Coordinating services and managing state
Developing applications on AWS

Ricardo Sueiras
Principal Technologist
Service Coordination
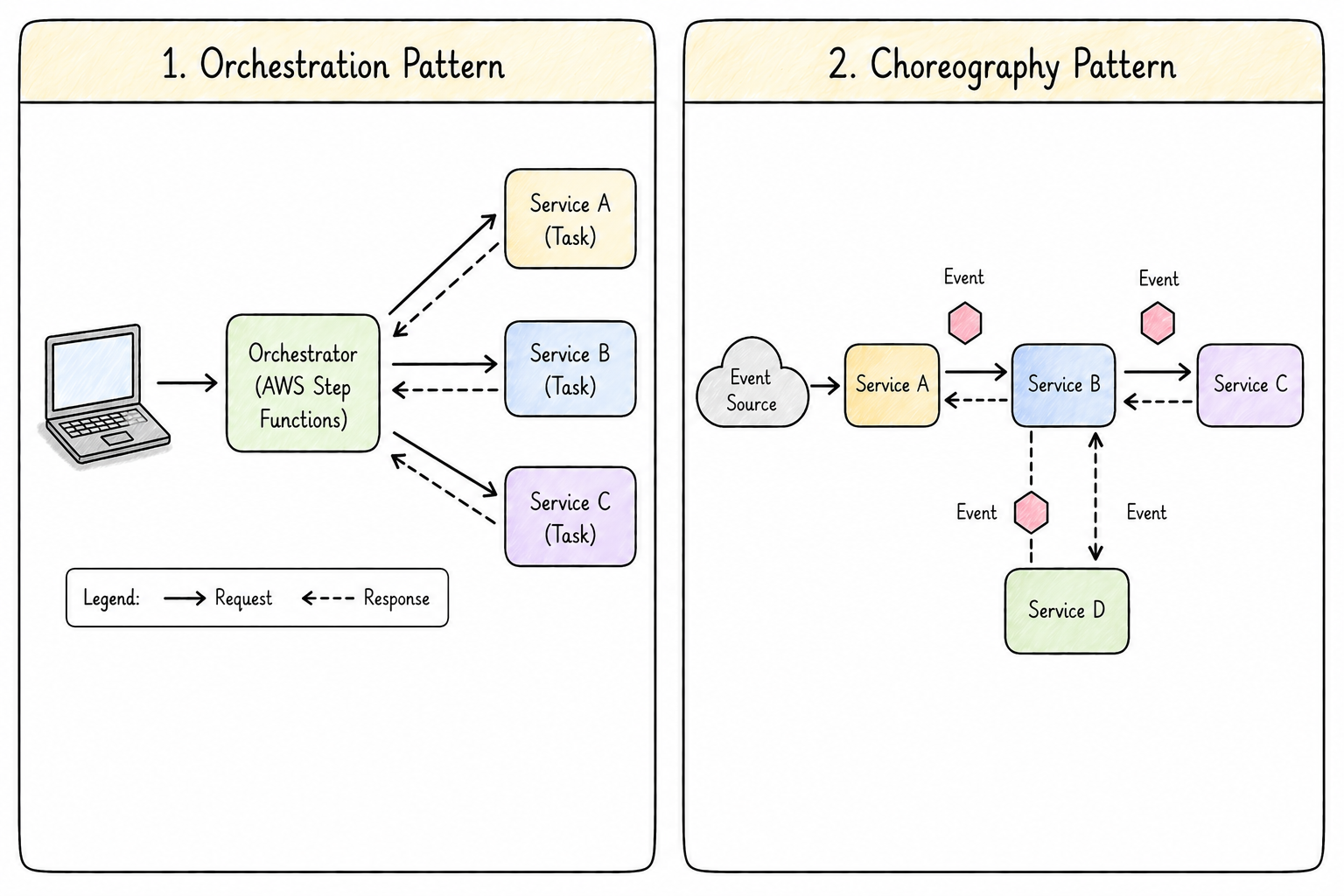
Orchestration
