Designing fault-tolerant and resilient applications on AWS
Developing applications on AWS

Ricardo Sueiras
Principal Technologist
Building for resilience
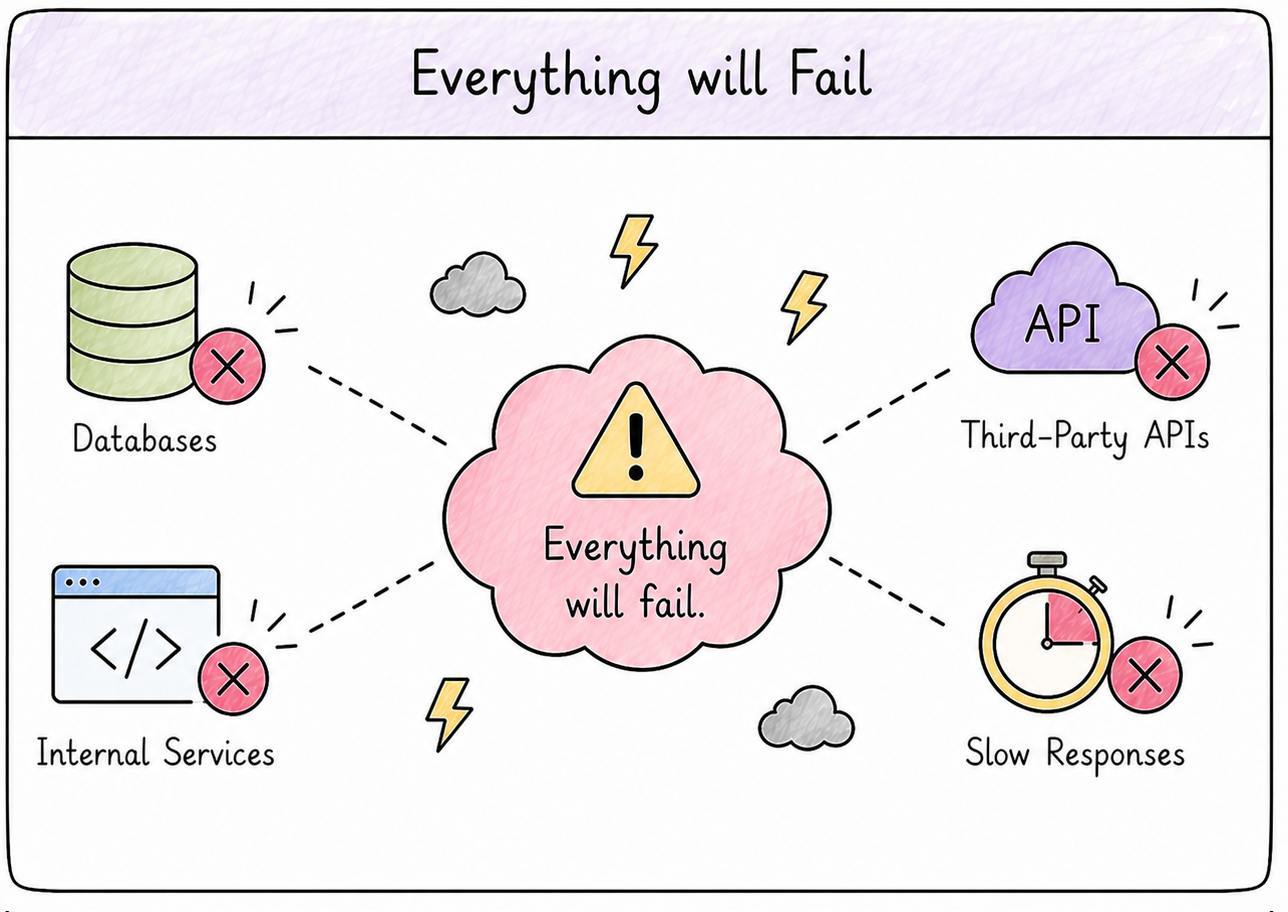
Temporary failures
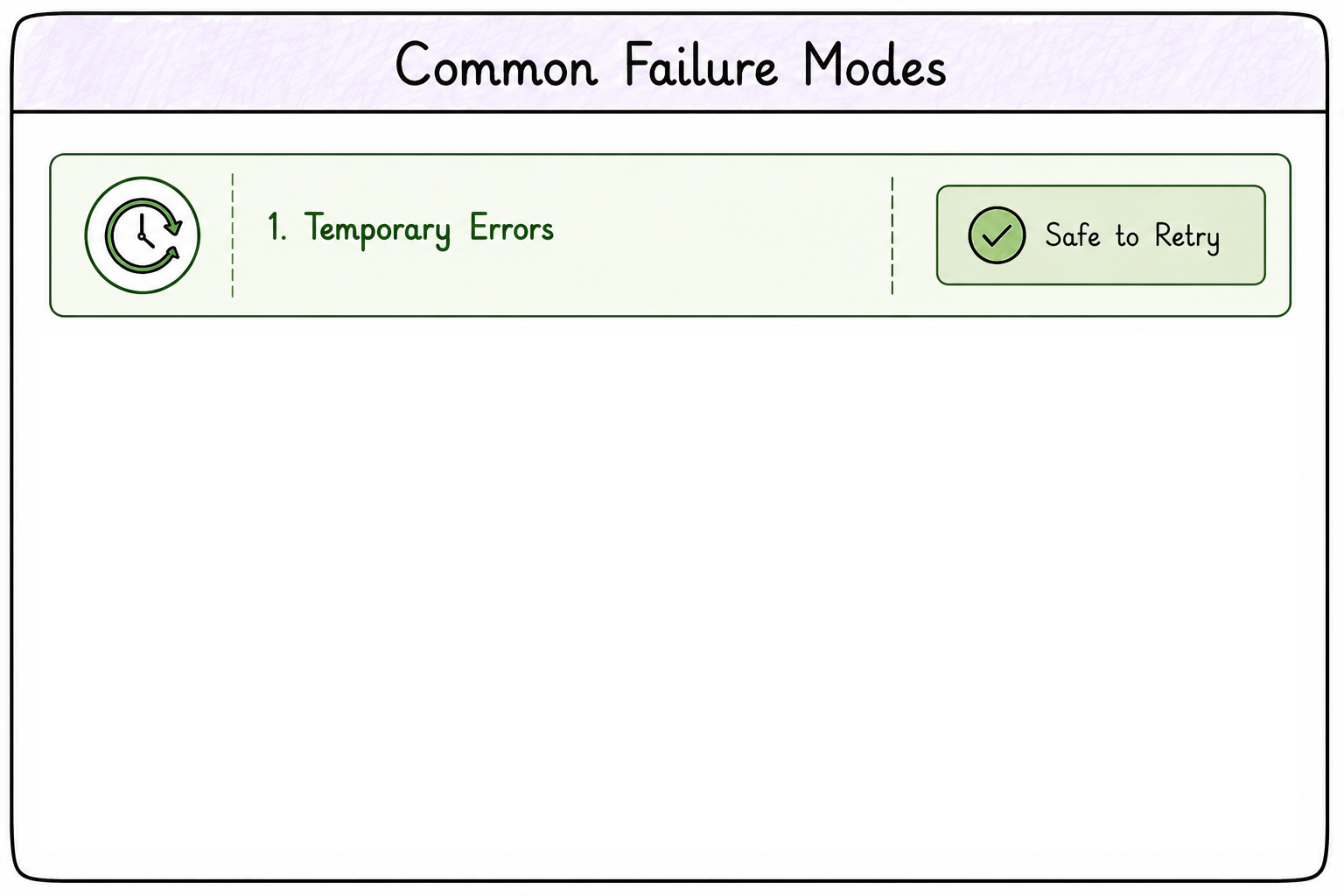
