Optimization and query plans
Scaling and Optimizing Data Pipelines with Polars

Liam Brannigan
Data Scientist & Polars Contributor
Introducing query optimization
Introducing query optimization
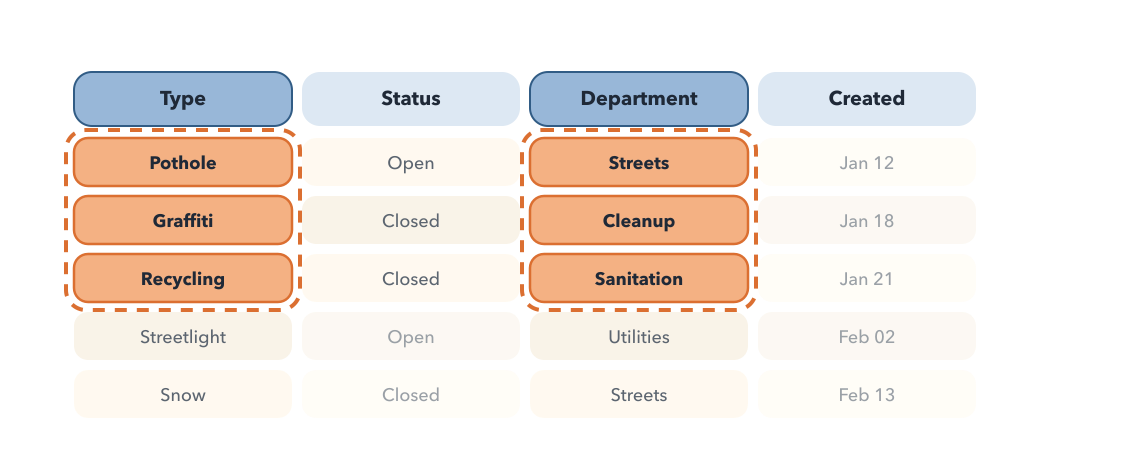
Introducing query optimization
Introducing query optimization