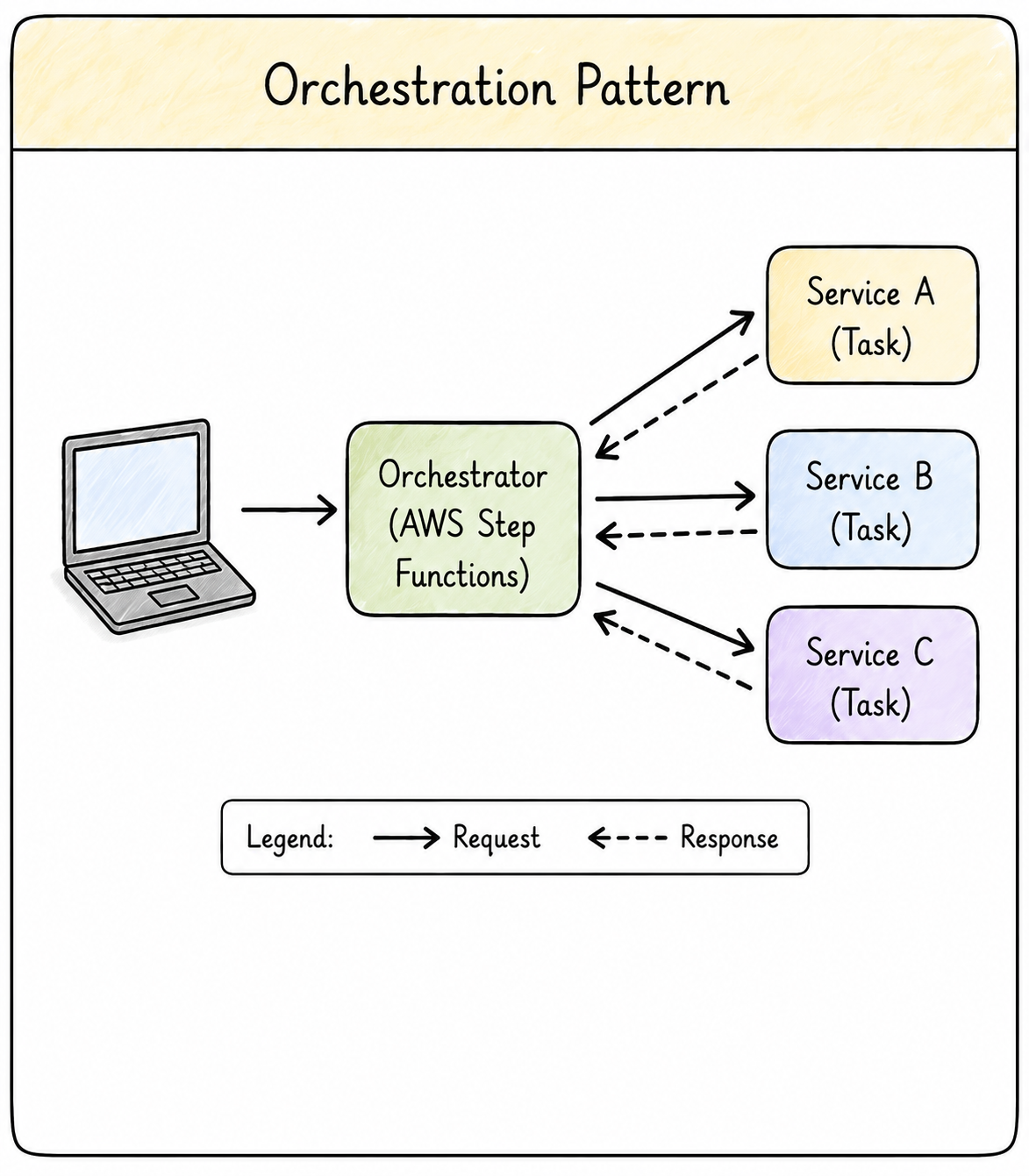
Orchestration
Choreography
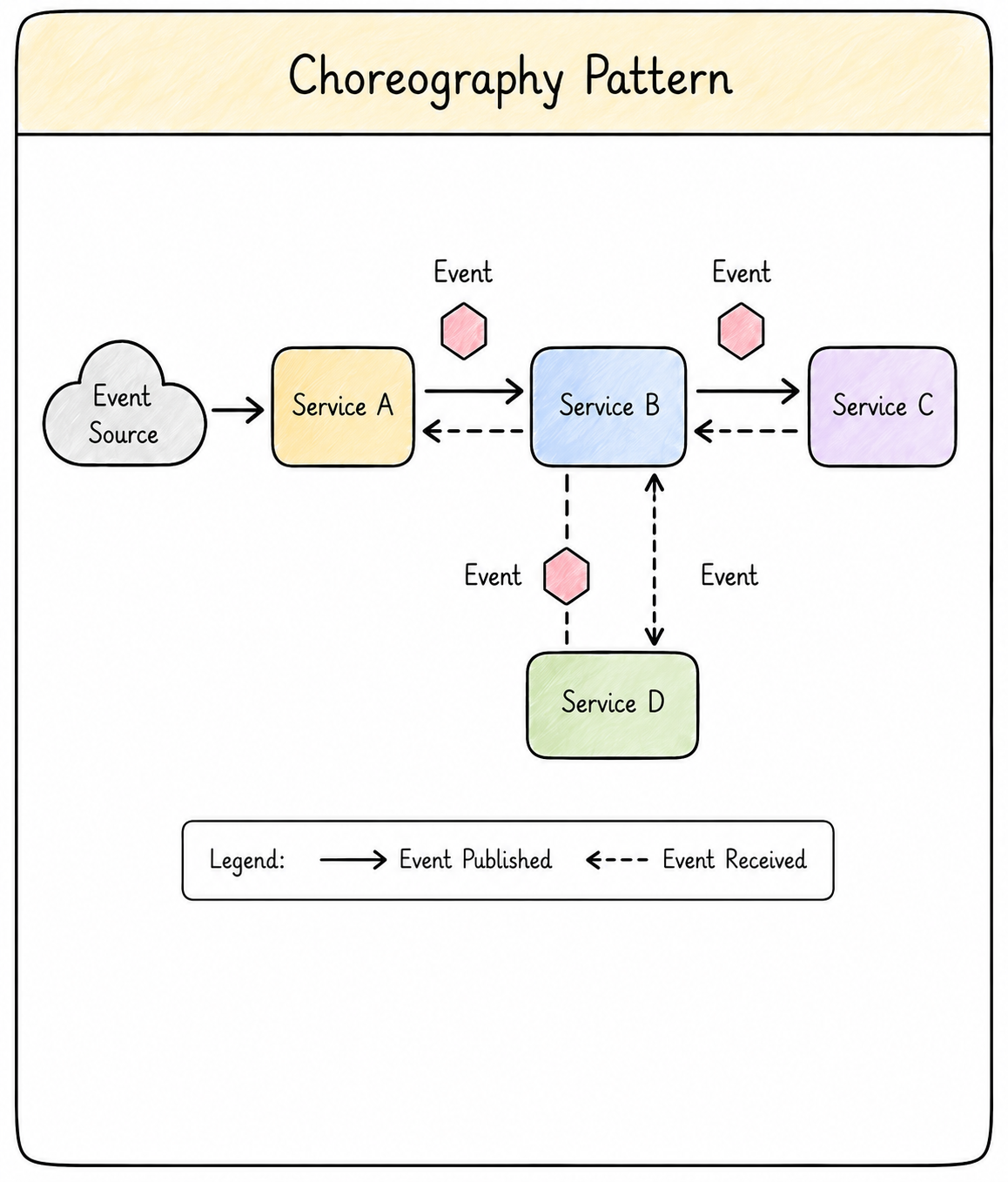