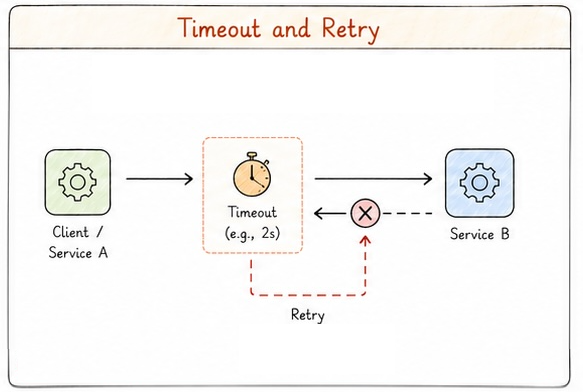
Timeouts

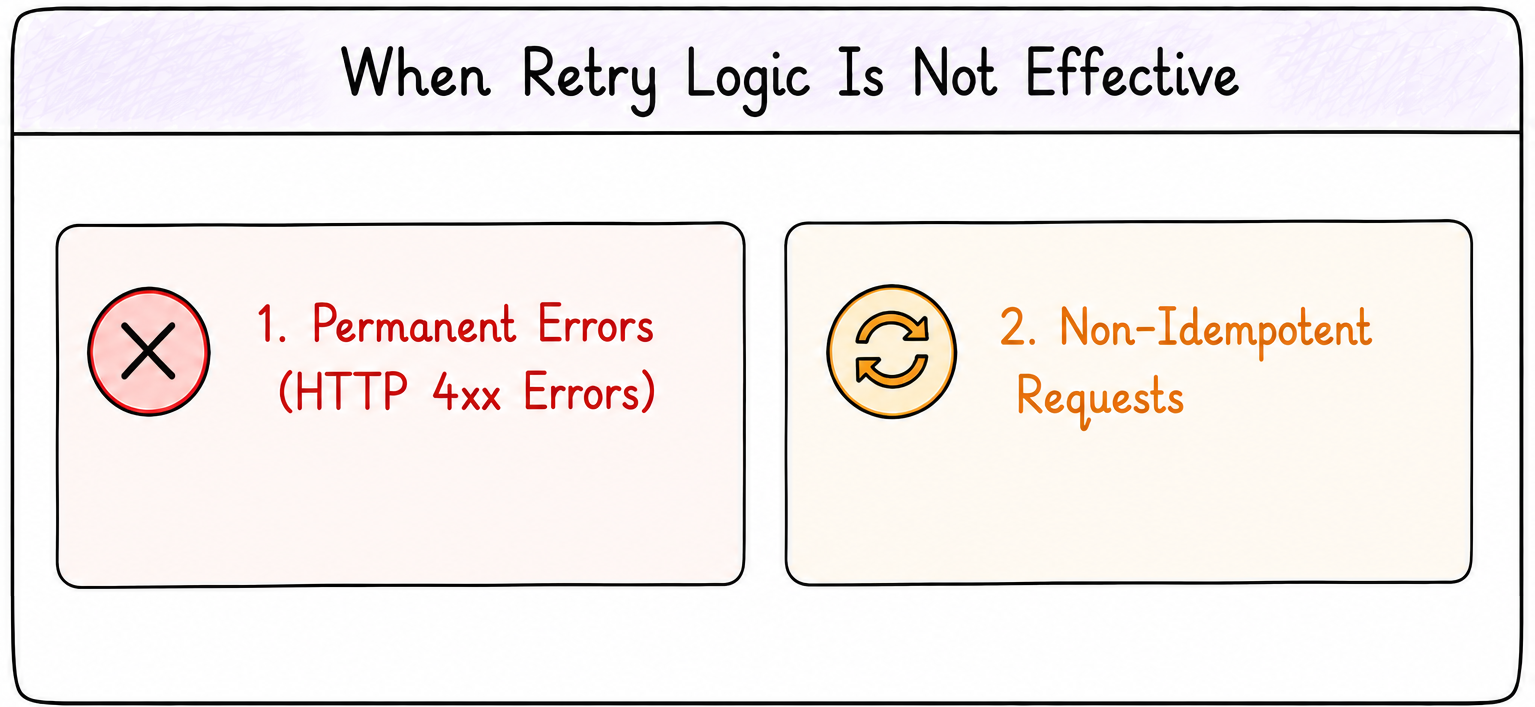
Permanent errors

