Standardizzare le feature
Prevedere il CTR con il Machine Learning in Python

Kevin Huo
Instructor
Scalare i dati
- Lo standard scaling porta tutte le feature a media 0 e deviazione standard 1
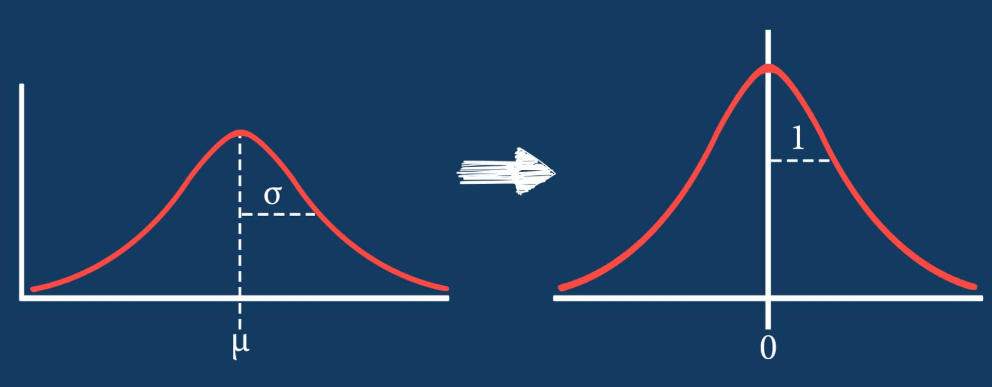
- In generale è una buona pratica per i modelli di machine learning