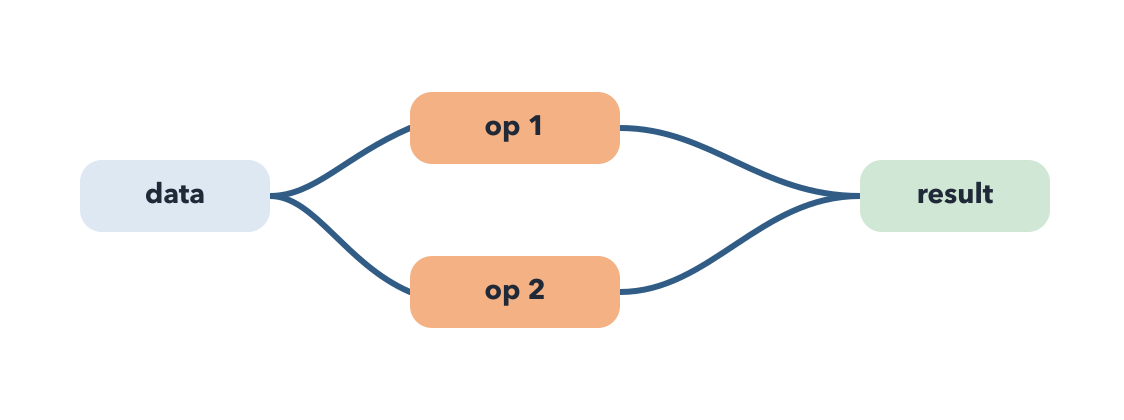
Introducing query optimization
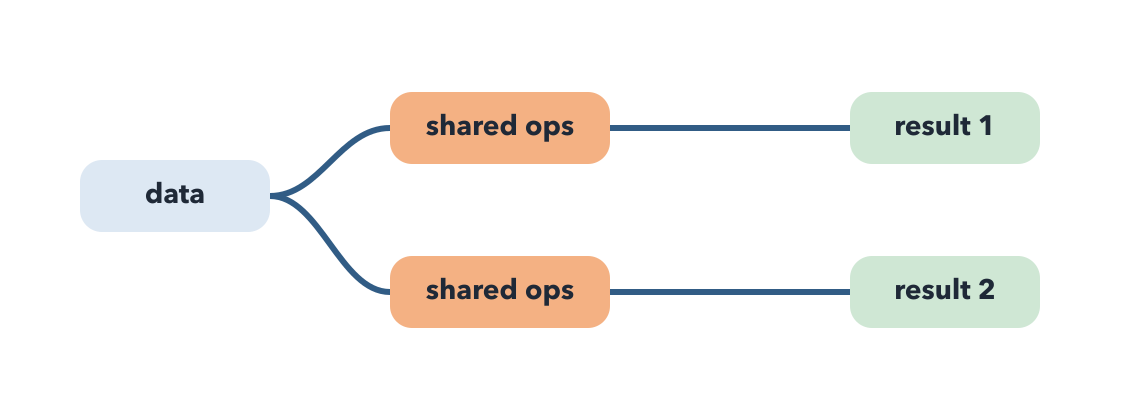
Introducing query optimization
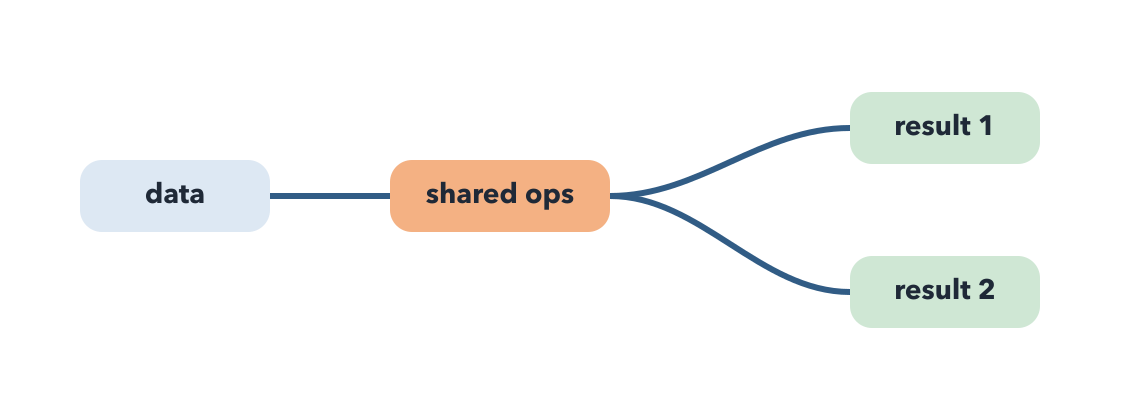
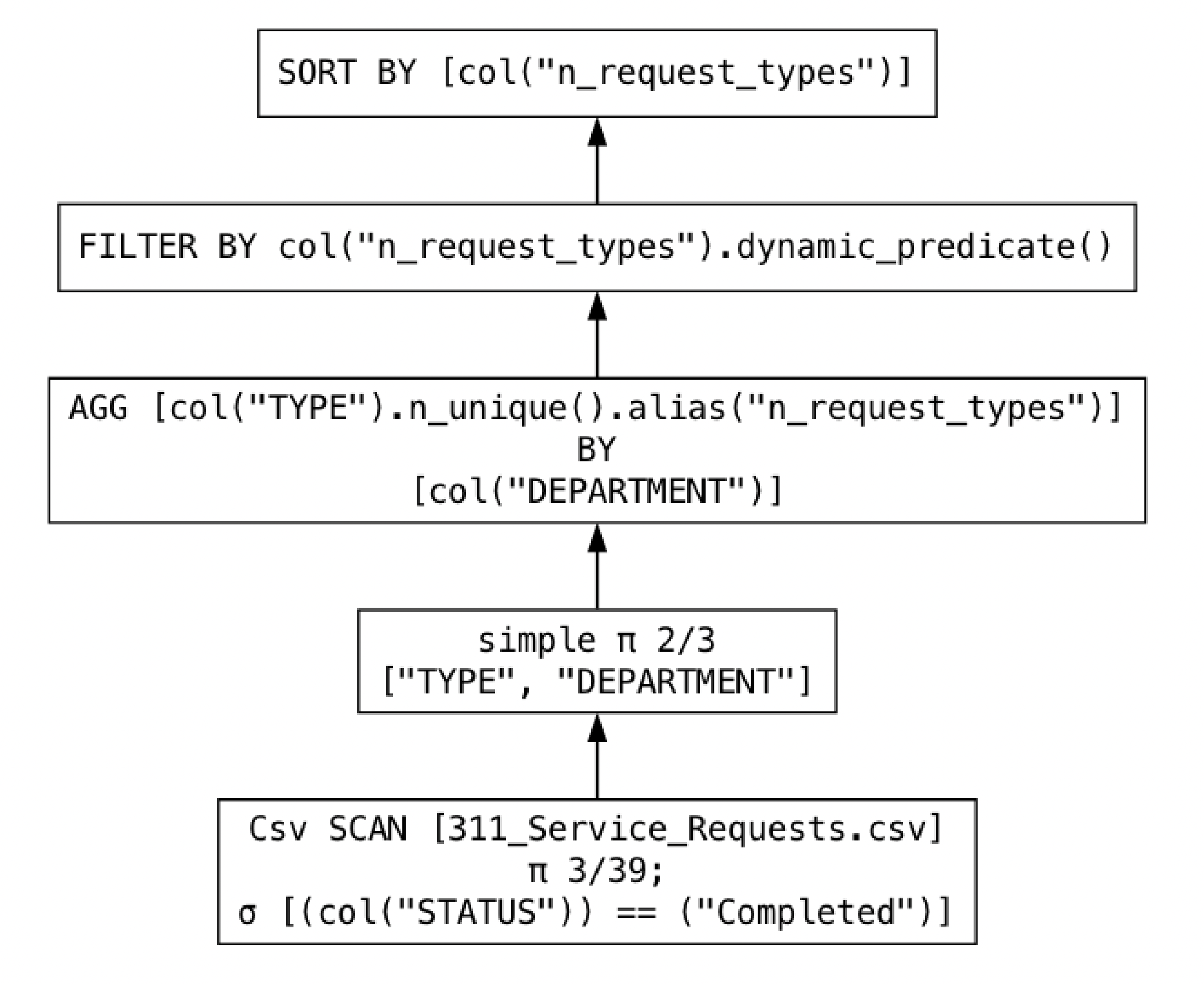
Optimized plan as a graph
print(department_request_types.show_graph())