Choreography
Event-driven architecture
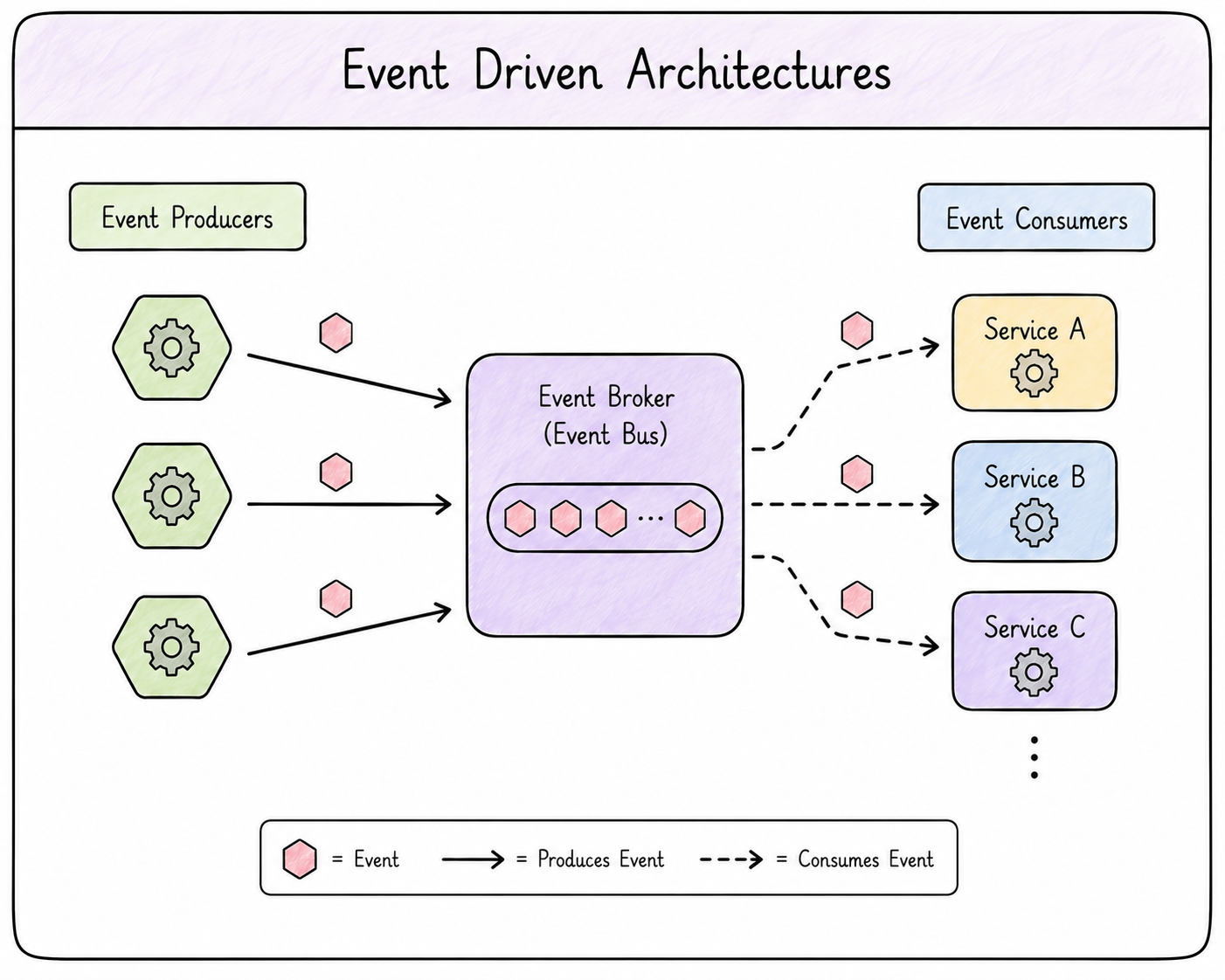
Event-driven architecture
