Lavorare con un oggetto di forecast
Progettare pipeline di forecasting per la produzione

Rami Krispin
Senior Manager, Data Science and Engineering
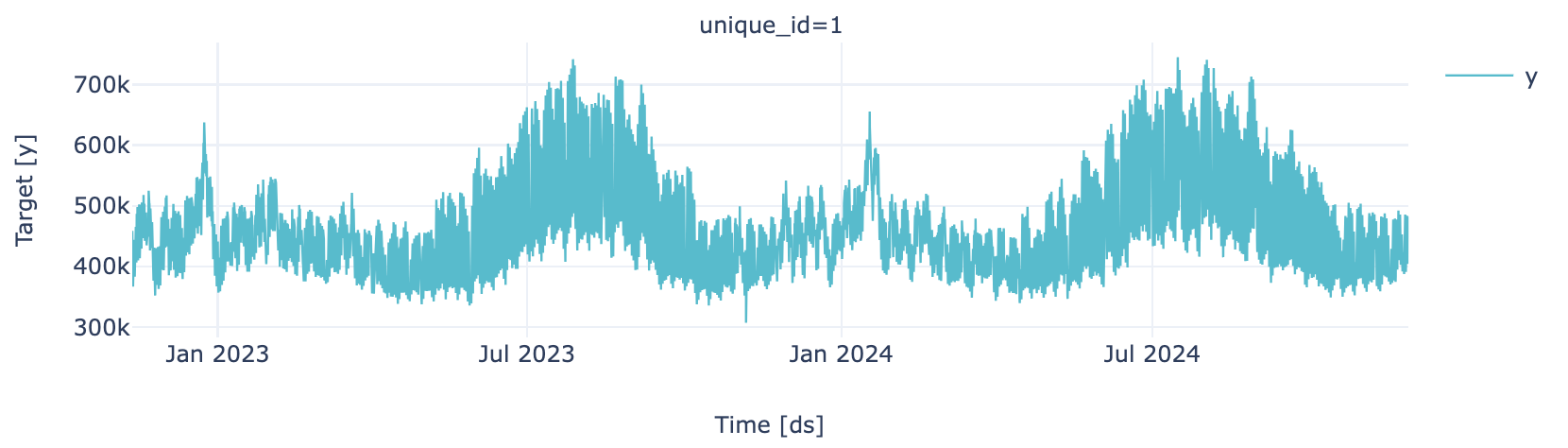
Partizione di training
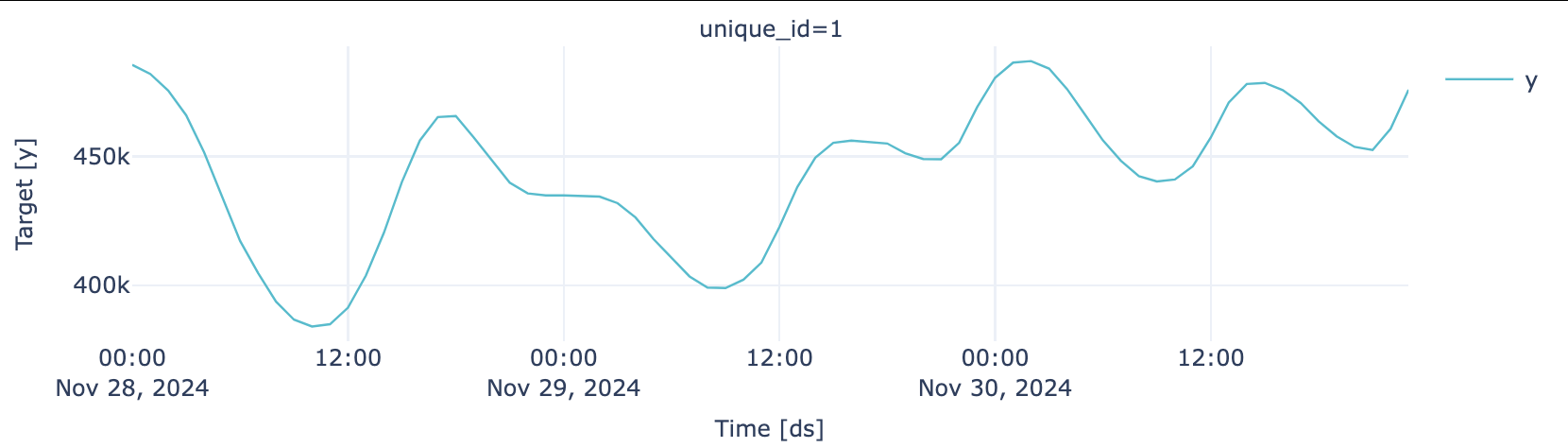