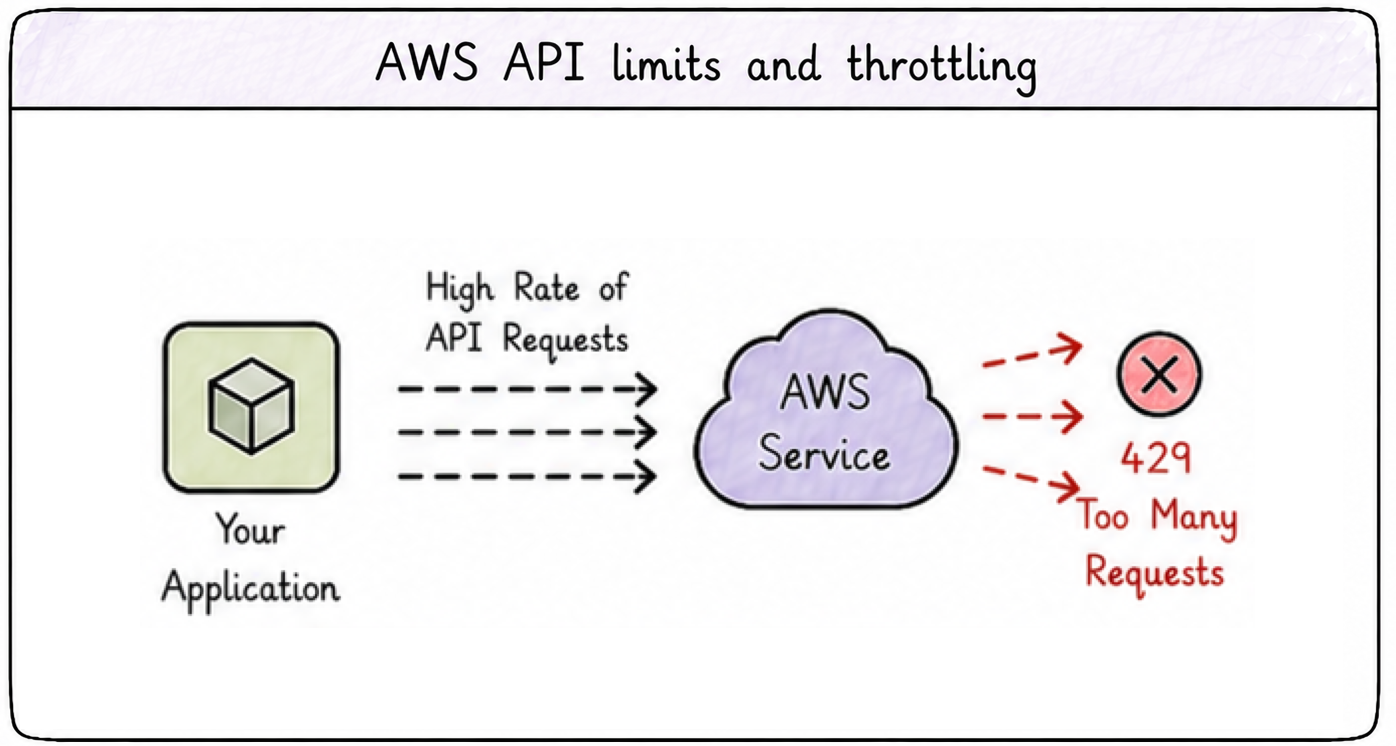
API limits

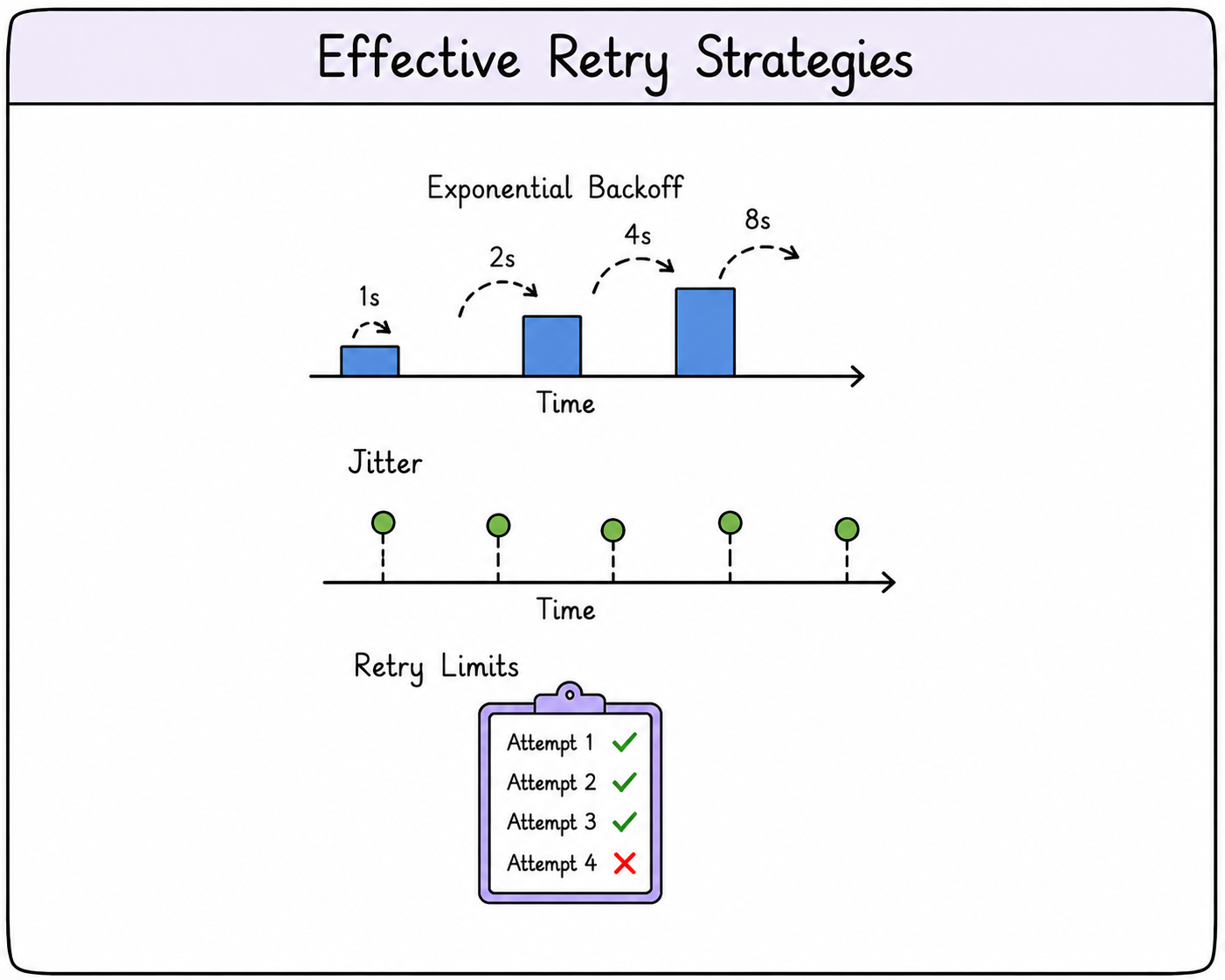
Retry strategies
