Working with Parquet files
Scaling and Optimizing Data Pipelines with Polars

Liam Brannigan
Data Scientist & Polars Contributor
File storage formats
CSV Format
Parquet Format
CSV vs Parquet

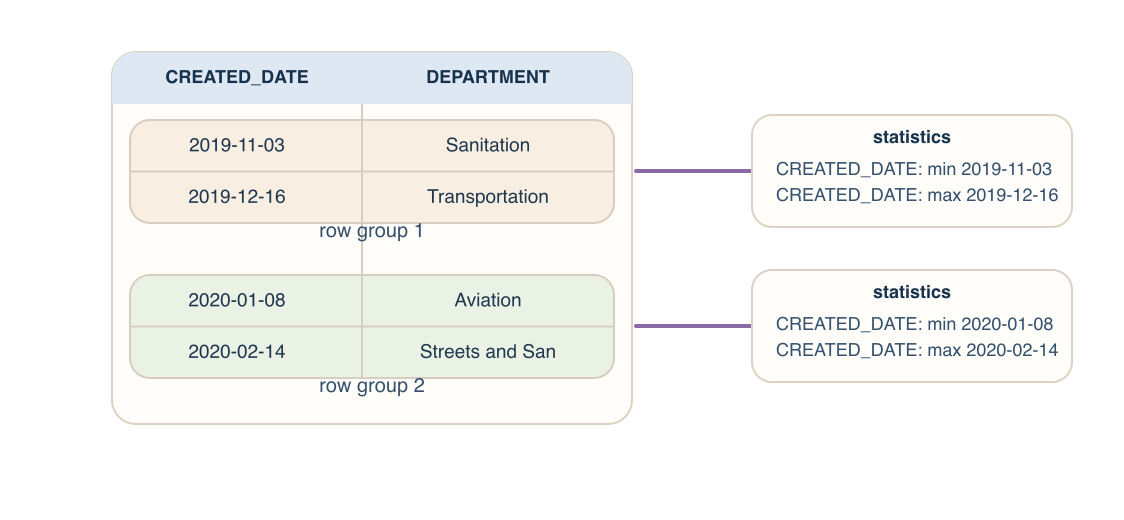
Parquet row groups
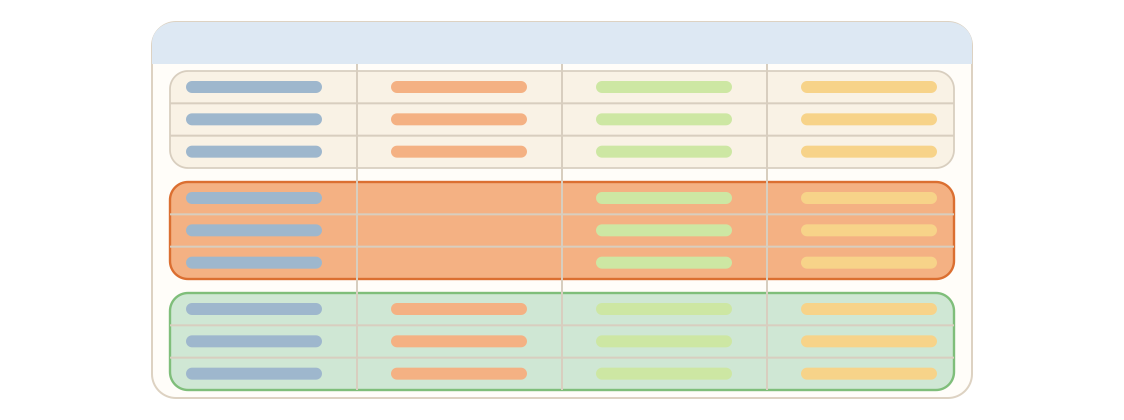
Parquet row groups

Parquet row groups