Partizione di test
Preparazione dati
plot_series(train, engine = "plotly")
plot_series(test, engine = "plotly")
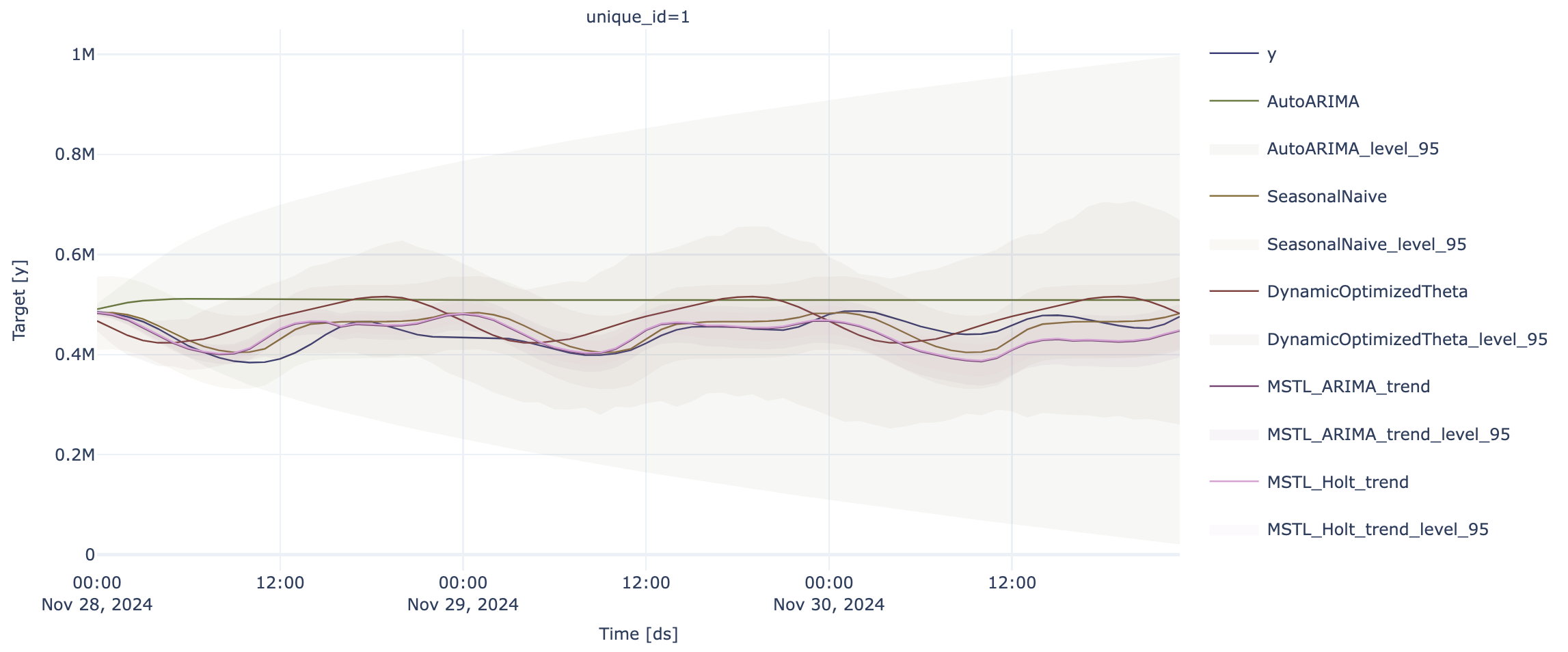
Previsioni con StatsModels
p = sf.plot(test, forecast_stats, engine = "plotly", level=[95])
p.update_layout(height=400)