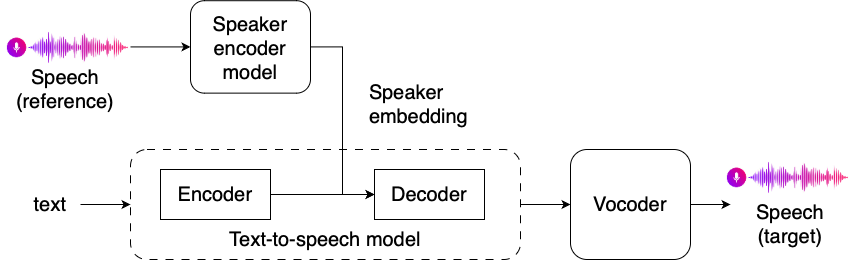
- Speaker embedding + feature del modello TTS → modello generativo
- Nuovi speaker embedding da soli non bastano senza fine-tuning
Usare il nuovo modello