Modifica immagini con modelli di diffusione
Modelli multi-modali con Hugging Face

James Chapman
Curriculum Manager, DataCamp
Diffusers

- Addestrato a mappare rumore → immagine
- CLIP + Diffusion → 2 tipi di generazione condizionata
- Generazione: testo → immagine
- Modifica: testo+immagine → immagine
1 https://huggingface.co/docs/diffusers
Modifica immagine personalizzata
ControlNet: generazione condizionata guidata da immagine e testo
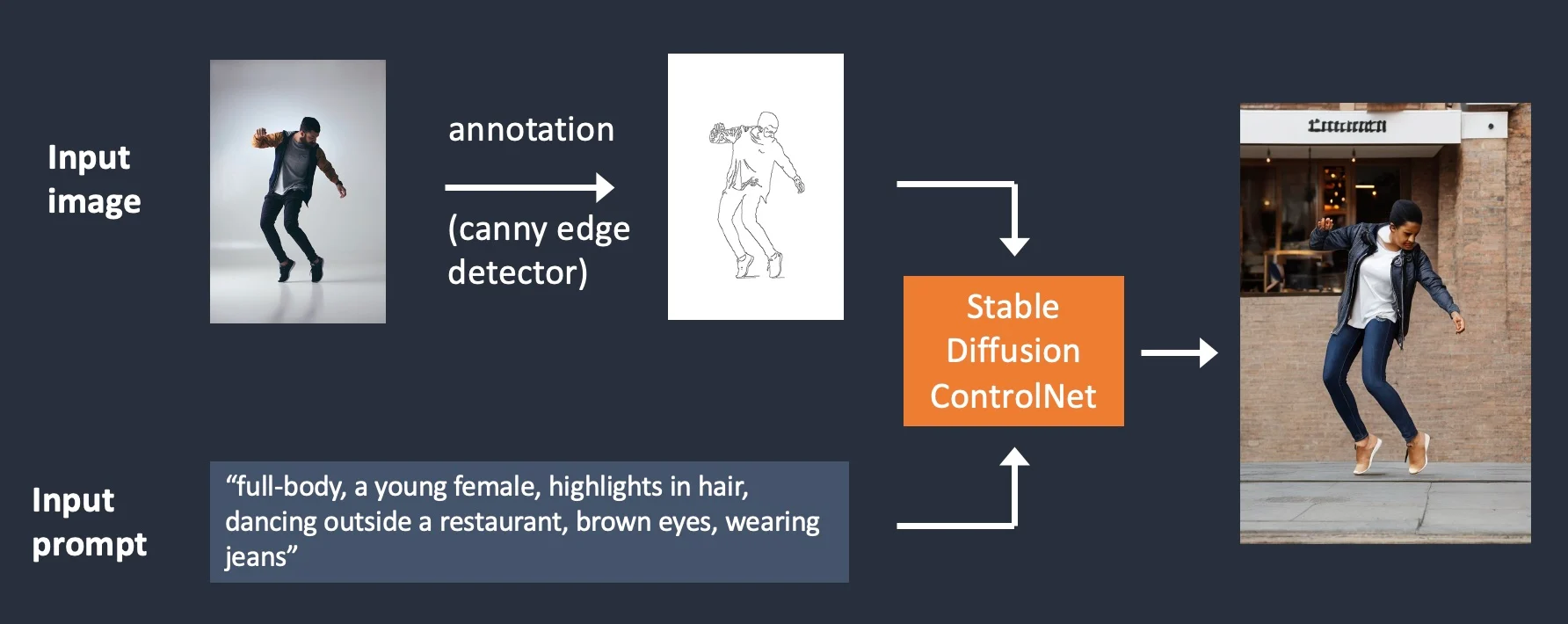
1 https://stable-diffusion-art.com/controlnet/
Modifica immagine personalizzata

Modifica immagine personalizzata

Modifica immagine personalizzata

Inpainting dell'immagine

Inpainting dell'immagine

Inpainting dell'immagine