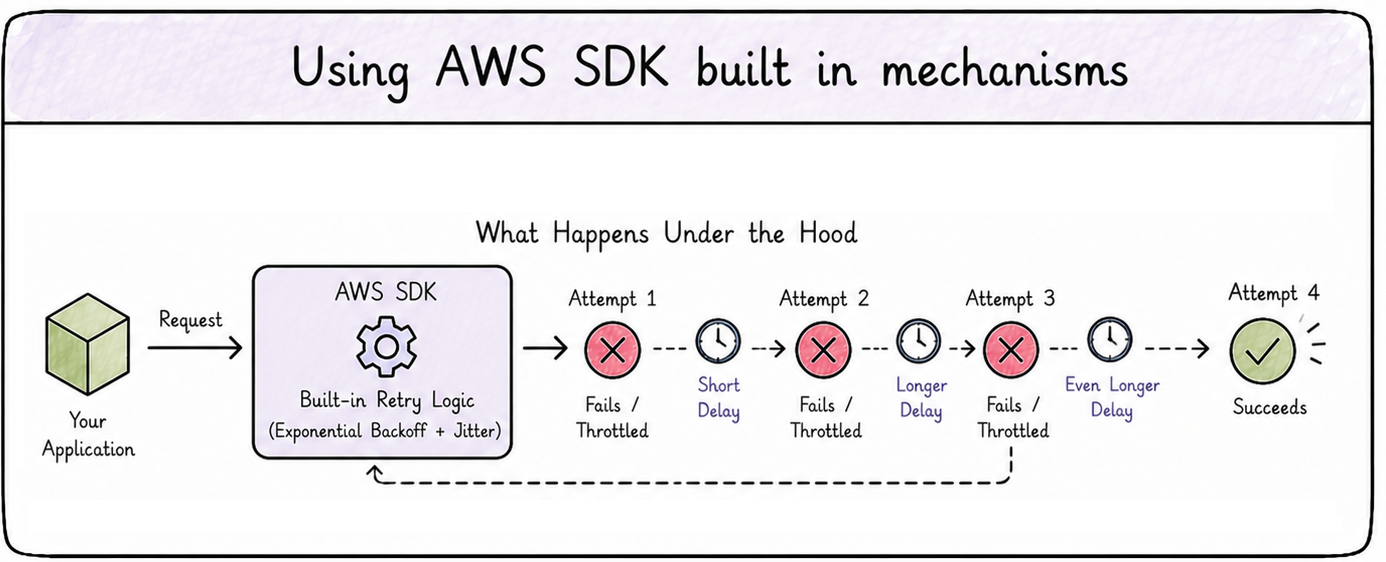
AWS SDK native capabilities
Managing retry logic
Managing timeouts
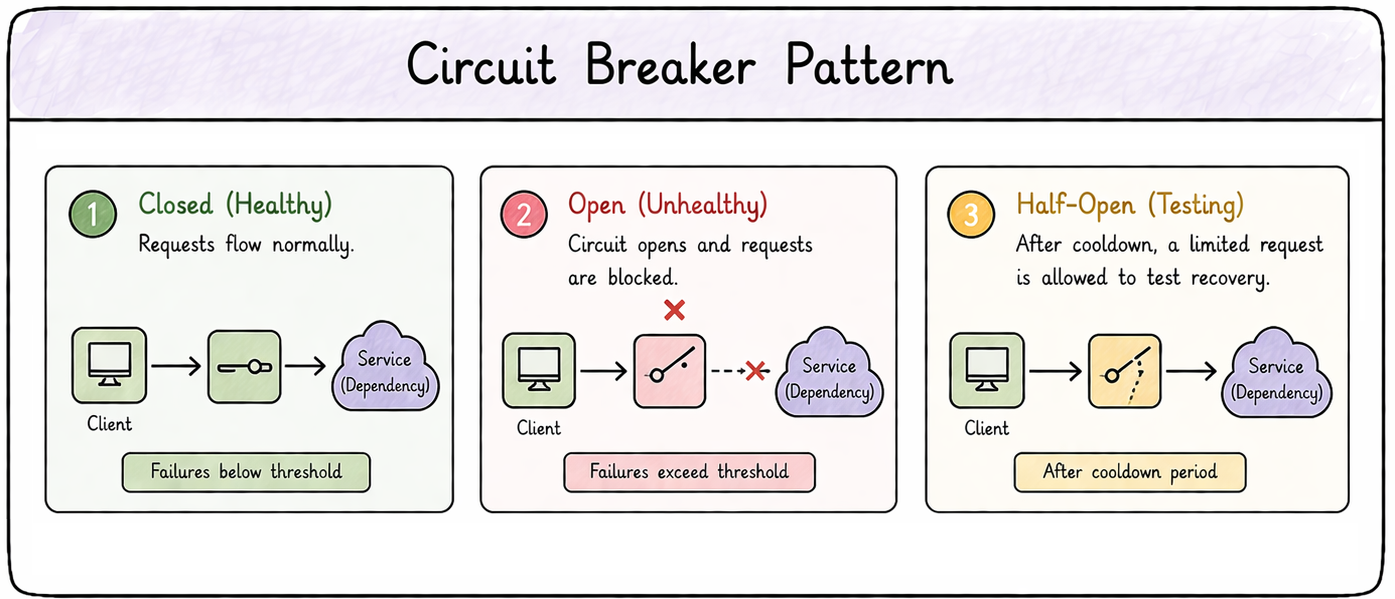
