Working with Databases
Scaling and Optimizing Data Pipelines with Polars

Liam Brannigan
Data Scientist & Polars Contributor
Querying a database from Polars
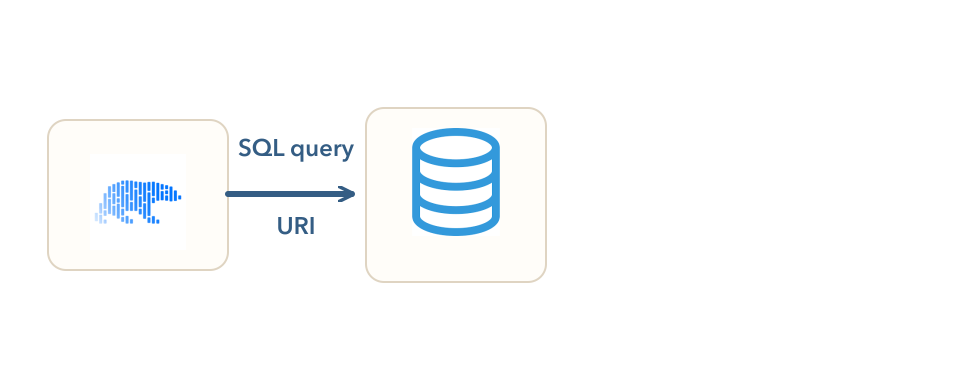
Querying a database from Polars
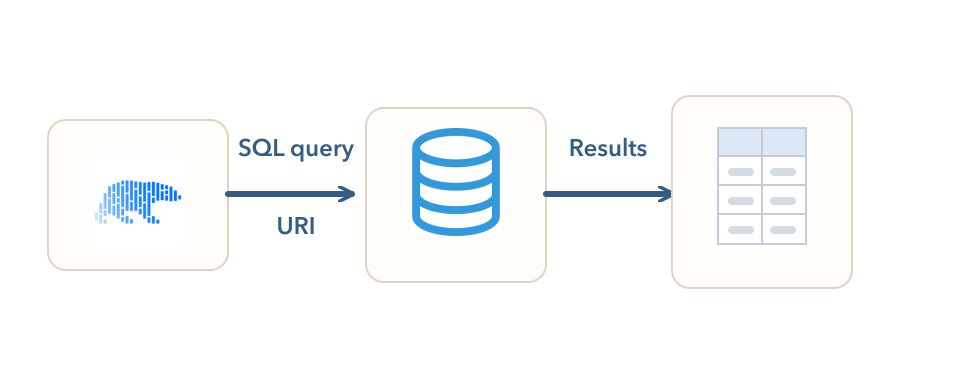
Databases Polars can query
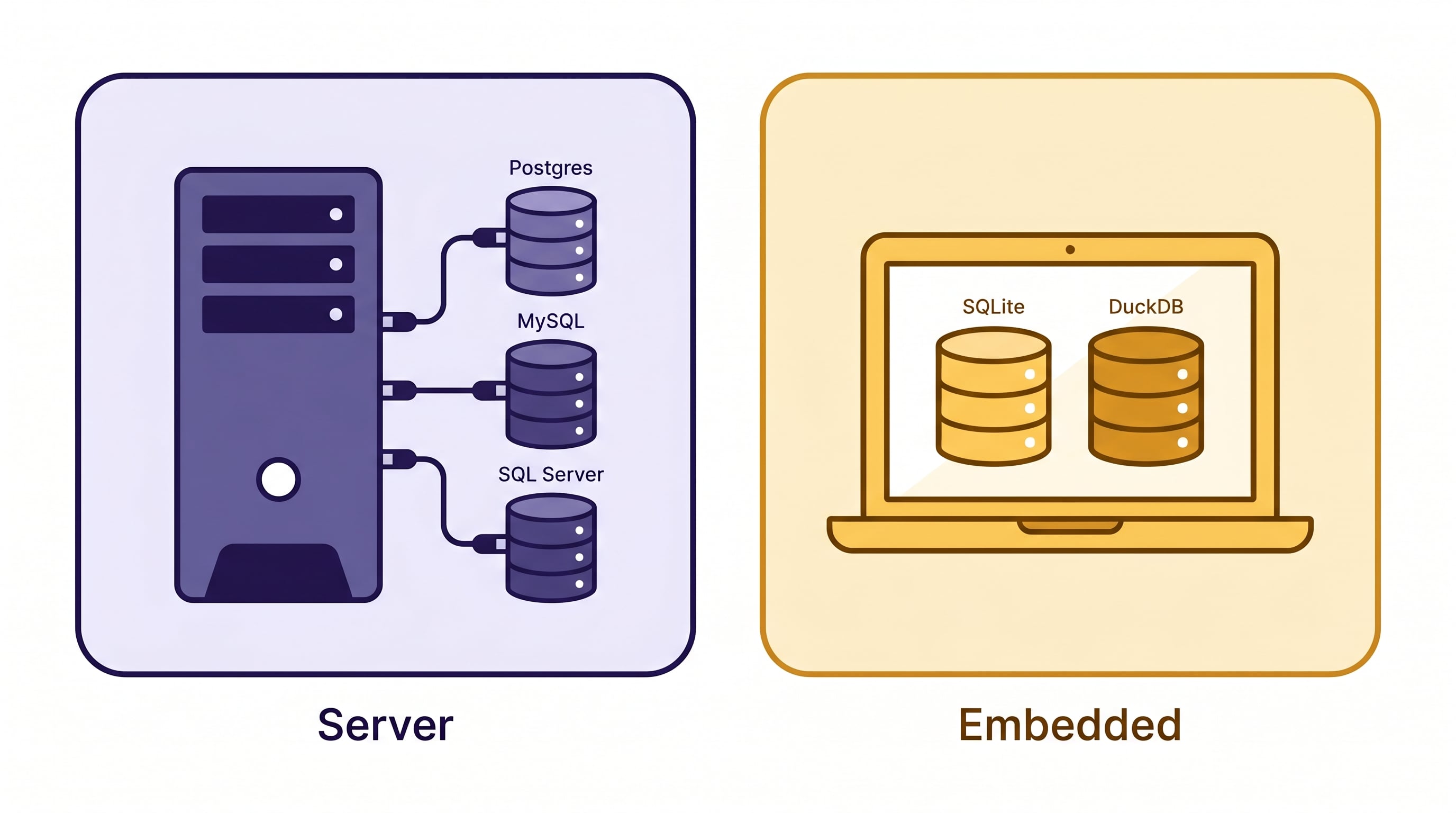
- Embedded → runs locally, no server
- DuckDB → analytical database