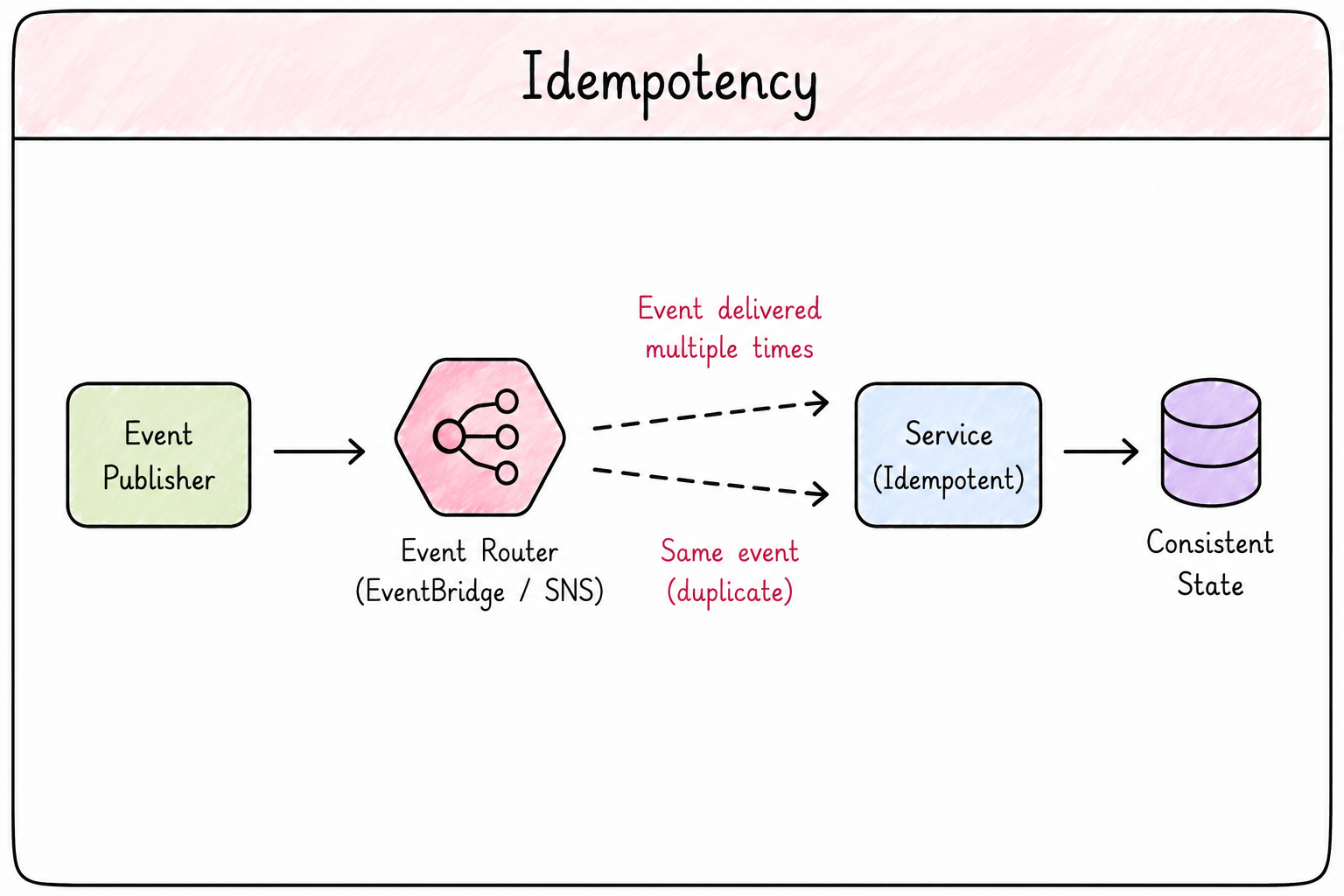
Idempotency
Dead letter queues
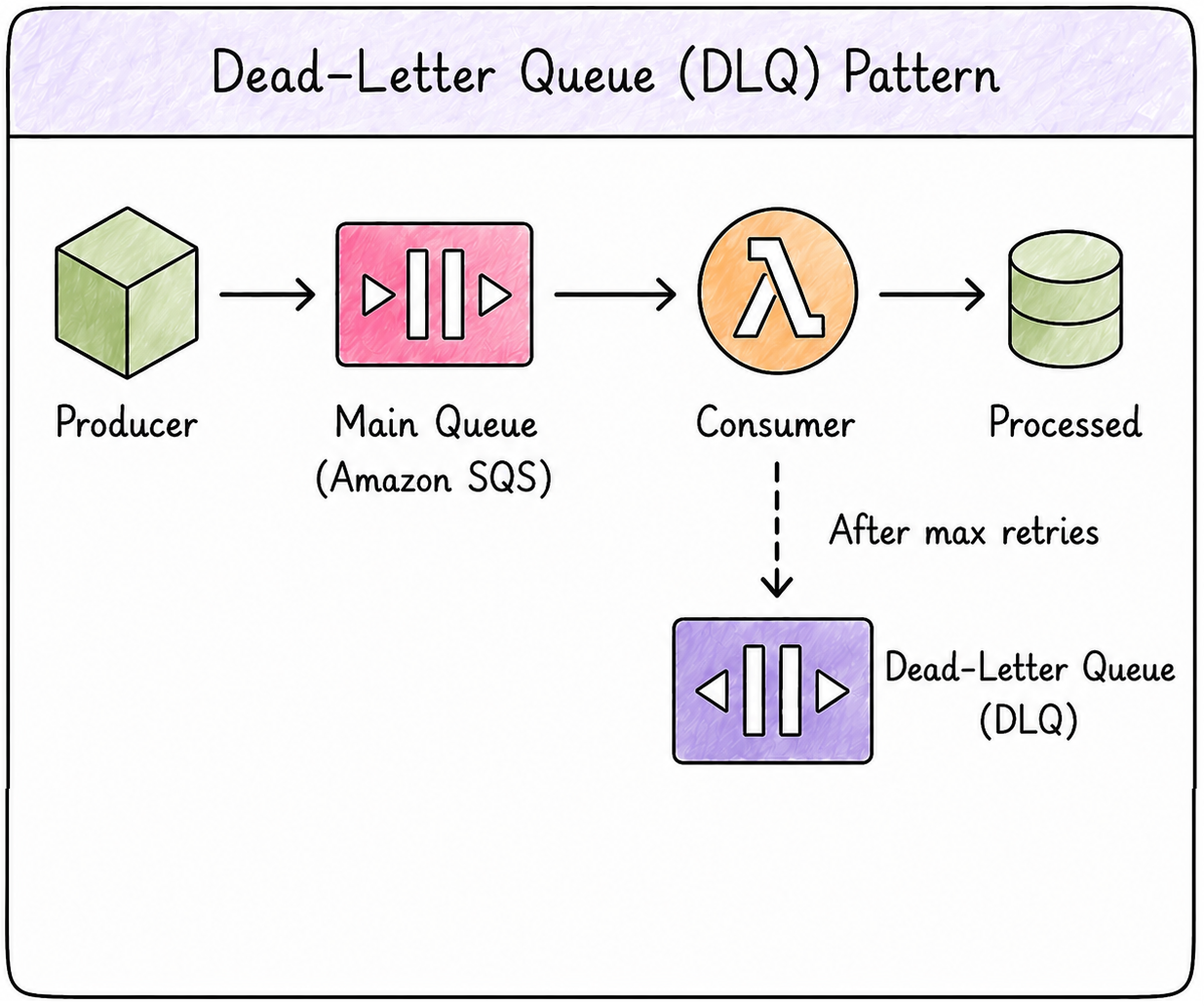