Circuit breakers
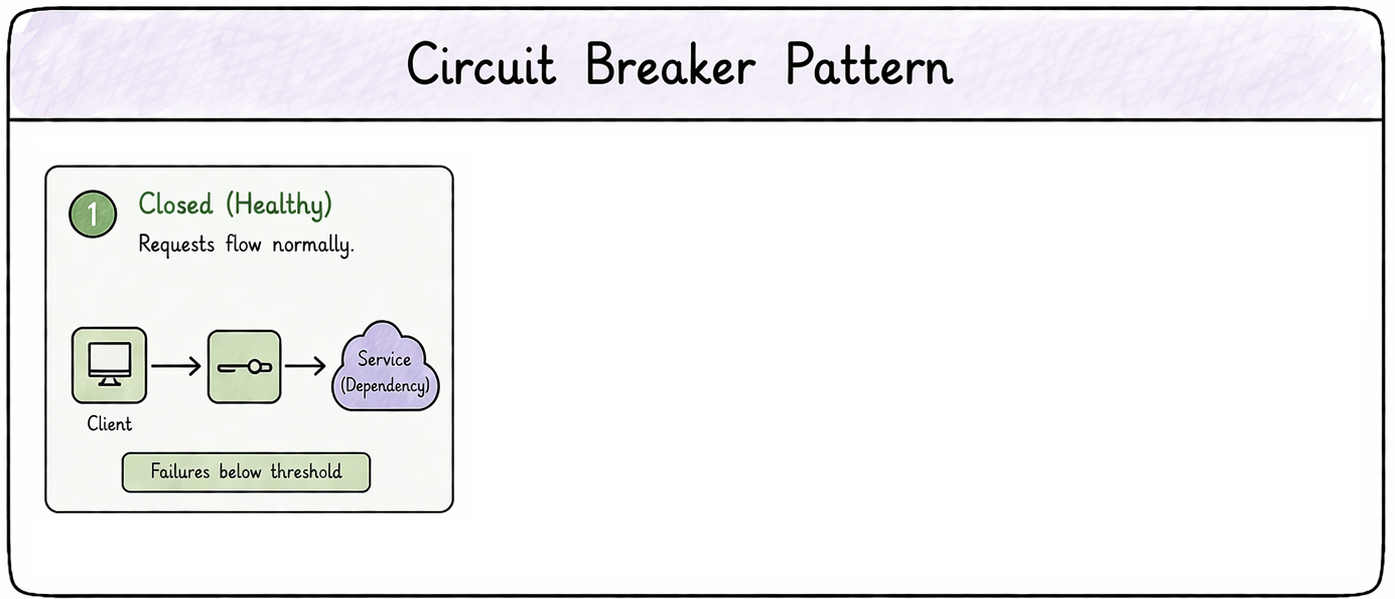
Circuit breakers
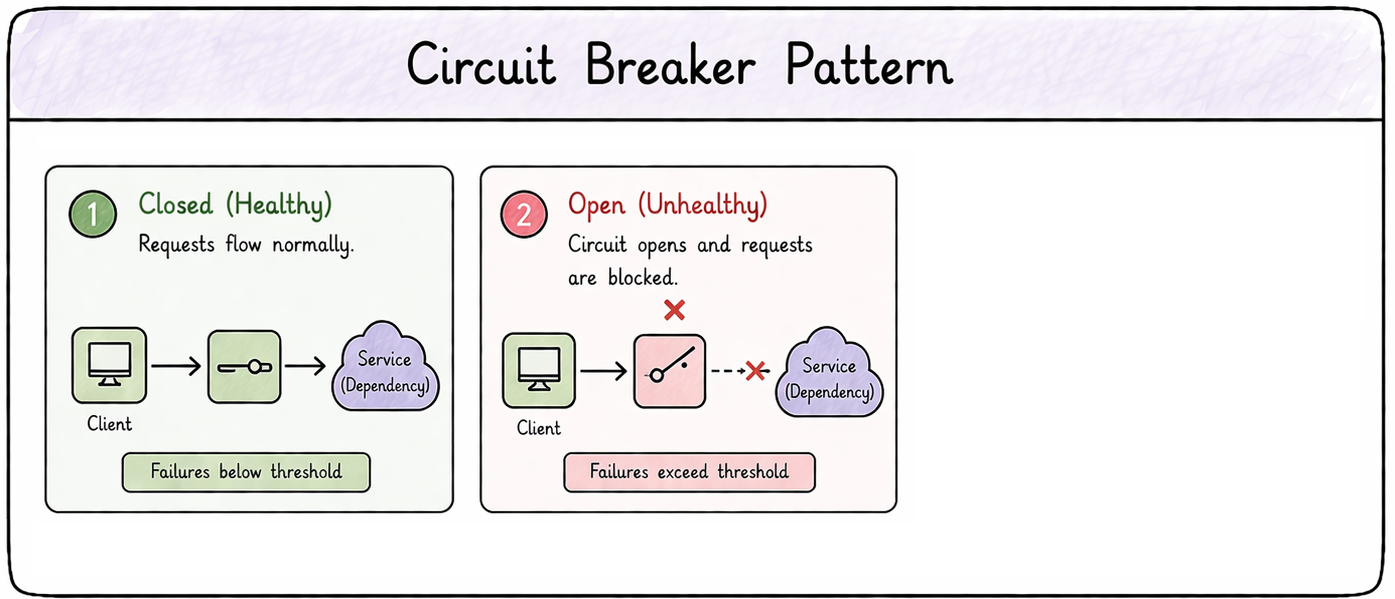