Dead letter queues
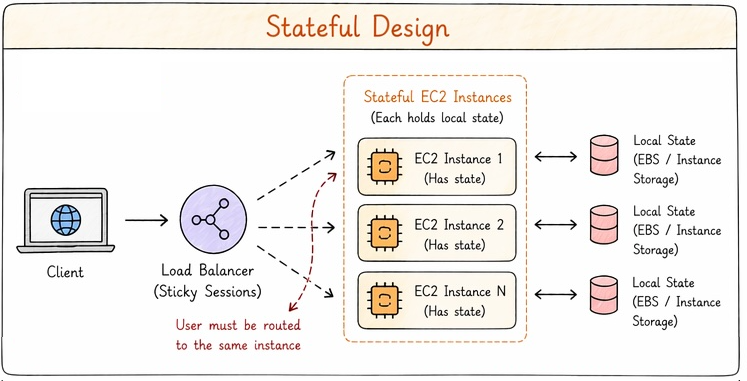
Managing state
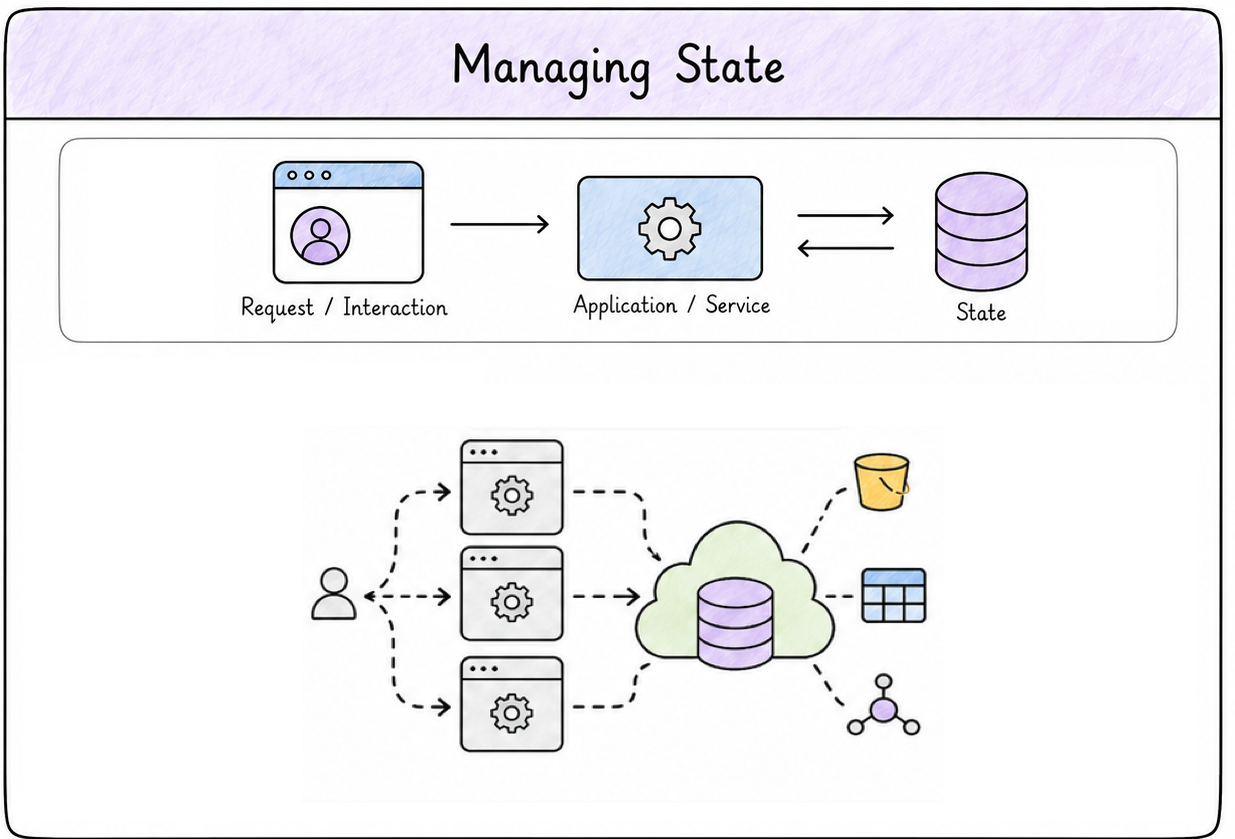
Managing state
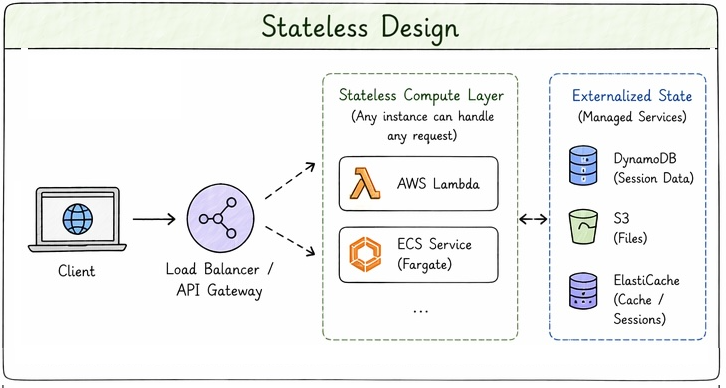
Stateful
Stateless