Circuit breakers
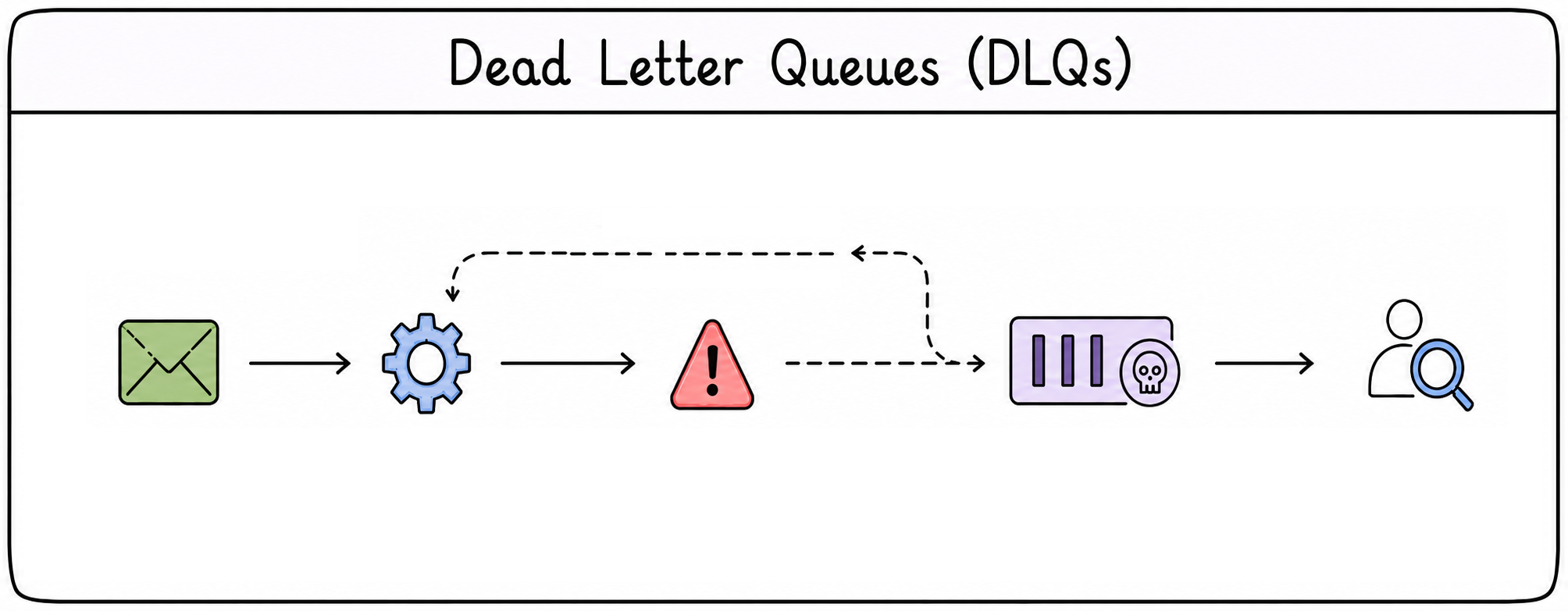
Dead letter queues
AWS API limits
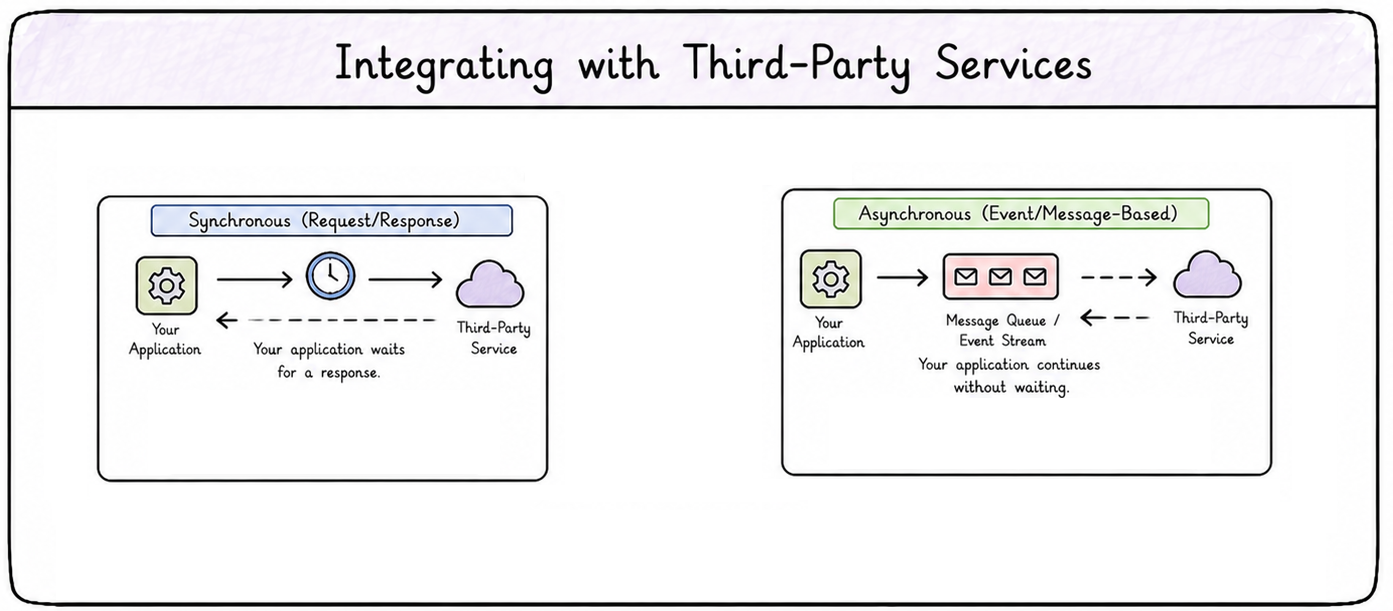
Integrating with third-parties services
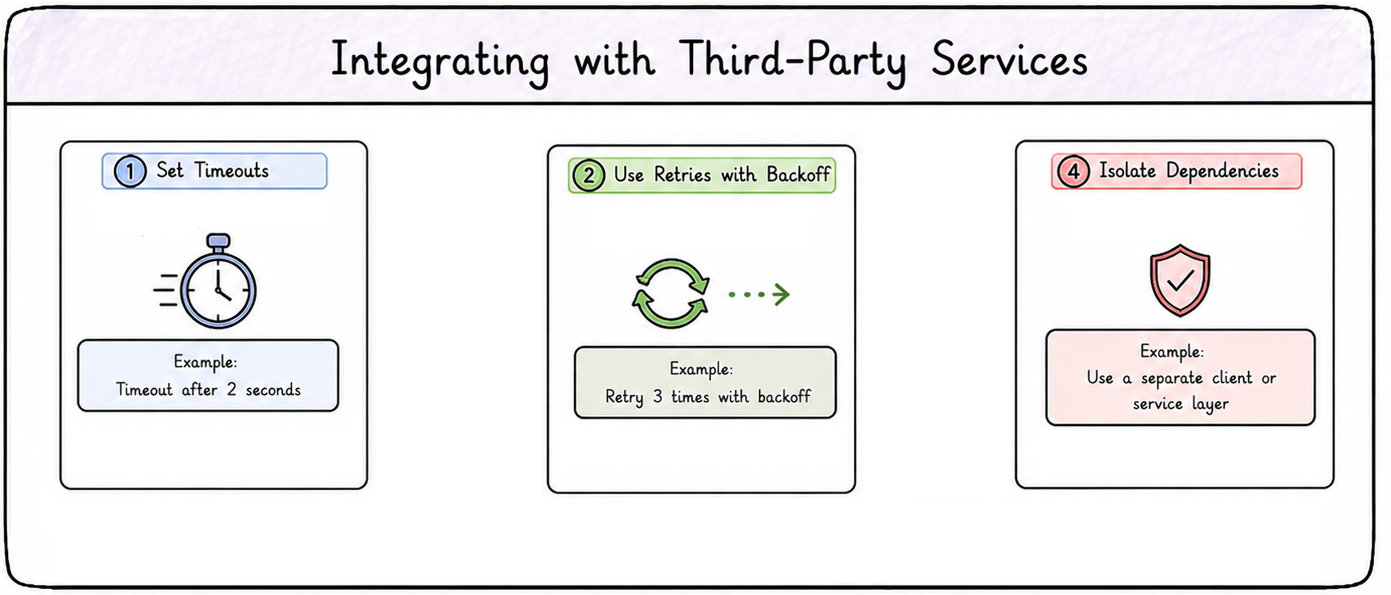
Integrating with third-parties